Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。

上のリンクの記事をみて「Qwen3-TTS」に興味を持ったので記事にしますね。
調べていると、

こちらの記事で「Qwen3-TTS」の公式UIをすべて日本語化したのみならず、文字起こしなど便利な機能を追加しgithubに公開されている方がおられました。
是非使わせていただこうと思います。
ただ、こちらのリポジトリではcudaのみ対応(Radeonでも動く?)のようで、そのままではIntel Arcでは動きませんので、いろいろと手を加えてみました。
かんたんにIntel Arcでの動作確認はしましたので、とりあえず記事にします。
まずは、uvのインストール
今回はuv環境を使います。
uvの導入は
sudo apt install curl
curl -LsSf https://astral.sh/uv/install.sh | sh
source $HOME/.local/bin/envとなります。
Qwen3-TTS-JPのインストール
上で紹介させていただいた、リポジトリからQwen3-TTS-JPを導入します。
#!/bin/bash
mkdir -p ~/install/Qwen3-TTS-for-xpu
git clone https://github.com/hiroki-abe-58/Qwen3-TTS-JP.git ~/install/Qwen3-TTS-for-xpu
cd ~/install/Qwen3-TTS-for-xpu
# 1.仮想環境の作成と有効化
uv venv --python 3.12 --seed
source .venv/bin/activate
# 2.torch.xpuのインストール
# ※ 最新の安定版を入れます。バージョンは環境に合わせて調整してください
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/xpu
# 3. faster-whisper代わりのTransformersと高速化ライブラリを入れる
# insanely-fast-whisperのコア技術であるtransformers pipelineとaccelerateを入れます
uv pip install transformers==4.57.3 accelerate optimum librosa soundfile onnxruntime sox
# 4. リポジトリ本体のインストール
# ※ --no-deps を付けて、さっき入れたtorch.xpuが上書きされないようにします
uv pip install --no-deps -e .
