Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。
前回の記事でvLLMをIntel Arcで動作させる記事を書きました。
今回はvLLMとOpenManusを連携させて、AIエージェントとして動かしてみます。
ただし、初めに書いておきますが、自分はまだvLLMもOpenManusもぜんぜん使いこなせてません。
今回も「一応動作させた」レベルで留まっています。
ただ、おもしろい機能だと思うので今後もいろいろ試していきます。
なにか発見があったら、新たに記事にするかもしれません。
それでは、いってみましょう。
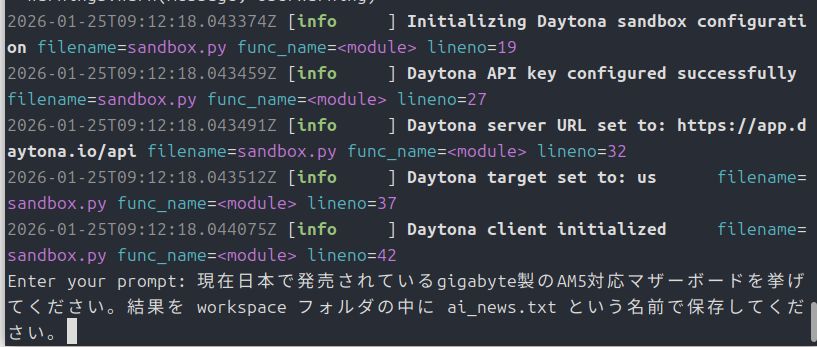
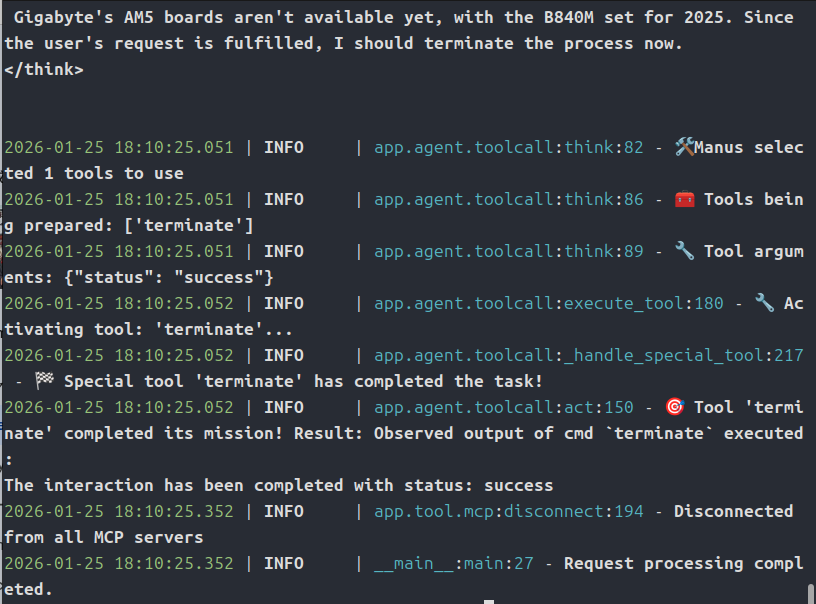
OpenManusは起動するものの、gpt-oss-20bでは動作せず・・・
実はgpt-oss-20bでは動作させることはできませんでした。
vLLMではきちんと動作しています。
OpenManusの起動もできて、プロンプトの受付まではいけるのです。
ただ、OpenManus側でvLLMサーバーからの命令がうまく受け取れていないようです。
もし、うまく動作させる方法があったら教えてください。
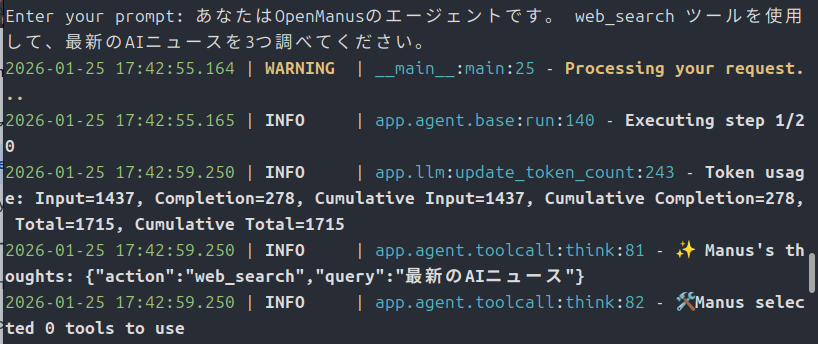
では、気を取り直して他のモデルで動かしていきます。
まずはvLLMを前もって起動しておく
OpenManusとは別のターミナルであらかじめvLLMを起動しておきます。
詳しくは以前の記事を参考にしてください。
今回はかんたんに手順を書いておきます。
#停止していたらコンテナを起動
sudo docker start vllm-test
#コンテナ内に移動
sudo docker exec -it vllm-test bash
#Qwen3-14b-awqをvLLMで起動
vllm serve Qwen/Qwen3-14B-AWQ \
--dtype=auto \
--port 8000 \
--host 0.0.0.0 \
--trust-remote-code \
--gpu-memory-util=0.9 \
--max-model-len=32768 \
--enable-auto-tool-choice \
--tool-call-parser hermes \
--enforce-eagerコマンドを見てのとおり、モデルは「Qwen3-14B-AWQ」を使用しています。
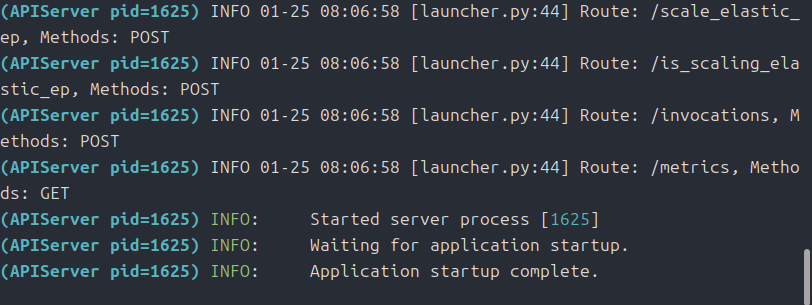
OpenManusをインストール
ざっとインストールスクリプトを書いておきます。
#!/bin/bash
mkdir -p ~/install
git clone https://github.com/FoundationAgents/OpenManus.git ~/install/OpenManus
cd ~/install/OpenManus
# uvを使う方法(推奨)
uv venv --python 3.12 --seed
