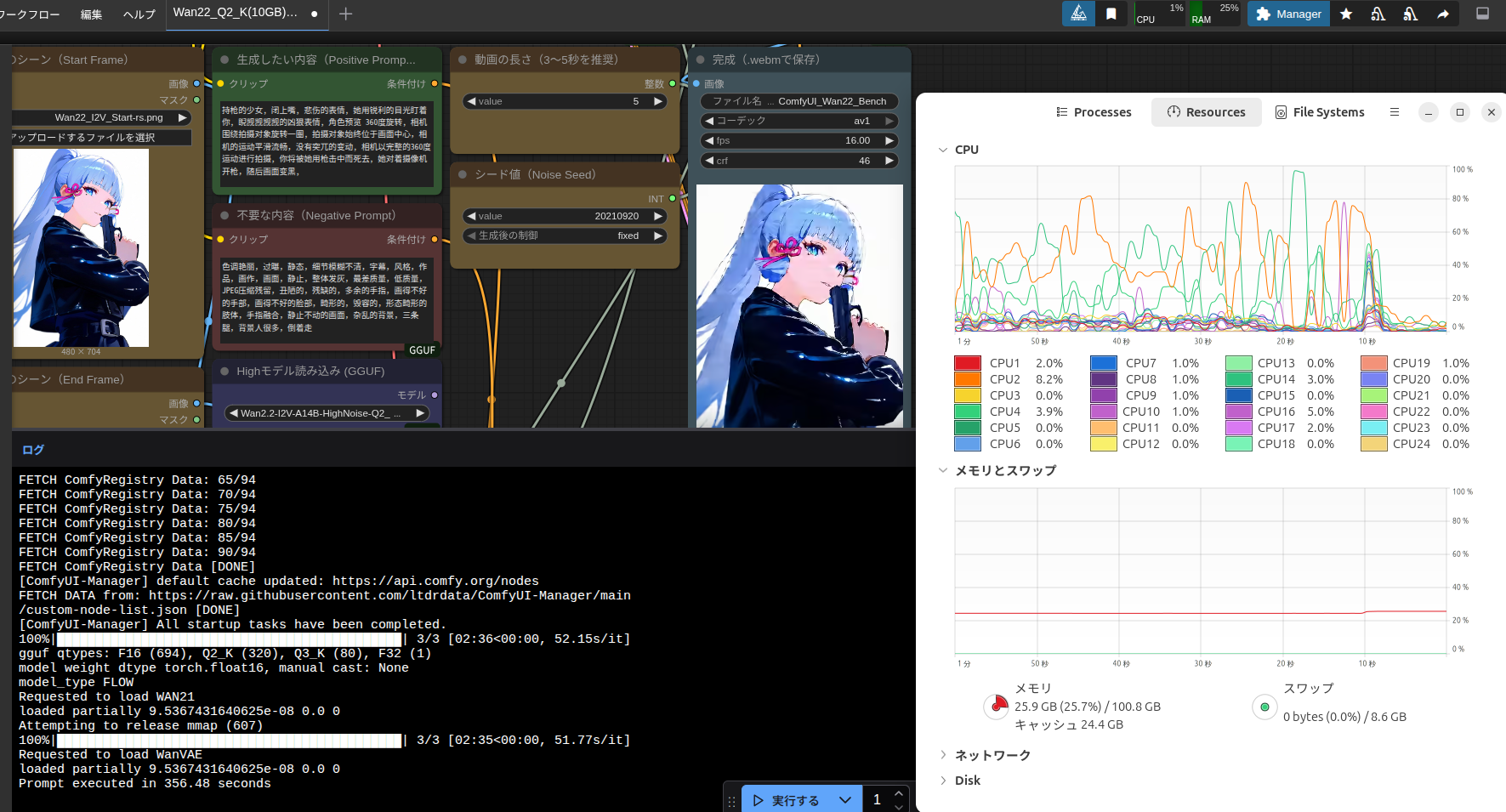
追記(2025/11/29)
現在では以下の方法を使うことなく、Arc + Ubuntu環境でggufをxpuで扱えます。
「–novram」も効くようで、以下の記事はもう古くなっていますので、無視してください。
今まで(自分の中では)ComfyUIで動画生成する際、量子化モデルのggufはIntel ARCでは動きませんでした。
別の方法になりますが、「–novram」オプションでComfyUIを起動し、「wan2.2_i2v_high(low)_noise_14B_fp8_scaled.safetensors」をComfyUI標準のノード「拡散モデルを読み込む」でロードすれば動画を生成することはできます。
今回の記事はGGUFをなんとか使う為の記事ですが、上記の方法の方が生成速度も速いため個人的にはおすすめです。ただ、メインメモリは64GBは必要になるので環境を選ぶのは事実です。
今回はなんとかggufを使ってメインメモリの消費をもう少し抑えられるようにするための記事なのでいろいろと工夫してみた結果、一応動作させることができたので、ここに記録しておきます。
ちなみに「v2.8.10+xpu」が登場したので、ComfyUIの導入手順を書いておきました。
最近はIPEXよりtorch.xpuの方がメモリの節約になるのでこちらの記事もおすすめです。
カスタムノード「gguf」を使う
ggufのカスタムノードといえば「ComfyUI-GGUF」が有名ですが、今回使うのは「gguf」になります。
導入方法は
git clone https://github.com/calcuis/gguf.git上記コマンドを「ConfyUI/Custom_nodes」の中で実行します。
「requirements.txt」を実行する必要はありません。
ただこのままggufを導入し、そのまま使ったのではやはりクラッシュしてしまうので、「gguf」の中にある「pig.py」を多少(6箇所)いじっていきます。
では、やっていきましょう。
1.