# 5. 足りない依存関係だけを手動で追加
# setup.py/pyproject.tomlの中身に基づき、TTS動作に必要なものを入れます
uv pip install gradio numpy scipy tqdm pyyaml tensorboard einops文字起こしに使われている「faster-whisper」はIntel Arcでは動きません(自分が動かし方を知らないだけかも)。
なので、代わりに「insanely-fast-whisper」を使います。
Intel Arcで動かすために「run_arc.py」を追加
Qwen3-TTS-JPはソースコードにいたるところでtorch.cudaを呼び出していますが、これではIntel Arcでは動きません。
そこで、いつものようにGeminiにお願いして「run_arc.py」を作ってもらいました。
import sys
import types
import torch
from transformers import pipeline
import functools
print("=== initializing Qwen3-TTS for Intel Arc (XPU) [Final Patch] ===")
# ==========================================
# 0. 互換性パッチ: Allocator Warmup無効化
# ==========================================
try:
import transformers.modeling_utils
transformers.modeling_utils.caching_allocator_warmup = lambda *args, **kwargs: None
except:
pass
# ==========================================
# 1. 互換性パッチ: Config pad_token_id
# ==========================================
try:
from qwen_tts.core.models.modeling_qwen3_tts import Qwen3TTSTalkerConfig
_original_config_init = Qwen3TTSTalkerConfig.__init__
def _patched_config_init(self, *args, **kwargs):
_original_config_init(self, *args, **kwargs)
if not hasattr(self, "pad_token_id") or self.pad_token_id is None:
self.pad_token_id = 0
Qwen3TTSTalkerConfig.__init__ = _patched_config_init
except ImportError:
pass
