Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。
「Intel Arc Pro B60をテスト」の記事のコメント欄で「vLLMをOpenManusで動かしてAIエージェントにしてはどうか?」というアイデアを頂いたので、試してみようと思いました。
情報ありがとうございます!!
vLLMはLinux環境のみ公式対応とのことです。
Windowsで使う場合「WSL2」とか必要になると思います。
結論から言うと、Intel ArcでvLLMとOpenManusを連携させることには成功しました(少々問題がありましたが)。
ひとつの記事にまとめるととても長くなってしまうので、今回の記事ではvLLMの動作だけやります。
ただ、vLLMもOpenManusも触って4日くらいしか経っていないので、まだまだわからないことだらけです。
とりあえず、それらが「Intel Arc Pro B60での動作に成功した」といったところまでの記事です。
vLLMをインストールする
こちらのgithubのページにArcでのインストール方法がかかれています。

コメントでは「gpt-oss-20bでの動作がおもしろそう」ということだったので、こちらのモデルが動作する環境が必要です。
自分のPCのpython環境にインストールすることもできます。
が、2026/1/24時点での最新のブランチからビルドした場合、gpt-ossはチャットできる状態ではありませんでした。
ですので、Dockerを使用してセットアップする方法を使います。これならgpt-ossともチャットすることができました。
追記(2026/2/21)
メインブランチからgpt-oss-20bを動かすことに成功しました。
こちらの記事で書いています。
ただ、現状はdockerを利用したほうがVRAMの管理が楽なので、以下の手順をオススメします。
#Dockerのインストール
sudo apt install docker.io
# Intel公式のvLLM Dockerイメージを使う
sudo docker pull intel/vllm:0.10.2-xpu
sudo docker run -t -d --shm-size 10g --net=host --ipc=host --privileged -v /dev/dri/by-path:/dev/dri/by-path --name=vllm-test --device /dev/dri:/dev/dri --entrypoint= intel/vllm:0.10.2-xpu /bin/bash
