Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。
昨日の記事でCUI版の記事を書きましたが、今回はGUIのgradio版です。
こちらは、はじめからいくらか別の言語にも対応しています。
インストール方法は以前とほぼ同じです。
では、やっていきましょう。
環境構築
ffmpegが必要になります。
こちらの記事を参考にインストールするか、面倒な人は
sudo apt install ffmpegでインストールしてください。
以下のスクリプトは前回と比べてもgradioを追加でインストールしているだけです。
#!/bin/bash
cd ~
mkdir -p install/insanely-fast-whisper
cd install/insanely-fast-whisper
uv venv --python 3.12 --seed
source .venv/bin/activate
#Intel Arcなのでtorch.xpuをインストール
#stable
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/xpu
#Radeonなら以下のコマンドのコメントアウトを消してください。
#pip install --pre torch torchvision --index-url https://download.pytorch.org/whl/nightly/rocm7.1
#「insanely-fast-whisper」を使うために必要なもの
uv pip install pydub tqdm sentencepiece sacremoses accelerate accelerate gradioメインスクリプト
以下のスクリプトを「translate_gradio.py」とでもつけて保存しましょう。
import gradio as gr
import torch
import sys
import subprocess
import gc
import shutil
import os
from pathlib import Path
from transformers import pipeline, AutoModelForCausalLM, AutoTokenizer
from pydub import AudioSegment
from pydub.silence import detect_nonsilent
# ---------------------------------------------------------
# 1. 共通ユーティリティ & GPU判定
# ---------------------------------------------------------
def get_device():
if torch.cuda.is_available():
return "cuda"
elif hasattr(torch, "xpu") and torch.xpu.is_available():
return "xpu"
else:
return "cpu"
def format_timestamp(seconds):
if seconds is None: return "00:00:00,000"
milliseconds = round(seconds * 1000.0)
hours = milliseconds // 3600000
milliseconds %= 3600000
minutes = milliseconds // 60000
milliseconds %= 60000
seconds = milliseconds // 1000
milliseconds %= 1000
return f"{hours:02d}:{minutes:02d}:{seconds:02d},{milliseconds:03d}"
def cleanup_memory():
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
elif hasattr(torch, "xpu") and torch.xpu.is_available():
torch.xpu.empty_cache()
# ---------------------------------------------------------
# 2. コア処理ロジック
# ---------------------------------------------------------
def slice_audio_by_silence(audio_path, min_silence_len, silence_thresh, keep_silence):
print(f" -> Loading audio & detecting silence... ({audio_path})")
audio = AudioSegment.from_file(audio_path)
nonsilent_ranges = detect_nonsilent(
audio,
min_silence_len=min_silence_len,
silence_thresh=silence_thresh
)
chunks = []
for start_i, end_i in nonsilent_ranges:
start_i = max(0, start_i - keep_silence)
end_i = min(len(audio), end_i + keep_silence)
chunk_audio = audio[start_i:end_i]
chunks.append({
"start_sec": start_i / 1000.0,
"end_sec": end_i / 1000.0,
"audio_segment": chunk_audio
})
return chunks
def translate_text_segments_llm(segments, device_str, model_id, low_vram_mode, target_lang, use_compile, progress=None):
print(f"\n -> Loading LLM for Translation ({model_id}) -> Target: {target_lang}")
if low_vram_mode:
device_map_config = "auto"
else:
device_map_config = device_str
dtype = torch.bfloat16 if device_str != "cpu" else torch.float32
try:
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
dtype=dtype,
device_map=device_map_config,
trust_remote_code=True,
low_cpu_mem_usage=True
)
except Exception as e:
raise RuntimeError(f"Model Load Error: {e}")
# ★変更点: torch.compile の適用
if use_compile:
print(" [INFO] Enabling torch.compile()... First run may be slow.")
