以前この記事で、ggufファイルをUbuntuで展開するのは無理だったと書きました。
このときは、ggufをメインメモリに展開しxpuで推論するという処理を、ソースコードを変更して「–novram」を実現していたわけですが、このたびxpu(VRAM)に展開することに成功しました。
あくまで自分とChatGPTで作り上げたので、正解かどうかはわかりません。
とりあえず動作しているので、ここに書き留めておきます。
追記(2025/11/29)
現在では以下の方法を使うことなく、Arc + Ubuntu環境でggufをxpuで扱えます。
「–novram」も効くようで、以下の記事はもう古くなっていますので、無視してください。
カスタムノード「gguf」の「pig.py」を書き換えます
今回もこのggufのカスタムノードを使っていきます。
カスタムノード内の「pig.py」をテキストエディタで開きます。
for sd_key, tensor in tensors:で検索すると、付近に
for sd_key, tensor in tensors:
tensor_name = tensor.name
torch_tensor = torch.from_numpy(tensor.data)
shape = get_orig_shape(reader, tensor_name)というスクリプトがあると思いますが、これを
for sd_key, tensor in tensors:
tensor_name = tensor.name
#torch_tensor = torch.from_numpy(tensor.data)
import numpy as np
np_arr = np.require(tensor.data, requirements=['C'])
if not np_arr.flags.writeable:
np_arr = np.array(np_arr, copy=True)
torch_tensor = torch.from_numpy(np_arr.copy())
shape = get_orig_shape(reader, tensor_name)に書き換えます。
今回も変更済みのpig.pyを置いておきますね。
変更は以上です。
TI2V-5B-ggufなら動作可
I2V-14B-ggufを「–lowvram」で起動すると「Q2_K」でも途中でクラッシュしました。
「–novram」なら動くんですが、それじゃ意味ないですよね・・・。
TI2V-5Bなら「Q6_K」、「–lowvram」オプションで、テキストエンコーダをCPUで処理すればなんとか動作できそうです。
動画の長さによってはVAEをタイルで処理した方が良いでしょう。
本当は生成した動画や生成にかかった時間とか貼り付けたいんですが、自分はその手の調整が下手なもんで、夢に出てきそうなくらい奇怪な動画ができてしまいます。
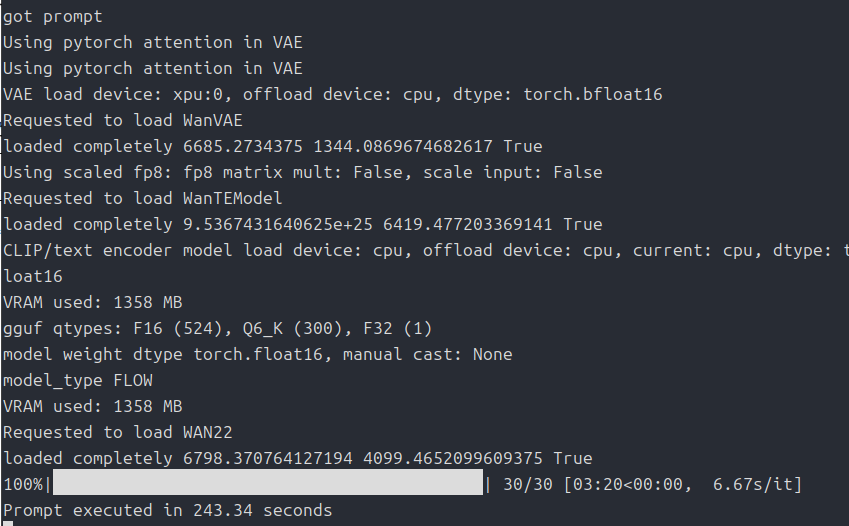
一応参考までに、「640×640」を「97フレーム」、「クリップの読み込み」を「CPU」に、「Q6_K」、「–lowvram」オプションで「ステップ数」は「30」です。生成時間は243秒でした。
初心者向けの記事ではないかもしれませんが、UbuntuでARCを使うなんて茨の道を歩む人はきっとARCユーザーの中でも猛者だと思いますので。
そもそもWindows使えばこんな面倒なことはしなくても大丈夫なんですよね・・・。
今回は以上です。
追記
この記事の公開当初、「llama-cpp-python」をSYCLでビルドしてインストールするという内容があったんですが、これはLLMなどの推論用に必要なもので、動画や画像の生成には必要ないものだったので削除しました。


コメント