sudo docker exec -it vllm-test /bin/bash
vllm serve openai/gpt-oss-20b --dtype=bfloat16 --enforce-eager --port 8000 --host 0.0.0.0 --trust-remote-code --gpu-memory-util=0.9 --no-enable-prefix-caching --max-num-batched-tokens=8192 --disable-log-requests --max-model-len=16384 --block-size 64 -tp 1自分は「docker」を使うのも初めてです。
よくわかりませんが、claudeのopusと相談した結果このコマンドを使うことにしました。
dockerイメージは、もっと新しいものがあるかもしれませんがとりあえず「0.10.2」でいきます。

こちらのページから最新のdockerを調べることができるみたいですね。
最新版を使う場合は、
# 最新版を使う場合
sudo docker pull intel/vllm:latestとなるようです。
ちなみに「vllm serve openai/gpt-oss-20b –dtype=bfloat16 –enforce-eager –port 8000 –host 0.0.0.0 –trust-remote-code –gpu-memory-util=0.9 –no-enable-prefix-caching –max-num-batched-tokens=8192 –disable-log-requests –max-model-len=16384 –block-size 64 -tp 1」の部分ですが、最後の「-tp 1」はGPUの個数(今回はArc Pro B60の個数)のようで、ふたつ搭載されている場合は「-tp 2」とかになるようです。
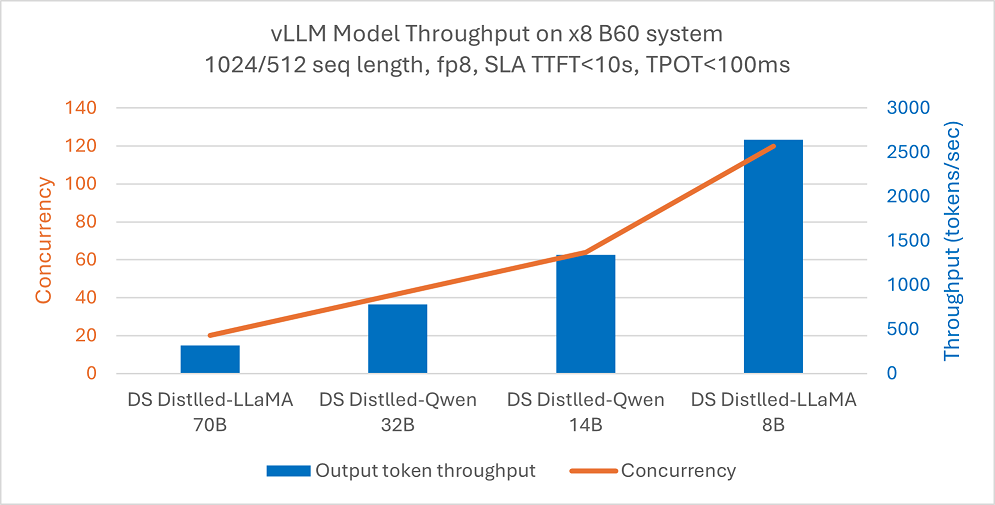
こちらのブログで記録が残っています。
#コンテナ内に移動
sudo docker exec -it vllm-test bash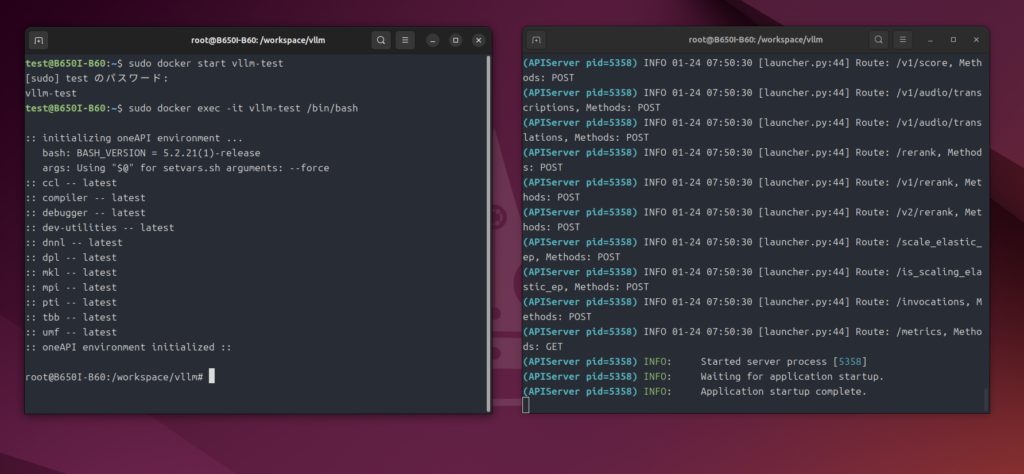
#GPT-OSS-20Bを16並列でベンチマーク
vllm bench serve \
--backend vllm \
--base-url http://localhost:8000 \
--model openai/gpt-oss-20b \
--dataset-name random \
