以前、「Intel ArcでvLLMを動かそう(Dockerで導入編)」という記事でvLLMをDockerで導入して動かしました。
今回は「本家vLLMのメインブランチ」を「vllm-xpu-kernels」利用して動かす手順について記事にします。
ただ、vLLMをIntel Arcで動かすだけなら、Dockerを使う方法の方がパフォーマンスも出やすくVRAM管理もしやすいので、今回の記事は「こんなことも出来ました」的な道楽になります。
それではやっていきましょう。
おおまかな手順
使用するPCは「Ubuntu 24.04.4 LTS」と「Intel Arc GPU」になります。
- グラフィックスドライバとoneAPIベースツールキットを導入
- uvの導入
- 「vllm-xpu-kernels」をビルド、whlファイルを作成する
- 「本家vLLM」をビルド
以上になります。
「vllm-xpu-kernels」をビルド
実は「本家vLLM」のrequirements.txtの中に「vllm-xpu-kernels」は(ちょっと古いですが)含まれているので、ビルドしなくても「vLLM」自体は動作します。
ですが、今回の記事は「最新のvLLM」を「最新のvllm-xpu-kernels」で動かそうと思っているので、あえてビルドします。
では、「vllm-xpu-kernels」をダウンロードします。
#!/bin/bash
#ホームディレクトリに「installフォルダ」を作り、その中に「vLLM_mainフォルダ」を作ります。
mkdir -p ~/install/vLLM_main
cd ~/install/vLLM_main
#vllm-xpu-kernelsをダウンロード
git clone https://github.com/vllm-project/vllm-xpu-kernels.gitここから、ビルドするデバイスの対象を絞らないといけません。
対象をしぼらないと、ビルドに時間が掛かりすぎてしまうからです。
何気に「bmg-g31-a0」の記述がありますね。
Intel Arc B70でしたか、登場に期待します。
買えませんが。
話を戻しますが、デバイスの対象を絞る方法は「CMakeLists.txt」を書き換えることでした。
#CMakeLists.txtの変更箇所(1)
set(SYCL_SUPPORTED_ARCHS "intel_gpu_pvc;intel_gpu_bmg_g21;intel_gpu_bmg_g31")
この行を以下に書き換え
set(SYCL_SUPPORTED_ARCHS "intel_gpu_bmg_g21")# CMakeLists.txtの変更箇所(2)
set(AOT_DEVICES "pvc,bmg-g21-a0,bmg-g31-a0")
set(XE2_AOT_DEVICES "pvc,bmg-g21-a0,bmg-g31-a0")
以下に書き換え
# Arc B60用のみ残す
set(AOT_DEVICES "bmg-g21-a0")
set(XE2_AOT_DEVICES "bmg-g21-a0")この2箇所です。
この変更を加えた後、以下の手順に進みます。
cd ~/install/vLLM_main/vllm-xpu-kernels
#vllm-xpu-kernelsをビルドするために「oneAPIベースツールキット」を使えるようにします。
source /opt/intel/oneapi/setvars.sh
#仮想環境を用意します。
uv venv --python 3.12 --seed
source .venv/bin/activate
#vllm-xpu-kernelsをビルドするための依存環境をインストール。