try:
# mode="reduce-overhead" は推論向きですが、エラーが出る場合は mode="default" に自動で落ちるか、
# 単純に torch.compile(model) と書くのが無難です。ここでは標準設定でいきます。
model = torch.compile(model)
except Exception as e:
print(f" [Warning] torch.compile failed or not supported: {e}")
# 多言語対応プロンプト
system_prompt = (
f"You are a professional translator specializing in PC hardware and technology.\n"
f"Translate the following text into **{target_lang}**.\n"
"Maintain technical terms (like 'Driver', 'Crash', 'GPU') appropriately for the target language context.\n"
"**Output ONLY the translated text. Do not include original text or explanations.**"
)
if low_vram_mode and hasattr(model, "device"):
main_device = model.device
else:
main_device = torch.device(device_str)
total_lines = len(segments)
for i, seg in enumerate(segments):
if progress:
progress((i / total_lines), desc=f"翻訳中... {i+1}/{total_lines}")
original_text = seg["text"]
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": original_text}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(main_device)
with torch.no_grad():
generated_ids = model.generate(
model_inputs.input_ids,
attention_mask=model_inputs.attention_mask,
pad_token_id=tokenizer.eos_token_id,
max_new_tokens=128,
temperature=0.3,
do_sample=True
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
seg["text"] = response.strip()
del model
del tokenizer
cleanup_memory()
return segments
def write_srt_from_segments(segments, srt_path):
with open(srt_path, "w", encoding="utf-8") as f:
for i, seg in enumerate(segments):
start_str = format_timestamp(seg["start"])
end_str = format_timestamp(seg["end"])
text = seg["text"].strip()
if not text: continue
f.write(f"{i + 1}\n{start_str} --> {end_str}\n{text}\n\n")
# ---------------------------------------------------------
# 3. メイン処理
# ---------------------------------------------------------
def process_videos_gradio(files, llm_model_id, whisper_model_id, source_lang, target_lang, low_vram, use_compile,
silence_thresh, min_silence_len, keep_silence,
progress=gr.Progress()):
if not files:
return None, "ファイルが選択されていません。"
device = get_device()
processed_files = []
log_messages = []
min_sil_len = int(min_silence_len)
keep_sil = int(keep_silence)
sil_thresh = int(silence_thresh)
script_dir = Path(__file__).parent.resolve()
save_base_dir = script_dir / "Translated_Videos"
save_base_dir.mkdir(exist_ok=True)
iso_code_map = {
"Japanese": "jpn", "English": "eng", "German": "ger",
"French": "fre", "Spanish": "spa", "Portuguese": "por"
}
meta_lang_code = iso_code_map.get(target_lang, "eng")
for file_obj in files:
input_path = Path(file_obj.name if hasattr(file_obj, "name") else file_obj)
output_filename = f"{input_path.stem}_{meta_lang_code}_subtitled.mp4"
output_path = save_base_dir / output_filename
temp_dir = input_path.parent / (input_path.stem + "_temp")
temp_dir.mkdir(exist_ok=True)
full_audio_path = temp_dir / "full_audio.wav"
chunk_audio_path = temp_dir / "chunk_temp.wav"
src_srt_path = temp_dir / "source.srt"
tgt_srt_path = temp_dir / "target.srt"
try:
progress(0, desc=f"処理開始: {input_path.name}")
# 1. 音声抽出
if not full_audio_path.exists():
subprocess.run([
"ffmpeg", "-y", "-i", str(input_path),
"-vn", "-acodec", "pcm_s16le", "-ar", "16000", "-ac", "1",
"-loglevel", "error", str(full_audio_path)
], check=True)
# 2. スライス
sliced_chunks = slice_audio_by_silence(full_audio_path, min_sil_len, sil_thresh, keep_sil)
# 3. Whisper文字起こし
progress(0.2, desc="Whisperモデル読込中...")