# ==========================================
# 2. CUDA偽装パッチ (Factory Functions)
# ==========================================
# device="cuda" を device="xpu" に書き換える処理
def _convert_device_arg(kwargs):
if "device" in kwargs:
dev = kwargs["device"]
if (isinstance(dev, str) and "cuda" in dev) or \
(isinstance(dev, torch.device) and dev.type == "cuda"):
kwargs["device"] = "xpu"
return kwargs
# クロージャの問題を回避するためのファクトリ関数
def create_patched_factory(original_func):
@functools.wraps(original_func)
def patched_factory(*args, **kwargs):
# デバイス引数をXPUに置換
kwargs = _convert_device_arg(kwargs)
return original_func(*args, **kwargs)
return patched_factory
_torch_factories = ["empty", "zeros", "ones", "full", "randn", "rand", "tensor", "arange", "linspace"]
count = 0
for func_name in _torch_factories:
if hasattr(torch, func_name):
original = getattr(torch, func_name)
# ここで関数を作成してセットする(変数が上書きされないように分離)
setattr(torch, func_name, create_patched_factory(original))
count += 1
print(f"=== [Patch] Successfully redirected {count} torch factory functions to XPU. ===")
# ==========================================
# 3. CUDA偽装パッチ (API Level)
# ==========================================
# A. 有無チェック
torch.cuda.is_available = lambda: True
torch.cuda.device_count = lambda: 1
torch.cuda.current_device = lambda: 0
torch.cuda.get_device_name = lambda x=0: "Intel Arc Pro B60"