pip install -r requirements.txt
#vllm-xpu-kernelsをビルドし、「distフォルダ」にwhlファイルを出力する。
export MAX_JOBS=8
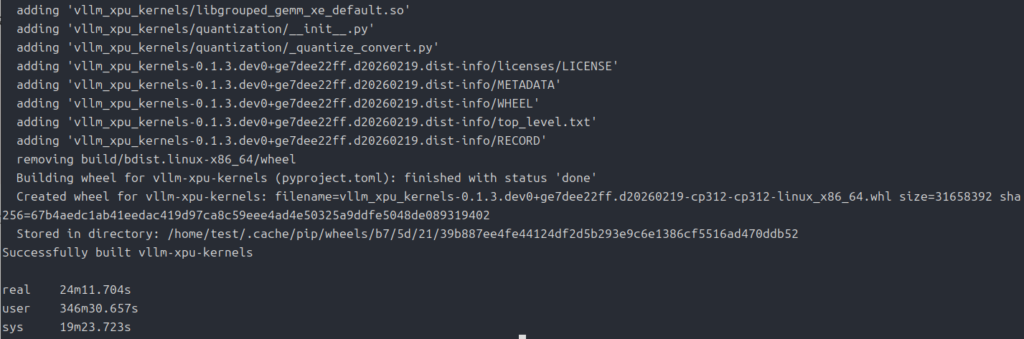
time pip wheel -v --no-build-isolation --wheel-dir=dist . 2>&1 | tee vllm-xpu-build.logビルドする直前に「export MAX_JOBS=8」とありますが、これはビルドプロセスを並列化する数になります。
どのような数値にするかはメインメモリの容量によりますが、あまり大きな数値にすると、ひとつのプロセスに割り当てるメモリ量によってはクラッシュしてしまうので、無難に「8」を割り当てています。
余裕があるようなら、もう少し大きな数値にしましょう。
ちなみに「16」を割り当てた場合、
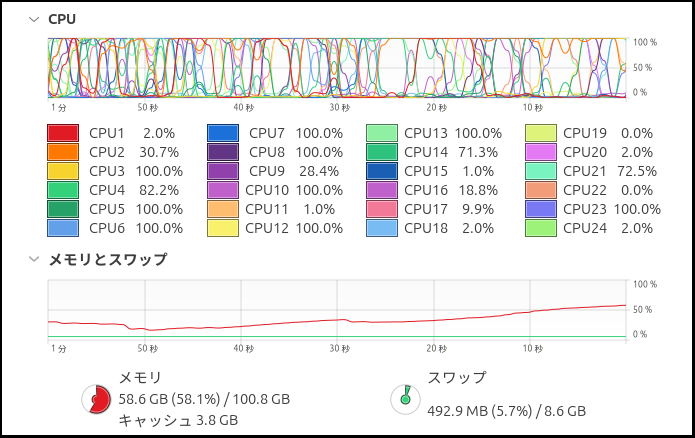
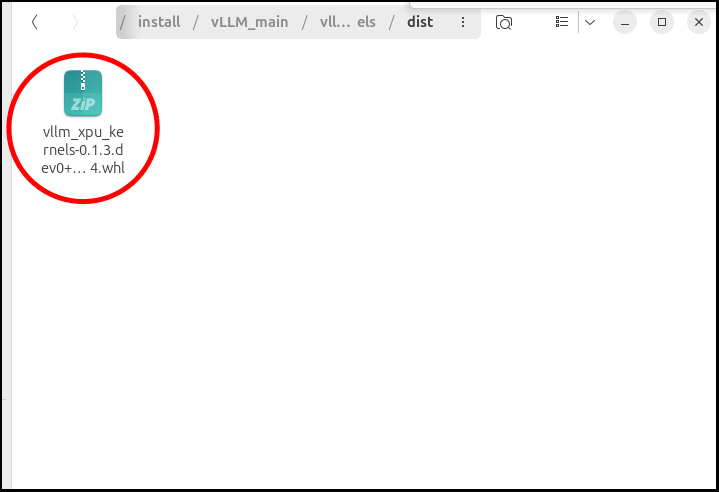
このファイルは後で使うので、ファイル名を調べておいて下さい。
ちなみに自分の時は「vllm_xpu_kernels-0.1.3.dev0+ge7dee22ff.d20260219-cp312-cp312-linux_x86_64.whl」でした。
ファイル自体はそのままにしておいて大丈夫です。
「本家vLLM」をビルド
では、今度は「vLLM」をビルドしていきましょう。
cd ~/install/vLLM_main
# vLLMのダウンロード
git clone https://github.com/vllm-project/vllm.git
cd vllm
#仮想環境を構築
uv venv --python 3.12 --seed
source .venv/bin/activate
#依存環境をインストール
pip install -v -r requirements/xpu.txt
# 先程作った「whlファイル」を指定してインストール
pip install ../vllm-xpu-kernels/dist/vllm_xpu_kernels-*.whl
# 6. vLLMをIntel GPU用にビルド
export VLLM_TARGET_DEVICE=xpu
pip install --no-build-isolation --no-deps .「vllm_xpu_kernels-*.whl」の部分は先程作った「whlファイル」の名前に書き換えます。
これはビルドした日にちによってファイル名が違ってきますので、各自で先程のファイル名をコピペしてください。
出来上がったファイルは一つしかないので、このままのスクリプトでも動くとは思いますが。
実行してみましょう
ターミナルはビルドし終わったそのままの状態だと思いますので、そのまま起動コマンドを打ち込んでいきましょう。
vllm serve Qwen/Qwen3-8B --dtype=auto --enforce-eager --port 8000 --host 0.0.0.0 --trust-remote-code --gpu-memory-util=0.3 --no-enable-prefix-caching --max-num-batched-tokens=4096 --disable-log-requests --max-model-len=4096 --block-size 64 -tp 1今回は、「Qwen3-8B」を使っています。
「–gpu-memory-util=0.3」としていますが、これ以上あげるとVRAMのオーバーフローでクラッシュしますので、かなり控えめに設定しています。