pipe = pipeline(
"automatic-speech-recognition",
model=whisper_model_id,
device=device,
dtype=torch.bfloat16 if device != "cpu" else torch.float32,
model_kwargs={"low_cpu_mem_usage": True}
)
final_segments = []
generate_args = {}
if source_lang and source_lang != "auto":
generate_args["language"] = source_lang
total_chunks = len(sliced_chunks)
for idx, chunk_data in enumerate(sliced_chunks):
progress(0.2 + (0.3 * (idx / total_chunks)), desc=f"文字起こし中... {idx}/{total_chunks}")
chunk_data["audio_segment"].export(chunk_audio_path, format="wav")
offset = chunk_data["start_sec"]
try:
result = pipe(
str(chunk_audio_path),
batch_size=1,
return_timestamps=True,
generate_kwargs=generate_args
)
for inner in result["chunks"]:
text = inner.get("text", "").strip()
ts = inner.get("timestamp")
if text and ts:
s, e = ts
if e is None: e = s + 5.0
final_segments.append({"start": offset+s, "end": offset+e, "text": text})
except Exception as e:
print(f"Slice error: {e}")
write_srt_from_segments(final_segments, src_srt_path)
del pipe
cleanup_memory()
# 4. 翻訳
progress(0.5, desc=f"翻訳モデル読込中... (-> {target_lang})")
final_segments = translate_text_segments_llm(
final_segments, device, llm_model_id, low_vram, target_lang, use_compile,
progress=lambda p, desc: progress(0.5 + (0.4 * p), desc=desc)
)
write_srt_from_segments(final_segments, tgt_srt_path)
# 5. 合成
progress(0.9, desc="字幕合成中...")
subprocess.run([
"ffmpeg", "-y",