source .venv/bin/activate
#torch.xpuのstable版をインストール
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/xpu
#crawl4aiがpillow11.1と干渉するためバージョンを指定する
sed -i 's/pillow~=11.1.0/pillow>=10.4.0/' requirements.txt
uv pip install -r requirements.txt
#依存関係が足りない場合
sudo .venv/bin/python3 -m playwright install-deps
#追加
uv pip install structlog daytona
# ブラウザ自動化ツール(オプション)
playwright install(2026/1/25時点)
自分で試した結果、競合したライブラリや足りないファイルがあったので、独自で追加しています。
config.tomlを設定
cp config/config.example.toml config/config.toml上のコマンドで「config.toml」が出来上がりますが、今度はこのファイルをいじっていきます。
「Qwen3-14B-AWQ」で動かすつもりなので、それに対応させていきます。
[llm]
model = "Qwen/Qwen3-14B-AWQ"
base_url = "http://localhost:8000/v1"
api_key = "dummy"
max_tokens = 16384
temperature = 0.0
[daytona]
daytona_api_key = "dummy"
# MCP (Model Context Protocol) configuration
[mcp]
server_reference = "app.mcp.server" # default server module reference
# Optional Runflow configuration
# Your can add additional agents into run-flow workflow to solve different-type tasks.
[runflow]
use_data_analysis_agent = false # The Data Analysi Agent to solve various data analysis tasksこんな感じでしょうか。
では実行していきましょう。
python ./main.py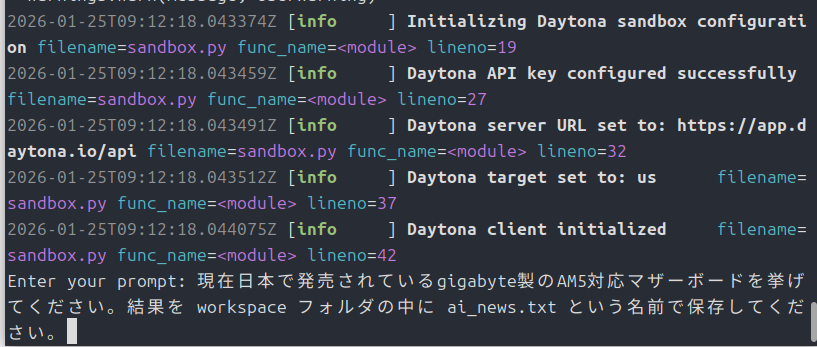


最後に
まだまだ、手探りで実行していますが可能性を感じるツールだと思います。
今後、どのような発展をするのかわかりませんが注視していくつもりです。
もし、「もっと良い使い方があるよ」という意見があれば教えてくださいね。
今回は以上です。
相変わらず表記がおかしいですが、「Arc Pro B60」らしきものがAmazonにあるみたいです。

コメント