torch_tensor = torch.from_numpy(tensor.data)を検索し、ヒットしたら
np_arr = np.array(tensor.data, copy=True)
torch_tensor = torch.from_numpy(np_arr).contiguous() で上書きします。そうしたら
import numpy as npを、pig.pyファイルの上の行あたりにあるimport文のどこでもいいので挿入します。
2.
m.to(self.load_device).to(self.offload_device)で検索し、ヒットしたら
if linked:
print(f'Attempting to release mmap ({len(linked)})')
for n, m in linked:
m.to(self.load_device).to(self.offload_device)
self.mmap_released = Trueこんな感じになっていると思いますので、
if linked:
print(f'Attempting to release mmap ({len(linked)})')
cpu = torch.device("cpu")
for n, m in linked:
for pname, p in m.named_parameters(recurse=False):
p.data = p.data.detach().to(cpu).contiguous().clone()
for bname, b in m.named_buffers(recurse=False):
b.data = b.data.detach().to(cpu).contiguous().clone()
self.mmap_released = Trueに書き換えます。
3.
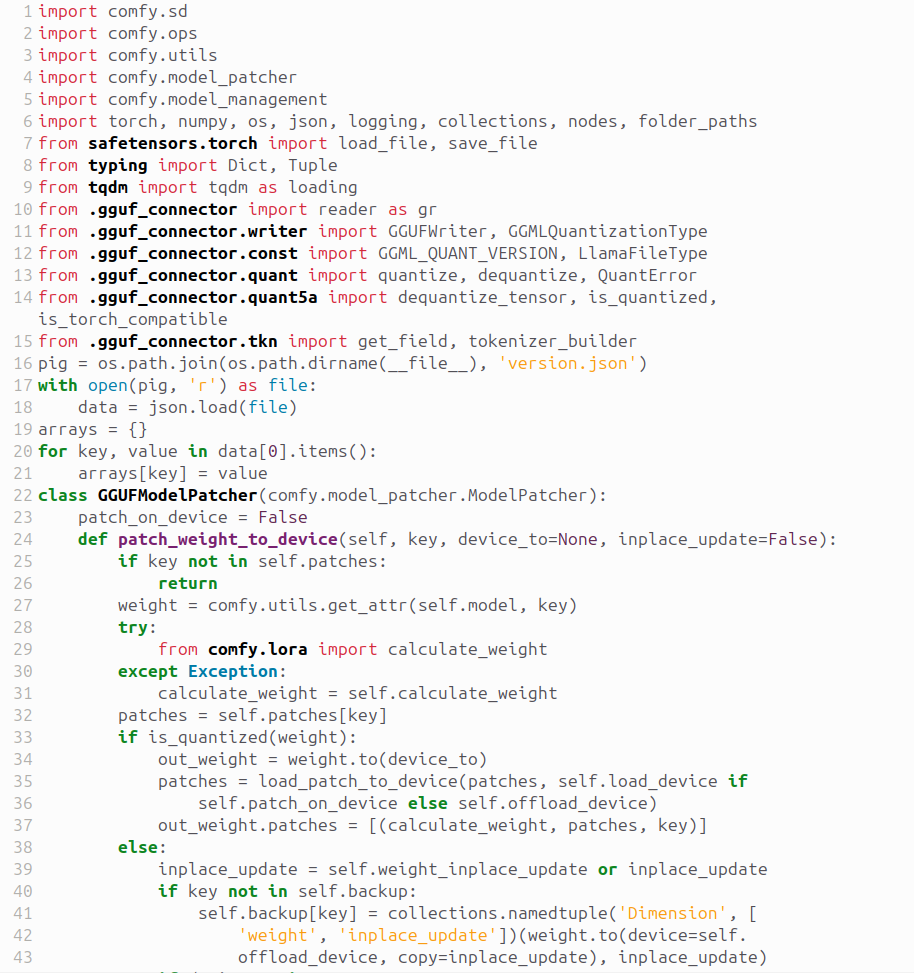
class GGUFModelPatcher(comfy.model_patcher.ModelPatcher)で検索し、ヒットしたら
class GGUFModelPatcher(comfy.model_patcher.ModelPatcher):
patch_on_device = False
def patch_weight_to_device(self, key, device_to=None, inplace_update=False):この部分を
class GGUFModelPatcher(comfy.model_patcher.ModelPatcher):
patch_on_device = False
load_device = torch.device("cpu")
offload_device = torch.device("cpu")
def patch_weight_to_device(self, key, device_to=None, inplace_update=False):に書き換えます。
4.
if is_quantized(weight)で検索し、ヒットしたら
if is_quantized(weight):
out_weight = weight.to(device_to)