"-i", str(input_path),
"-i", str(tgt_srt_path),
"-map", "0:v", "-map", "0:a", "-map", "1:s",
"-c:v", "copy", "-c:a", "copy", "-c:s", "mov_text",
f"-metadata:s:s:0", f"language={meta_lang_code}",
"-loglevel", "error", str(output_path)
], check=True)
processed_files.append(str(output_path))
log_messages.append(f"完了: {output_path.name}")
except Exception as e:
log_messages.append(f"エラー ({input_path.name}): {str(e)}")
print(f"Error detail: {e}")
finally:
if temp_dir.exists():
try:
shutil.rmtree(temp_dir, ignore_errors=True)
print(f"Cleanup: Deleted temp dir {temp_dir}")
except Exception as e:
print(f"Cleanup Error: {e}")
log_messages.append(f"\nすべてのファイルは以下のフォルダに保存されました:\n[{save_base_dir}]")
return processed_files, "\n".join(log_messages)
# ---------------------------------------------------------
# 4. Gradio UI構築
# ---------------------------------------------------------
with gr.Blocks(title="AI動画自動翻訳ツール") as app:
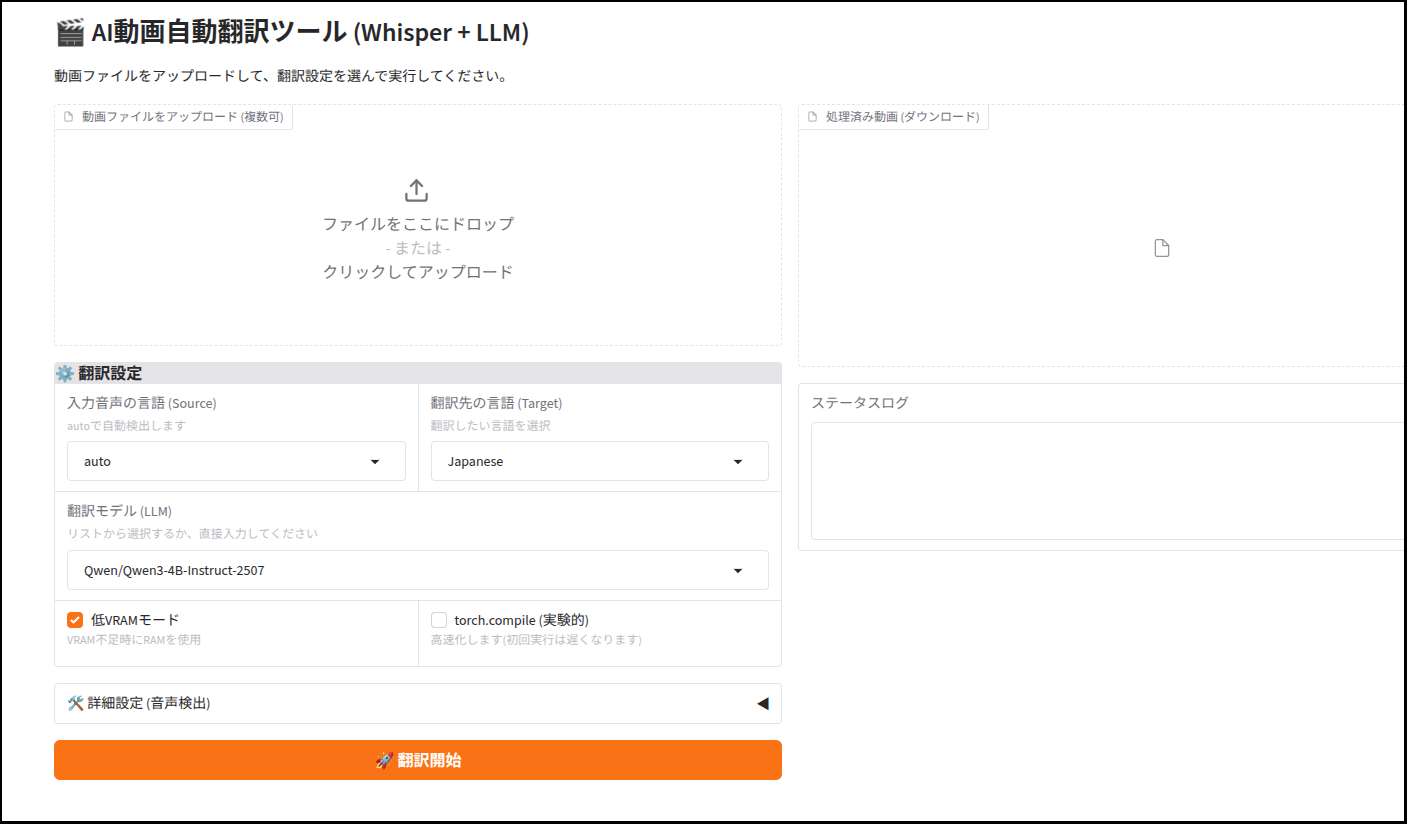
gr.Markdown("# 🎬 AI動画自動翻訳ツール (Whisper + LLM)")
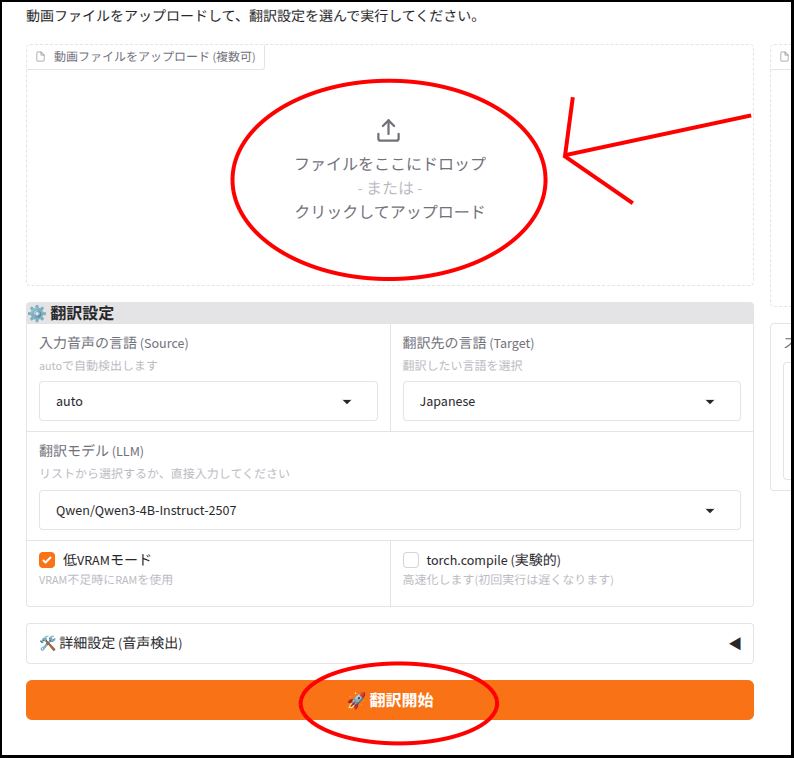
gr.Markdown("動画ファイルをアップロードして、翻訳設定を選んで実行してください。")
with gr.Row():
with gr.Column(scale=1):
# --- 入力エリア ---
file_input = gr.File(label="動画ファイルをアップロード (複数可)", file_count="multiple", file_types=[".mp4", ".mkv"])
with gr.Group():
gr.Markdown("### ⚙️ 翻訳設定")
with gr.Row():
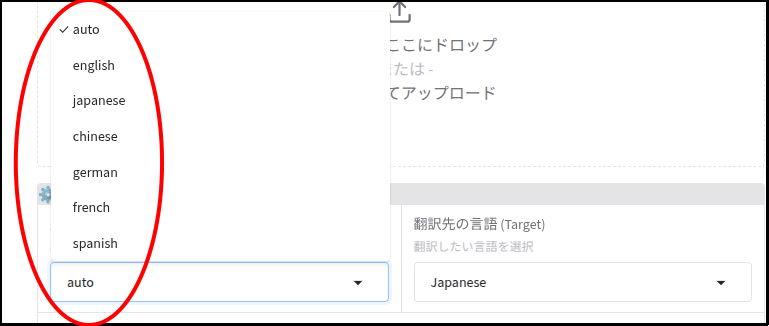
source_lang = gr.Dropdown(
label="入力音声の言語 (Source)",