--random-input-len 128 \
--random-output-len 128 \
--num-prompts 64 \
--request-rate 16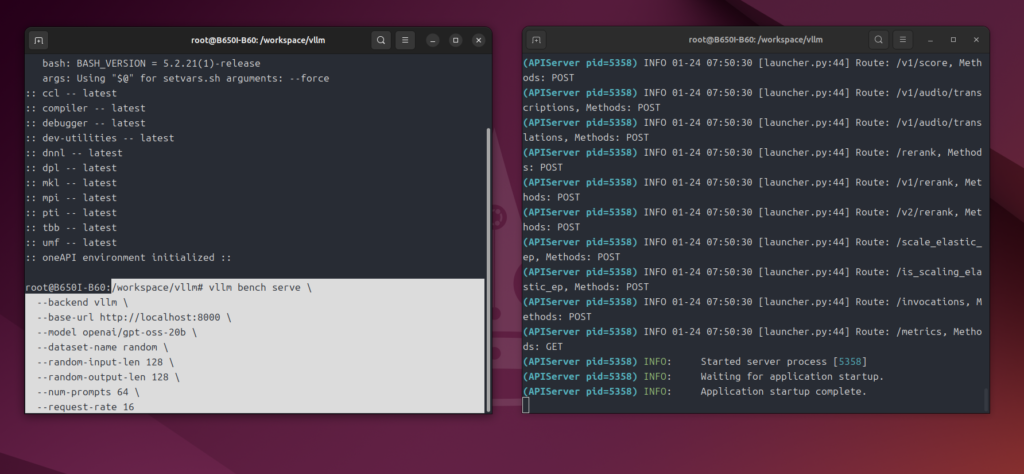
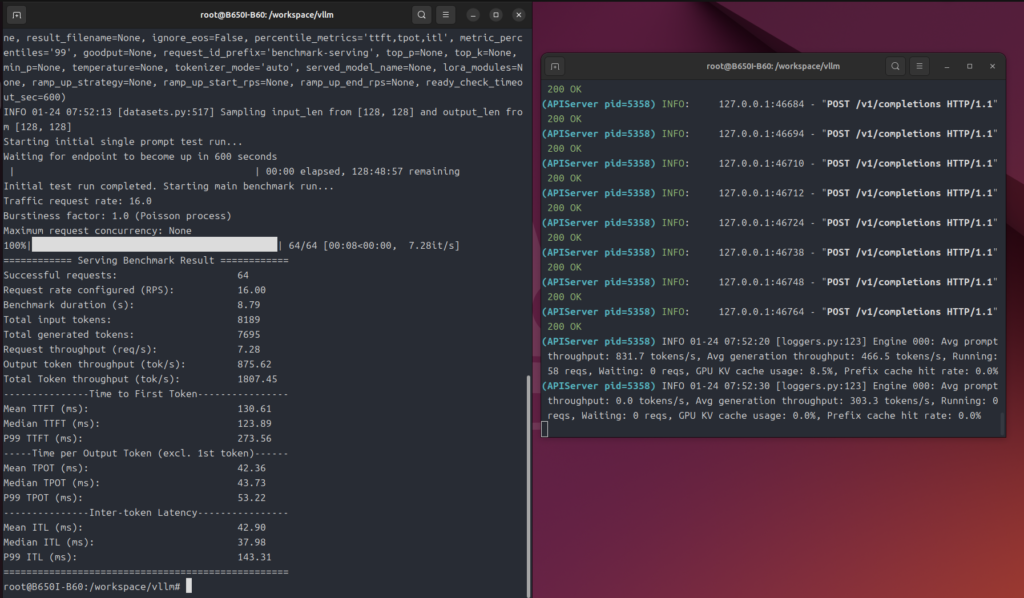
あまり実感がわかないので、わかりやすい方法でテスト
そんなに凄いなら、ふつうにチャットしててもきっと凄いでしょ?
ということで、vLLMで「gpt-oss-20b」を動かして、実際にチャットしてみます。
先程dockerコンテナは用意したので、それを利用します。
まずは皆さんのPCがどのような状態かわからないので、
sudo docker ps -a --filter "name=vllm-test"で、コンテナの状態を確認します。
#出力例
CONTAINER ID IMAGE COMMAND STATUS
abc123def456 intel/vllm:0.10.2-xpu /bin/bash Up 2 hours # 起動中
abc123def456 intel/vllm:0.10.2-xpu /bin/bash Exited (0) 1 min # 停止中上のような表示でコンテナの状態がわかると思います。
もし停止中なら
#停止していたらコンテナを起動
sudo docker start vllm-testで起動します。
さて、ここからがさっきと操作が違うのですが、今回のチャット環境はgradioを使いますので、コンテナ内にgradioをインストールします。
#dockerコンテナ内にgradioをインストール
sudo docker exec -it vllm-test pip install gradio
#確認方法
sudo docker exec -it vllm-test pip list | grep gradio次に、チャットをする環境をClaudeが作ってくれました。以下のpythonスクリプトがそれです。
import gradio as gr
import time
from openai import OpenAI
# ここを実際のモデル名に変更
MODEL_NAME = "openai/gpt-oss-20b"
client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy")
def chat(message, history):
start = time.time()