patches = load_patch_to_device(patches, self.load_device if
self.patch_on_device else self.offload_device)
out_weight.patches = [(calculate_weight, patches, key)]
else:の部分を
if is_quantized(weight):
out_weight = weight.to(torch.device("cpu"))
patches = load_patch_to_device(patches,torch.device("cpu"))
out_weight.patches = [(calculate_weight, patches, key)]
else:に書き換えます。
5.
inplace_update = self.weight_inplace_update or inplace_updateで検索し、ヒットしたら
inplace_update = self.weight_inplace_update or inplace_update
if key not in self.backup:
self.backup[key] = collections.namedtuple('Dimension', [
'weight', 'inplace_update'])(weight.to(device=self.
offload_device, copy=inplace_update), inplace_update)
if device_to is not None:
temp_weight = comfy.model_management.cast_to_device(weight,
device_to, torch.float32, copy=True)
else:
temp_weight = weight.to(torch.float32, copy=True)
out_weight = calculate_weight(patches, temp_weight, key)
out_weight = comfy.float.stochastic_rounding(out_weight, weight
.dtype)この部分を
inplace_update = self.weight_inplace_update or inplace_update
if key not in self.backup:
self.backup[key] = collections.namedtuple('Dimension',['weight', 'inplace_update'])(weight.to(device=torch.device("cpu"), copy=inplace_update),inplace_update)
# 計算用の一時テンソルもCPUで作る(推論時に必要ならXPUへ)
temp_weight = weight.to(torch.float32, copy=True)
out_weight = calculate_weight(patches, temp_weight, key)
out_weight = comfy.float.stochastic_rounding(out_weight, weight.dtype)に書き換えます。
6.