choices=["auto", "english", "japanese", "chinese", "german", "french", "spanish"],
value="auto",
info="autoで自動検出します"
)
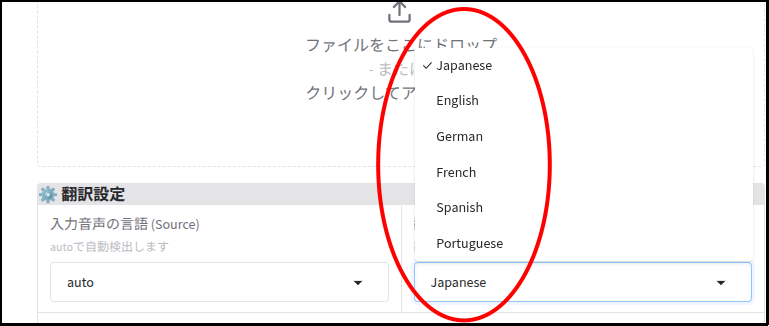
target_lang = gr.Dropdown(
label="翻訳先の言語 (Target)",
choices=["Japanese", "English", "German", "French", "Spanish", "Portuguese"],
value="Japanese",
info="翻訳したい言語を選択"
)
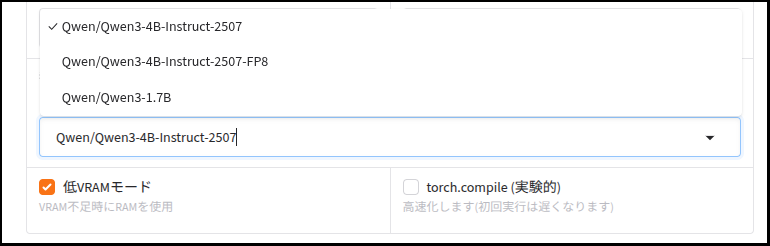
llm_model = gr.Dropdown(
label="翻訳モデル (LLM)",
choices=[
"Qwen/Qwen3-4B-Instruct-2507",
"Qwen/Qwen3-4B-Instruct-2507-FP8",
"Qwen/Qwen3-1.7B"
],
value="Qwen/Qwen3-4B-Instruct-2507",
allow_custom_value=True,
info="リストから選択するか、直接入力してください"
)
with gr.Row():
low_vram_chk = gr.Checkbox(label="低VRAMモード", value=True, info="VRAM不足時にRAMを使用")
# ★追加機能: torch.compile
compile_chk = gr.Checkbox(label="torch.compile (実験的)", value=False, info="高速化します(初回実行は遅くなります)")
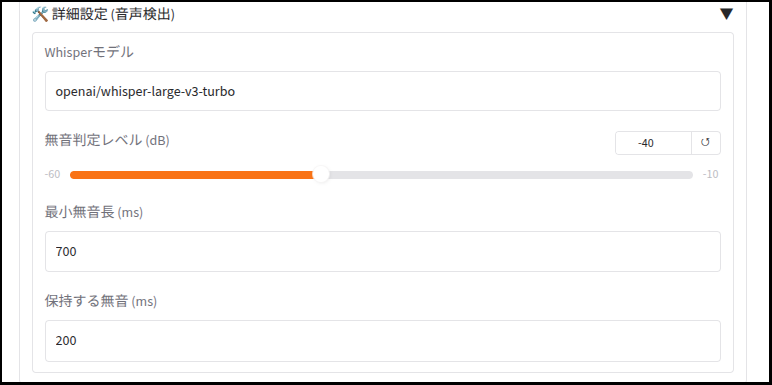
with gr.Accordion("🛠️ 詳細設定 (音声検出)", open=False):
whisper_model = gr.Textbox(label="Whisperモデル", value="openai/whisper-large-v3-turbo")
sil_thresh = gr.Slider(label="無音判定レベル (dB)", minimum=-60, maximum=-10, value=-40, step=1)
min_sil = gr.Number(label="最小無音長 (ms)", value=700)
keep_sil = gr.Number(label="保持する無音 (ms)", value=200)
run_btn = gr.Button("🚀 翻訳開始", variant="primary")
with gr.Column(scale=1):
# --- 出力エリア ---
output_files = gr.File(label="処理済み動画 (ダウンロード)", interactive=False)
status_box = gr.Textbox(label="ステータスログ", lines=5, interactive=False)