torch.cuda.set_device = lambda x: None
# B. メモリ情報
def patched_mem_get_info(device=None):
try:
return torch.xpu.mem_get_info(device)
except:
return (20 * 1024**3, 24 * 1024**3)
torch.cuda.mem_get_info = patched_mem_get_info
# C. デバイスプロパティ
class DummyDeviceProperties:
def __init__(self):
self.total_memory = 24 * 1024**3
self.major = 8
self.minor = 0
self.name = "Intel Arc Pro B60"
self.multi_processor_count = 128
torch.cuda.get_device_properties = lambda device: DummyDeviceProperties()
torch.cuda.get_device_capability = lambda device=None: (8, 0)
# D. 転送メソッド (.to, .cuda)
original_to = torch.Tensor.to
def patched_to(self, *args, **kwargs):
new_args = list(args)
if len(new_args) > 0:
if isinstance(new_args[0], str) and "cuda" in new_args[0]:
new_args[0] = new_args[0].replace("cuda", "xpu")
elif isinstance(new_args[0], torch.device) and new_args[0].type == "cuda":
new_args[0] = torch.device("xpu")
if "device" in kwargs:
dev = kwargs["device"]
if isinstance(dev, str) and "cuda" in dev:
kwargs["device"] = dev.replace("cuda", "xpu")
elif isinstance(dev, torch.device) and dev.type == "cuda":
kwargs["device"] = torch.device("xpu")
return original_to(self, *new_args, **kwargs)
torch.Tensor.to = patched_to
torch.Tensor.cuda = lambda self, *args, **kwargs: self.to("xpu")