model = comfy.sd.load_diffusion_model_state_dictで検索し、ヒットしたら
model = comfy.sd.load_diffusion_model_state_dict(sd, model_options=
{'custom_operations': ops})の部分を
model = comfy.sd.load_diffusion_model_state_dict(sd, model_options=
{'custom_operations': ops,'load_device': torch.device('cpu'),'offload_device': torch.device('cpu'),})に書き換えます。
起動
python ./main.py --auto-launch --novram --disable-ipex-optimizeで起動してください。起動したらカスタムノード検索(何もないところでダブルクリック)。
仕組み
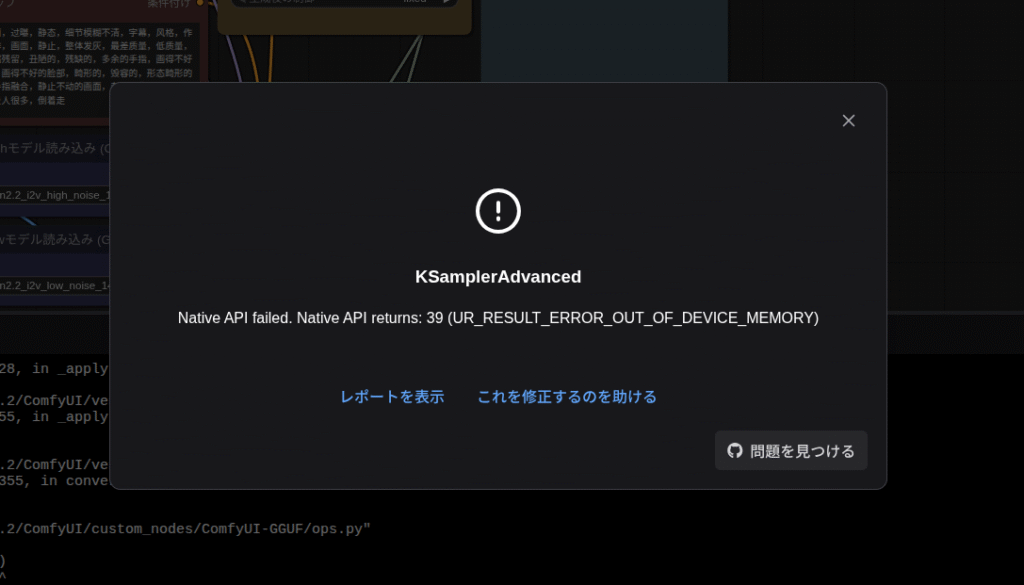
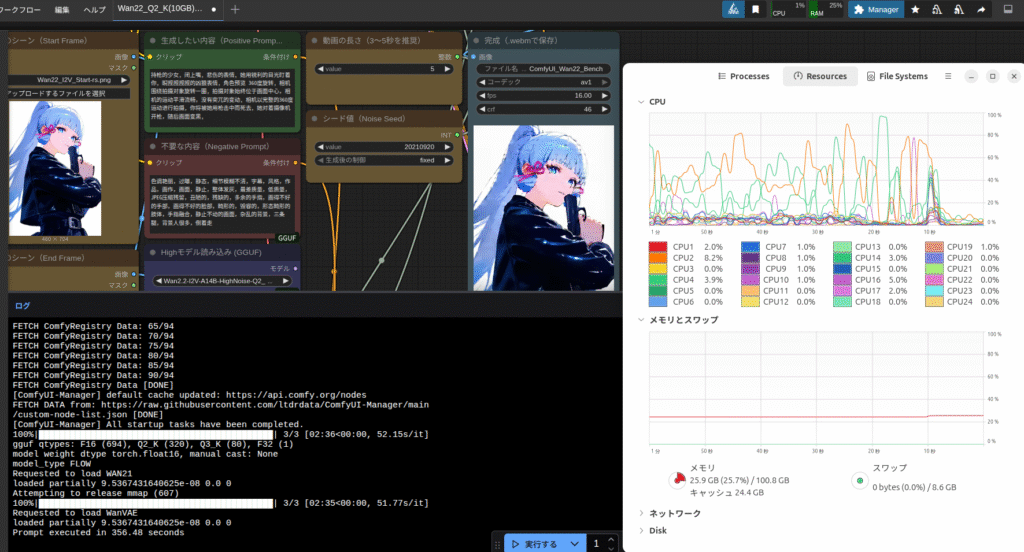
ggufをxpu指定でロードしようとした瞬間にクラッシュするみたいだったので、ロード先をCPUで固定しています。つまりメインメモリに展開しているわけです。
「それならいままでの–novramでいいじゃん」と思っていたのですが、どうも(今回扱った)カスタムノードはComfyUIの起動オプションを受け付けないようでした。
なので、直接CPUでロードしてXPU(つまりARC GPU)で推論する、というふうにコードを書き換えたわけです(ChatGPTが)。
ちなみに手動で書き換えていられるか!って人のために上記リンクから書き換え済みの「pig.py」をダウンロードできるようにしておきました。
元の「pig.py」に上書きすればOKです。
でも、今後のバージョンアップで使えなくなるかもしれません。
メインメモリに展開するので当然オーバーヘッドはVRAMより大きくなるのですが、動画生成の場合は推論で大半の時間をもっていかれるので、致命的に遅くなるほどではなさそうです。
このあたりは人によって感じ方が違うのであまり言いませんが、全てCPUで処理させるよりは断然速いです。
「gguf」は「safetensors」よりぐっと容量が小さいので、メモリの節約になるという話でした。
時間ができたら、メインメモリ展開しなくても良い方法を探してみようと思います。
今回は以上です。
追記
XPUでggufを展開する方法が見つかりました。
こちらで記事にしています。
追記2
コメント