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[{"role": "user", "content": message}],
stream=True,
stream_options={"include_usage": True}
)
reply = ""
tokens = 0
for chunk in response:
if chunk.usage:
tokens = chunk.usage.completion_tokens
if chunk.choices and chunk.choices[0].delta.content:
reply += chunk.choices[0].delta.content
elapsed = time.time() - start
tps = tokens / elapsed if tokens > 0 else 0
if tokens > 0:
yield f"{reply}\n\n---\n📊 {tokens} tokens in {elapsed:.2f}s ({tps:.1f} tok/s)"
else:
yield reply
elapsed = time.time() - start
tps = tokens / elapsed if tokens > 0 else 0
yield f"{reply}\n\n---\n📊 {tokens} tokens in {elapsed:.2f}s ({tps:.1f} tok/s)"
# カスタムCSSでチャットエリアを広げる
custom_css = """
.chatbot {
height: 70vh !important;
max-height: 800px !important;
}
"""
with gr.Blocks() as demo:
gr.ChatInterface(
chat,
title="vLLM Chat",
chatbot=gr.Chatbot(height=600)
)
demo.launch(css=custom_css)これを「chat.py」と名付けてpythonファイルにします。
みなさんのPCの環境がわからないので、一様に操作できるよう指定した場所に「chat.py」を移動します。
mkdir -p ~/install/vLLM
#以下は「chat.py」のあるディレクトリで実行してください。
cp ./chat.py ~/install/vLLM/意味がわかるなら、手動で操作しても大丈夫です。
次にコンテナ内のワークスペースに「chat.py」をコピーします。
#コンテナ内にファイルをコピー