# ==========================================
# 4. Whisper アダプター (Transformers Pipeline化)
# ==========================================
class ArcWhisperAdapter:
def __init__(self, model_size_or_path, device="xpu", compute_type="float16", **kwargs):
if "/" not in model_size_or_path:
model_id = f"openai/whisper-{model_size_or_path}"
else:
model_id = model_size_or_path
print(f"=== [Arc Wrapper] Loading Whisper model '{model_id}'... ===")
self.pipe = pipeline(
"automatic-speech-recognition",
model=model_id,
device="xpu",
torch_dtype=torch.float16,
chunk_length_s=30,
)
def transcribe(self, audio, language=None, beam_size=5, **kwargs):
generate_kwargs = {}
if language:
generate_kwargs["language"] = language
outputs = self.pipe(
audio,
batch_size=16,
return_timestamps=True,
generate_kwargs=generate_kwargs
)
class DummySegment:
def __init__(self, text):
self.text = text
self.start = 0.0
self.end = 0.0
return [DummySegment(outputs["text"])], None
dummy_fw = types.ModuleType("faster_whisper")
dummy_fw.WhisperModel = ArcWhisperAdapter
sys.modules["faster_whisper"] = dummy_fw
# ==========================================
# 5. メインプロセスの起動
# ==========================================
if __name__ == "__main__":
from qwen_tts.cli.demo import main