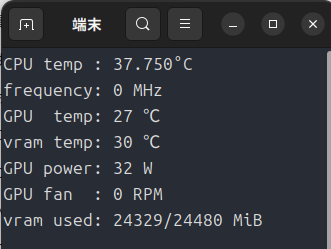
チャットしてみましょう
以前の記事で「chat.py」を作りましたが(Geminiが)、今回もそれを流用します。
import gradio as gr
import time
from openai import OpenAI
# ここを実際のモデル名に変更
#MODEL_NAME = "openai/gpt-oss-20b"
MODEL_NAME = "Qwen/Qwen3-8B"
client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy")
def chat(message, history):
start = time.time()
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[{"role": "user", "content": message}],
stream=True,
stream_options={"include_usage": True}
)
reply = ""
tokens = 0
for chunk in response:
if chunk.usage:
tokens = chunk.usage.completion_tokens
if chunk.choices and chunk.choices[0].delta.content:
reply += chunk.choices[0].delta.content
elapsed = time.time() - start
tps = tokens / elapsed if tokens > 0 else 0
if tokens > 0:
yield f"{reply}\n\n---\n📊 {tokens} tokens in {elapsed:.2f}s ({tps:.1f} tok/s)"
else:
yield reply
elapsed = time.time() - start
tps = tokens / elapsed if tokens > 0 else 0
yield f"{reply}\n\n---\n📊 {tokens} tokens in {elapsed:.2f}s ({tps:.1f} tok/s)"
# カスタムCSSでチャットエリアを広げる
custom_css = """
.chatbot {
height: 70vh !important;
max-height: 800px !important;
}
"""
with gr.Blocks() as demo:
gr.ChatInterface(
chat,
title="vLLM Chat",
chatbot=gr.Chatbot(height=600)
)
demo.launch(css=custom_css)MODEL_NAME = “openai/gpt-oss-20b”を、MODEL_NAME = “Qwen/Qwen3-8B”に書き換えてます。
もし、別のモデルを使う場合は書き換えてください。
そして、このスクリプトを「chat.py」と名付けて、適当なフォルダに配置します。
次に、同じフォルダ内でターミナルを開き、
uv venv --python 3.12 --seed
source .venv/bin/activate
pip install gradio openai
python ./chat.pyと実行します。

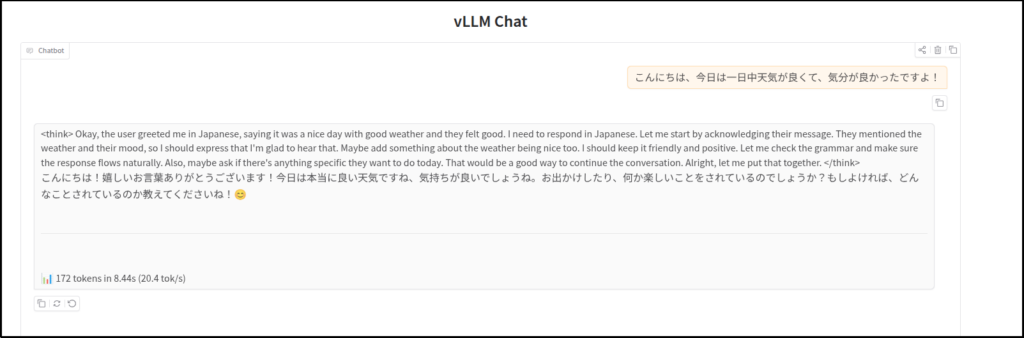