sudo docker cp $HOME/install/vLLM/chat.py vllm-test:/workspace/chat.py
#確認方法
sudo docker exec -it vllm-test ls -lh /workspace/そしてコンテナ内に移動します。
#コンテナ内に移動
sudo docker exec -it vllm-test bashでは、実行してみましょう。
#実行
python /workspace/chat.py 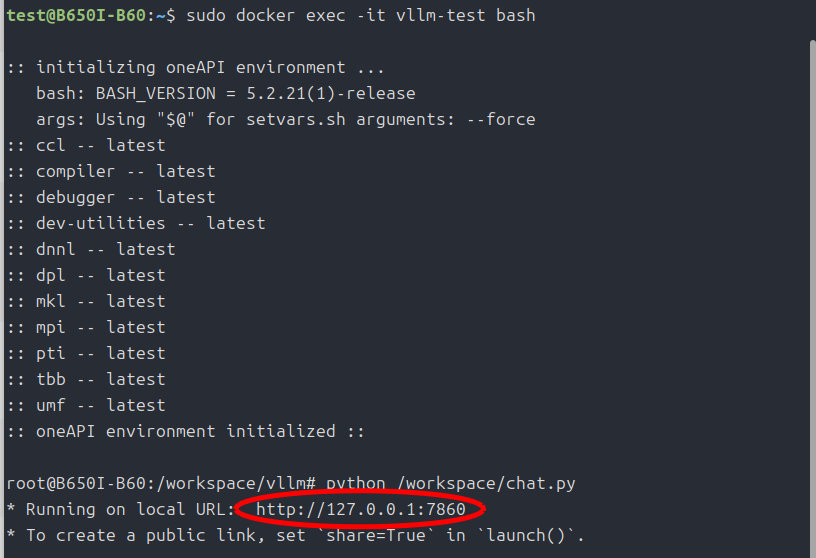
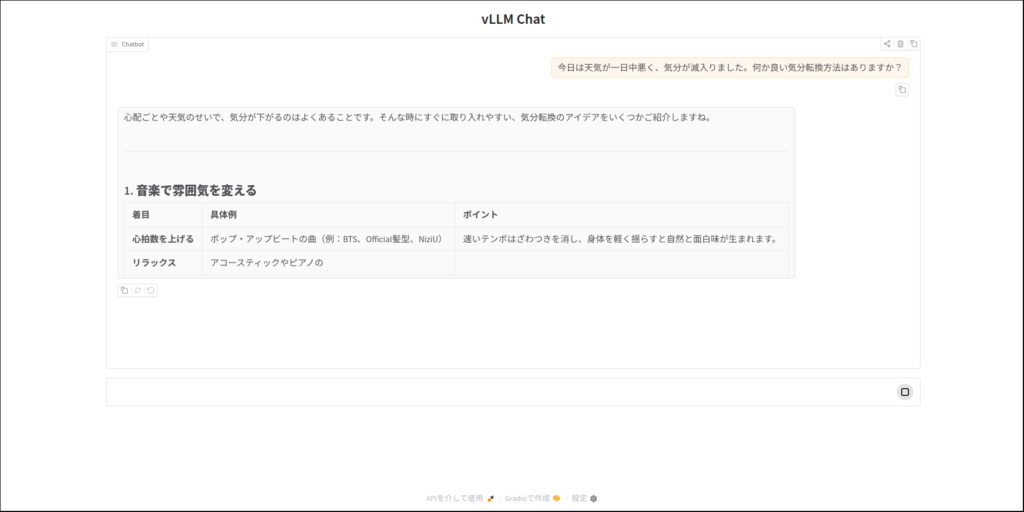
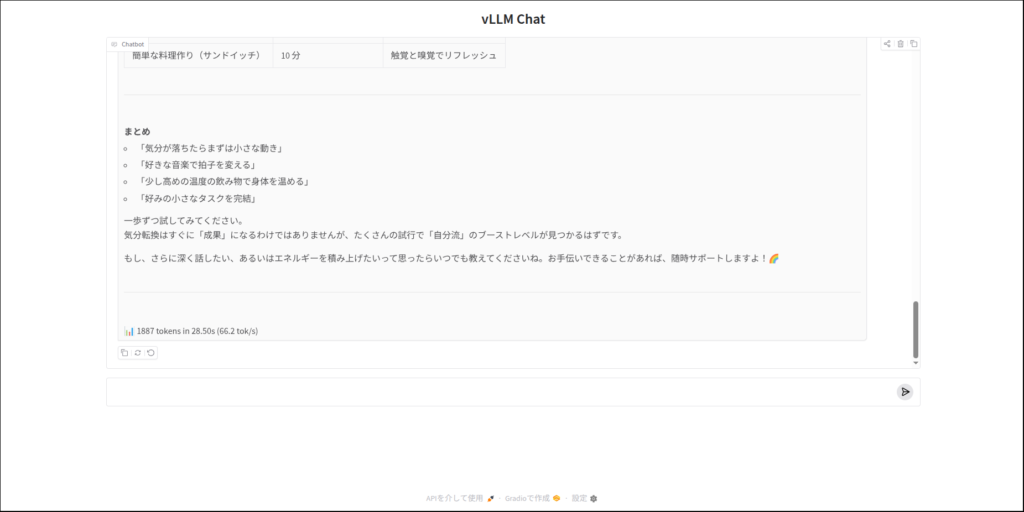
"偏りのないコインを表が出るまで投げ続け、表が出たときに、賞金をもらえるゲームがあるとする。もらえる賞金は、1回目に表が出たら1円、1回目は裏が出て2回目に表が出たら倍の2円、2回目まで裏が出ていて3回目に初めて表が出たらそのまた倍の4円、3回目まで 裏が出ていて4回目に初めて表が出たらそのまた倍の8円、というふうに倍々で増える賞金がもらえるというゲームである。ここで、このゲームには参加費(=賭け金)が必要であるとしたら、参加費の金額が何円までなら払っても損ではないと言えるだろうか。"この問題を解いてください。では、いつものサンクトペテルスブルクのパラドックスいきましょう。
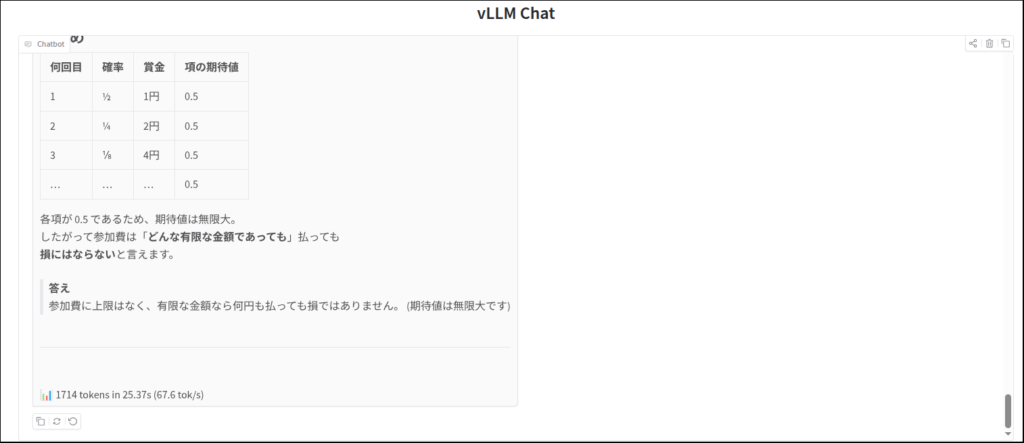
最後に
ふつうにチャットした方が自分にはその性能がわかりやすかったです。
次の記事では「OpenManus」を使ってAIエージェントになってもらいますね。
まぁ、まだあまりよくわかっていないので一応動きましたよ程度の報告ですが・・・。
Arc Pro B60の実力はみなさんが確かめてみてください。
今回は以上です。
追記(2026/5/12)
恥ずかしながらつい最近知ったのですが、
「vLLMのアーキテクチャでは、この「AWQ」や「GPTQ」といったGPUでの並列処理に特化した量子化フォーマットが広く利用されています。」
と、Geminiに教えてもらいました。
今はvLLMを使っていないので確かめていませんが、参考にどうぞ。
相変わらず表記がおかしいですが、「Arc Pro B60」らしきものがAmazonにあるみたいです。


価格.comから調べるとわかると思いますが、「ECJOY!」というところで購入できるみたいです。
ただしパッシブクーラー(ファンなしモデル)です。
わかる人なら、狙ってみると良いかもしれません。

コメント