if "--no-flash-attn" not in sys.argv:
sys.argv.append("--no-flash-attn")
model_arg_exists = any("Qwen/Qwen3-TTS" in arg for arg in sys.argv)
if not model_arg_exists:
sys.argv.append("Qwen/Qwen3-TTS-12Hz-1.7B-Base")
if "--port" not in sys.argv:
sys.argv.extend(["--port", "7860"])
if "--ip" not in sys.argv:
sys.argv.extend(["--ip", "0.0.0.0"])
print("=== Launching Qwen3-TTS Main Loop ===")
main()実は自分は中身について全くわかっていません。
なので、この記事を見ている人で動かしてみようと思っている方は、自己責任でお願いします。
上のスクリプトを「run_arc.py」として保存します。
そうしたら、これを「Qwen3-TTS-for-xpu」のフォルダの中に移動します。
では起動してみましょう。
source .venv/bin/activate
python ./run_arc.py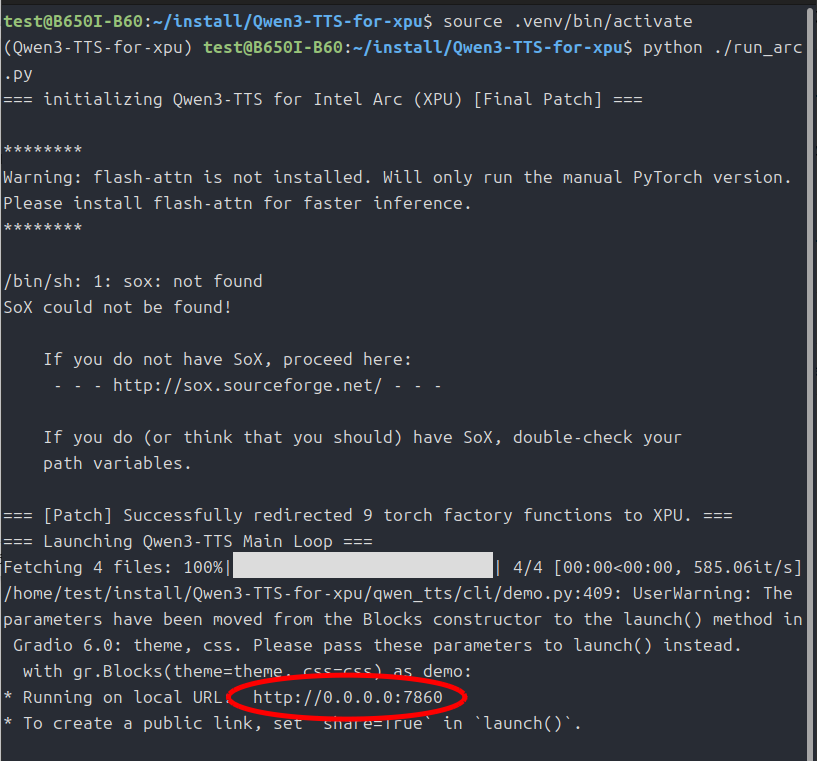
簡単にテスト
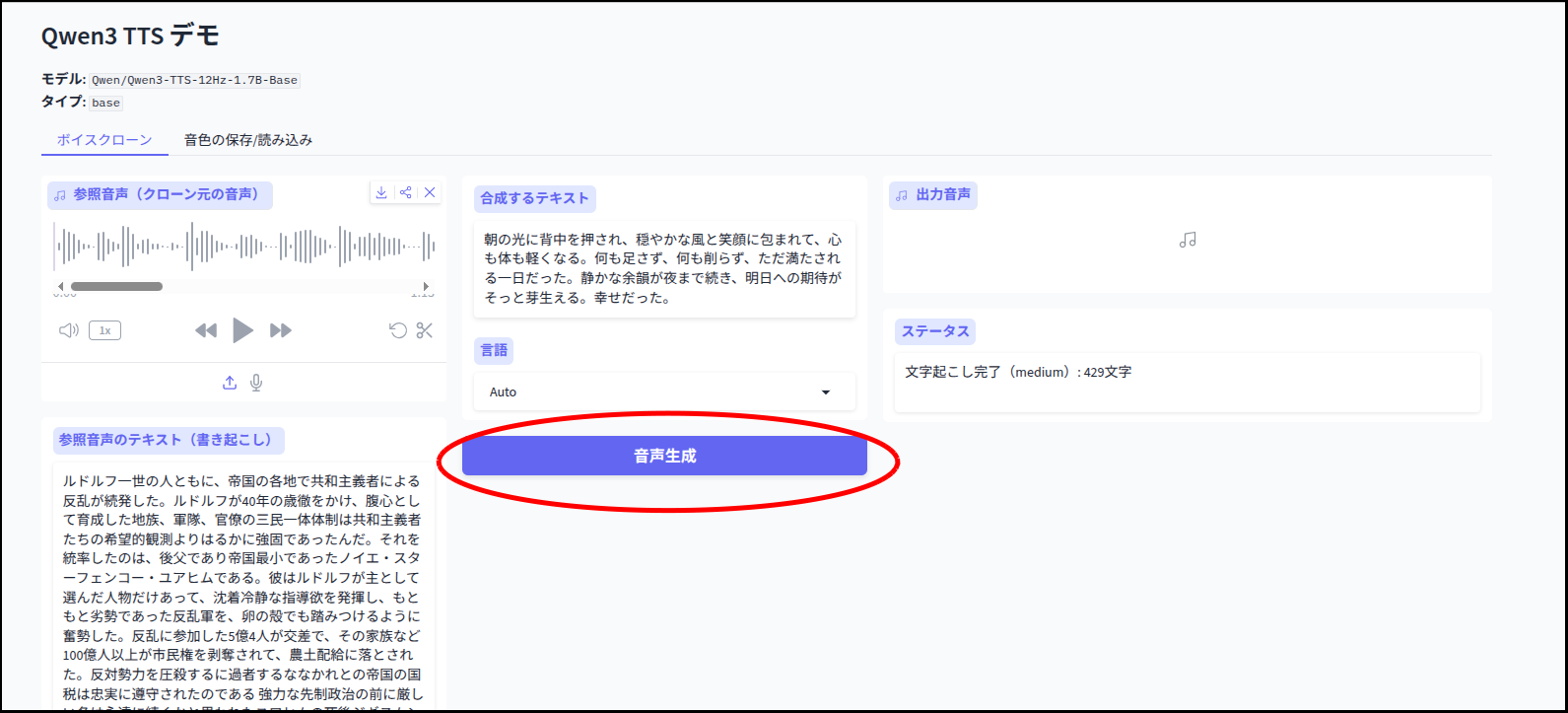
それでは簡単にテストしてみましょう。
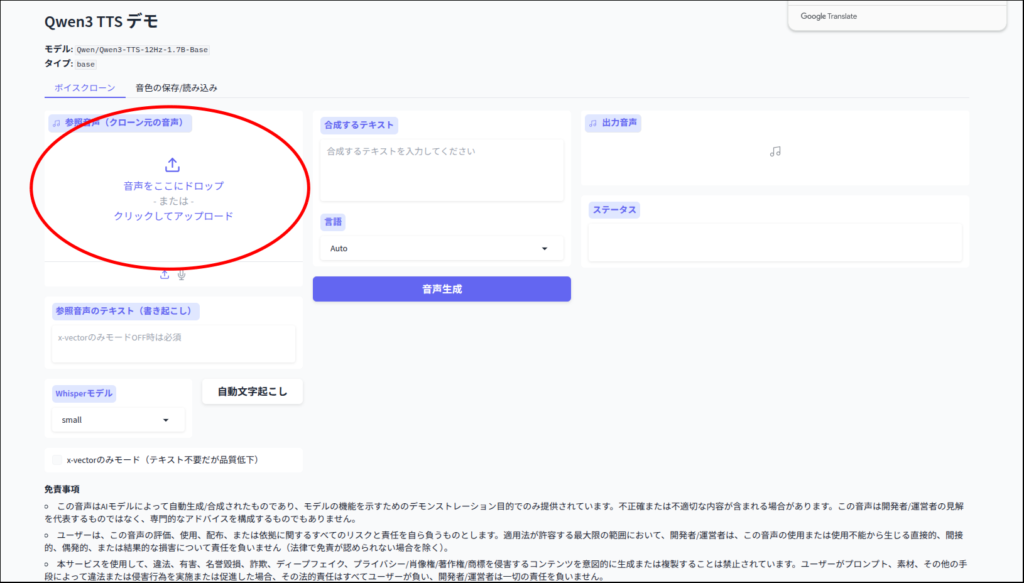
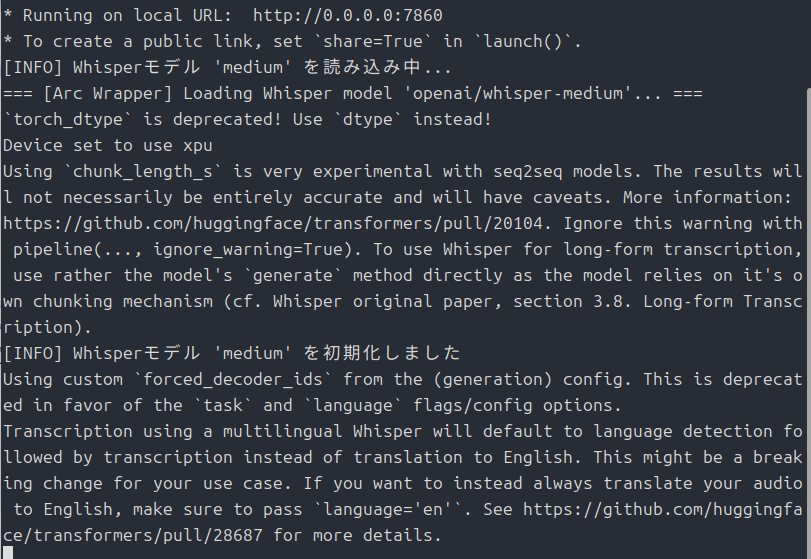
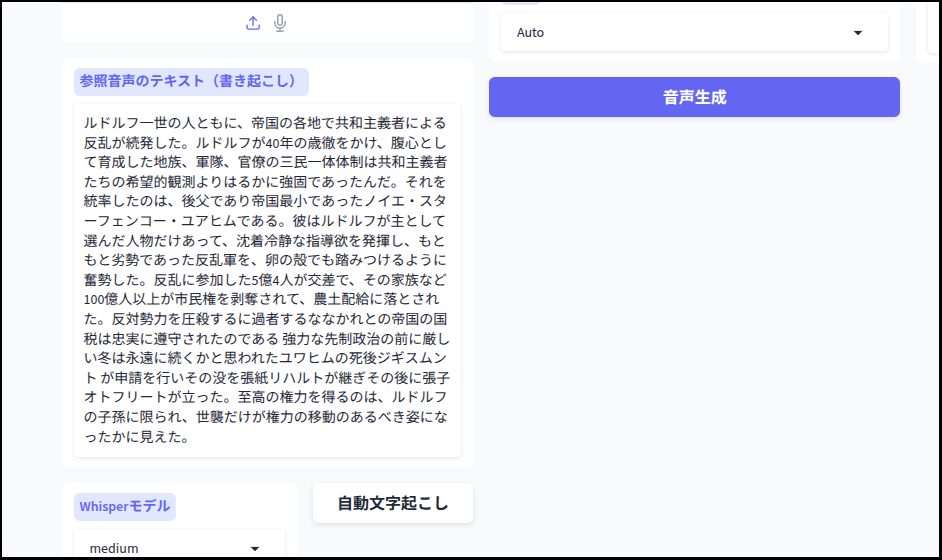
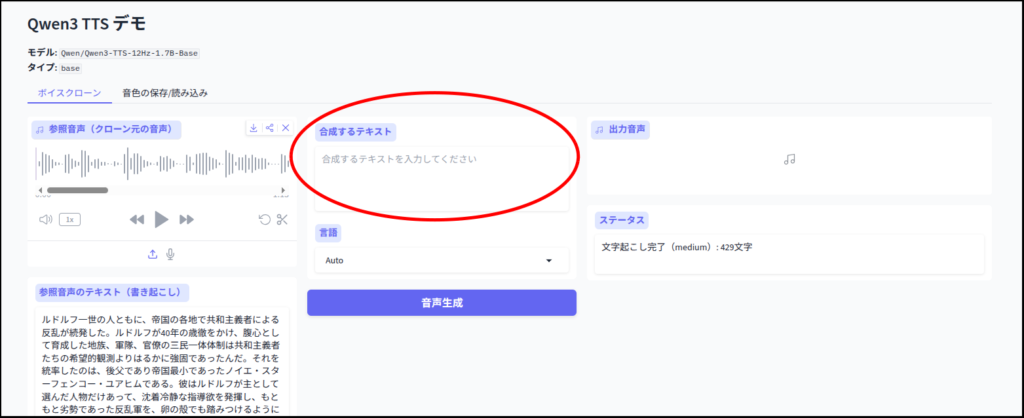
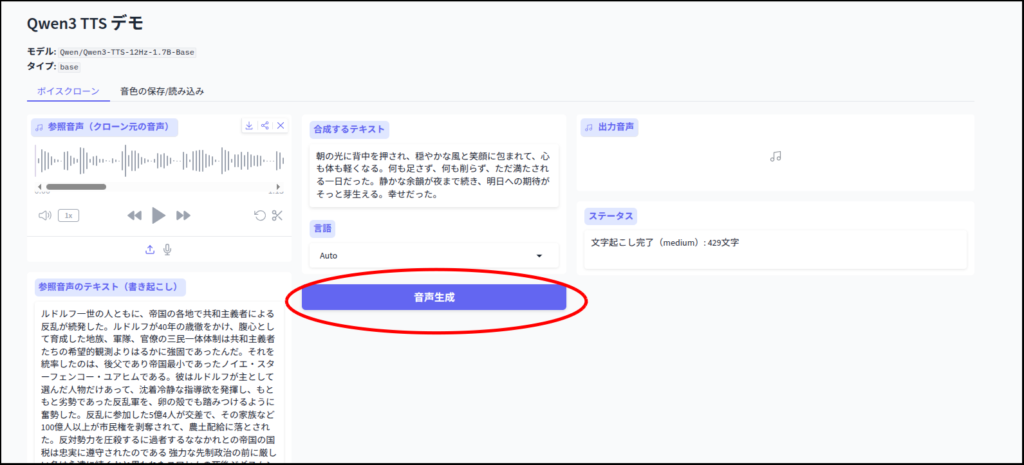
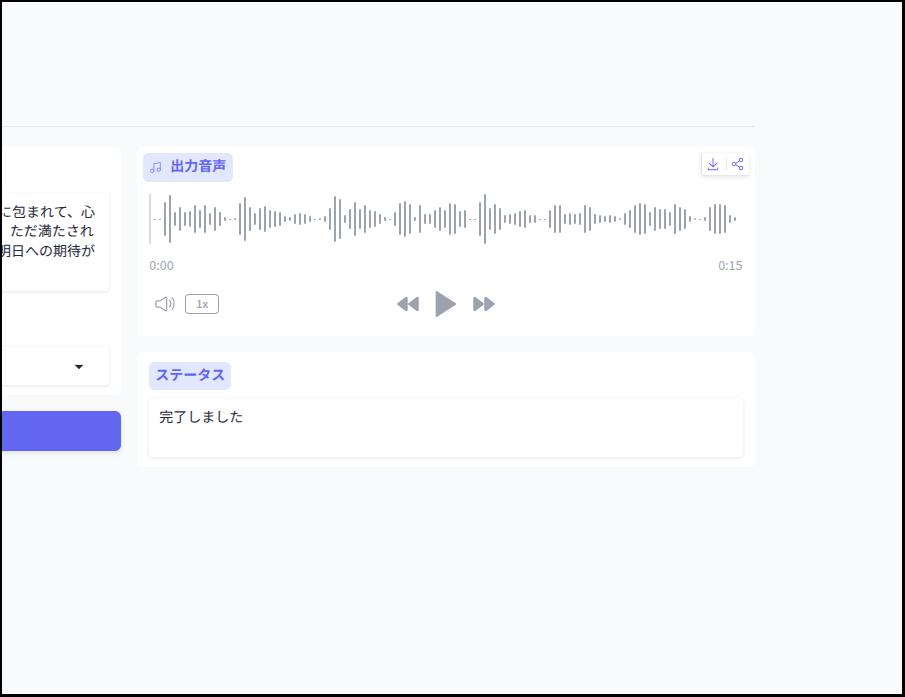
ちょっと読み間違いがあるのと、抑揚が不自然な点が気になります。
「Qwen3-TTS」はまだ発表されたばかりなので、これからでしょう。
以前の記事で紹介した、GPT-SoVITSと比べどのように発展するのか楽しみです。
今回は以上です。
追記(2026/2/23)
この「Qwen3-TTS」ですが、ComfyUIでも使えるみたいですね。
自分もComfyUIで使ってみましたが、ちょっと工夫するとIntel Arcでも動作するみたいです。準備ができ次第、記事にしますね。
記事にしました。こちらをどうぞ。
相変わらず表記がおかしいですが、「Arc Pro B60」らしきものがAmazonにあるみたいです。

B580も在庫が復活しているみたい。


コメント