とりあえず、最新のvLLMと最新のvllm-xpu-kernelsを使ってチャットできることは確認しました。
今後、新しい機能が追加された時には、逸早く試すことができそうです。
ただ、Dockerを使う方がVRAM管理も楽なので、個人的にはそちらをオススメします。
このあたりは本家vLLMのソースをいじることで、対応できるのかもしれませんが、自分の力だとこれが精一杯です。
今後時間がとれたら、Geminiに教えてもらいながら勉強するかもしれません。
今回は以上です。
追記
モデルをgpt-oss-20bに変更した場合はそのままでは動かなかったので、動かす手順を書き留めておきます。
vllm-xpu-kernelsをビルドする前に、
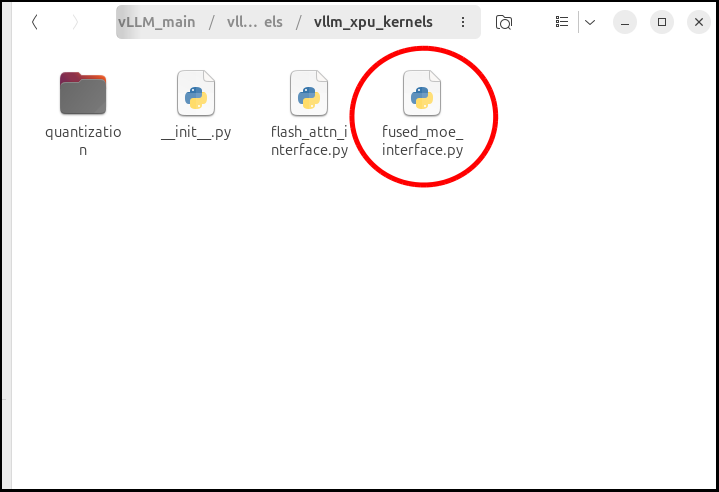
一番下の方に、
#修正前
if activation == "silu":
torch.ops._C.silu_and_mul(act_output, gemm1_output)
elif activation == "gelu":
torch.ops._C.gelu_and_mul(act_output, gemm1_output)
elif activation == "swigluoai":
torch.ops._C.swigluoai_and_mul(act_output, gemm1_output, 1.702, 7.0)
else:
raise ValueError(f"Unsupported FusedMoe activation: {activation}.")とありますところを、以下に書き換えます。
#修正後
# 入力を文字列化して小文字にする(これで "MoEActivation.SWIGLUOAI" も "swigluoai" も扱えます)
act_str = str(activation).lower()
if "silu" in act_str:
torch.ops._C.silu_and_mul(act_output, gemm1_output)
elif "gelu" in act_str:
torch.ops._C.gelu_and_mul(act_output, gemm1_output)
elif "swiglu" in act_str:
# swigluoai または swiglu が含まれていればこれを実行
torch.ops._C.swigluoai_and_mul(act_output, gemm1_output, 1.702, 7.0)
else:
raise ValueError(f"Unsupported FusedMoe activation: {activation}.")この作業の後、vllm-xpu-kernelsをビルドします。
以降は、この記事と同じ手順です。
vLLMの起動コマンドは、
vllm serve openai/gpt-oss-20b --dtype=bfloat16 --enforce-eager --port 8000 --host 0.0.0.0 --trust-remote-code --gpu-memory-util=0.3 --no-enable-prefix-caching --max-num-batched-tokens=4096 --disable-log-requests --max-model-len=4096 --block-size 64 -tp 1にしています。
Qwen3-8Bの時と同様に、「–gpu-memory-util=0.3」に設定しておかないとVRAMの関係でクラッシュしてしまいます。
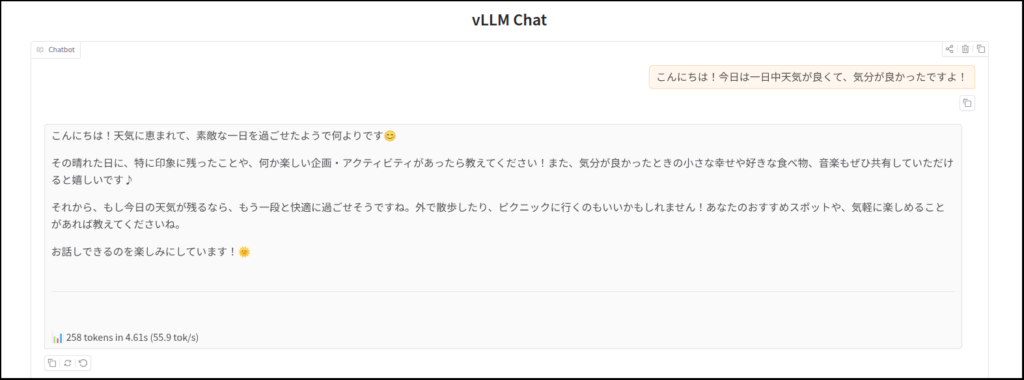
以上、追記でした。

コメント