# --- イベントハンドラ ---
run_btn.click(
fn=process_videos_gradio,
inputs=[
file_input, llm_model, whisper_model, source_lang, target_lang,
low_vram_chk, compile_chk, # ここに compile_chk を追加
sil_thresh, min_sil, keep_sil
],
outputs=[output_files, status_box],
show_progress="minimal"
)
if __name__ == "__main__":
app.queue().launch(inbrowser=True)実行するには以下のコマンドです。
source .venv/bin/activate
python ./translate_gradio.py gradio版のUI
最後に
Geminiが超優秀なのでgradio版もついでに作ってもらいましたが、どうでしょうか。
前回の記事で紹介したCUI版と比べてみて、好きな方をどうぞ。
今回は以上です。
自分が使っている「Pro B60」ですが、記事を書いている現在は在庫が全滅しています。
価格.comでも全て空ですね。
こんな高価なのは、無理に買わなくても下のB580の方が個人的にオススメです。

SPARKLE Intel Arc A60 搭載 グラフィックボード ロープロファイル 対応 【国内正規代理店品】 SBP60W-24G
【型番】:SBP60W-24G(SB60W-24G) 【GPU】:Intel Arc A60 【GPUアーキテクチャ】:Intel Xe HPG 【メモリ容量】:24GB GDDR6 【メモリバス幅】:192bit 【インターフェース】:P...
amzn.to
B580は玄人志向のDFが安く、全長240mmと小さいので取り回しも良くオススメです。
負荷中はちょっとうるさいかもしれませんが、B60よりははるかにマシでしょう。
が、ジワジワ価格が上昇しているようです・・・。

玄人志向 Intel Arc B580 搭載 グラフィックボード GDDR6 12GB 【国内正規代理店品】 AR-B580D6-E12GB/DF
【型番】:AR-B580D6-E12GB/DF 【GPU】:Intel Arc B580 【コアクロック】:Boost:2670 MHz 【メモリ容量】:12GB GDDR6 【メモリバス幅】:256bit 【メモリスピード】:19Gbps...
amzn.to
RX9060XTの16GB版ですが、やはり値段がかなり上がってきてますね。

Amazon | SAPPHIRE PURE Radeon RX 9060 XT GAMING OC 16GB グラフィックスボード 11350-02-20G VD9221 | SAPPHIRE | グラフィックボード 通販
SAPPHIRE PURE Radeon RX 9060 XT GAMING OC 16GB グラフィックスボード 11350-02-20G VD9221がグラフィックボードストアでいつでもお買い得。当日お急ぎ便対象商品は、当日お届け可能で...
amzn.to


コメント