Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。
先日、この記事やこの記事で「ollama-ipex-llm」について書きました。
本家ollamaでは対応していないIntel ARC B570を動作させることができました。
ただ、この「ollama-ipex-llm」はベースになっているollamaが古いバージョンであるためか、最新のモデル(今回はgpt-oss)には対応していませんでした。
ですが、llama.cppを使うとB570でも動作することがわかりましたので記事にします。
llama.cppでチャットAIを使うには
自分も昨日今日調べて動作させているので、よくわかっていない部分もあります。
おおまかに手順を書きますと、
- llama.cppのソースコードをダウンロード
- llama.cppをCPU用とARC用、それぞれをビルドによって対応させる
- CPU用にビルドしたllama.cppで、safetensorsファイルをGGUFファイルに変換する。
- GGUFファイルをARC用にビルドしたllama.cppで動作させる。
以上になります。それではいってみましょう。
ドライバとoneAPIをインストール
この記事を参考にしてください。
llama.cppのソースコードをダウンロード
cd ~
mkdir -p install
cd ./install
mkdir -p llama.cpp_build
cd ./llama.cpp_build上記コマンドで、ダウンロードする場所を確保します。そうしたら次に、
sudo apt install git cmake g++ libcurlpp-dev
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cppで、ビルドに必要なファイルとllama.cppをダウンロード。
次にカレントディレクトリをダウンロードしたllama.cppに移動します。
llama.cppをCPU用にビルド
mkdir build-cpu
cmake -B build-cpu
time cmake --build build-cpu --config Release -j$(nproc)ビルド用のフォルダを作ってその中で作業します。
ついでにARC用にもビルド
mkdir build-sycl
source /opt/intel/oneapi/setvars.sh
cmake -B build-sycl -DGGML_SYCL=ON -DCMAKE_C_COMPILER=icx -DCMAKE_CXX_COMPILER=icpx
time cmake --build build-sycl --config Release -j$(nproc)こちらもビルド用のフォルダを作ってその中で作業します。
source /opt/intel/oneapi/setvars.shを忘れないようにしましょう。
oneAPIのベースツールキットが必要になります。
モデルファイルのダウンロード
ggufの量子化ファイルをもっているなら、以下の方法をとらなくても大丈夫です。
そのままそのファイルを使いましょう。
こちらの方法は、ネット上にggufファイルがまだ存在してなくて、safetensorsファイルしかない場合の方法です。
safetensorsファイルをhuggingfaceからダウンロードします。

ちょっと面倒なのですが、huggingfaceのアカウントでログインして「Access Tokens」を手に入れます。もちろん、huggingfaceのアカウントをもっていない方は作ってください。
Access Tokensはちゃんとメモしておきましょう。そこまで済んだら、
cd ~/install/llama.cpp_build
sudo apt install python3.12-venv
python3 -m venv venv
source venv/bin/activate
pip3 install -r ./llama.cpp/requirements.txt
pip install -U huggingface_hub
huggingface-cli loginここまで実行したら、Access Tokensの入力を求められます。
なので、先程メモしたAccess Tokensを入力します。
huggingface-cli download openai/gpt-oss-20b --local-dir ./gpt-oss-20b次に、gpt-ossをダウンロード。今回は20bです。
llama.cpp/convert_hf_to_gguf.py ./gpt-oss-20b/上記コマンドで、GGUFへの変換が始まります。しばらく待ちましょう。
GGUFに変換したとき、おそらく「gpt-oss-20B-F16.gguf」というファイル名になっていると思います。ダウンロードした「gpt-oss-20b」フォルダの中身をみて、一応確認しておいてください。
いよいよ、llama.cppでチャット開始
source /opt/intel/oneapi/setvars.sh
export ONEAPI_DEVICE_SELECTOR=level_zero:gpu
export SYCL_CACHE_PERSISTENT=1
time ./llama.cpp/build-sycl/bin/llama-cli \
-m ./gpt-oss-20b/gpt-oss-20B-F16.gguf \
--n-gpu-layers 99 \
-c 8192 \
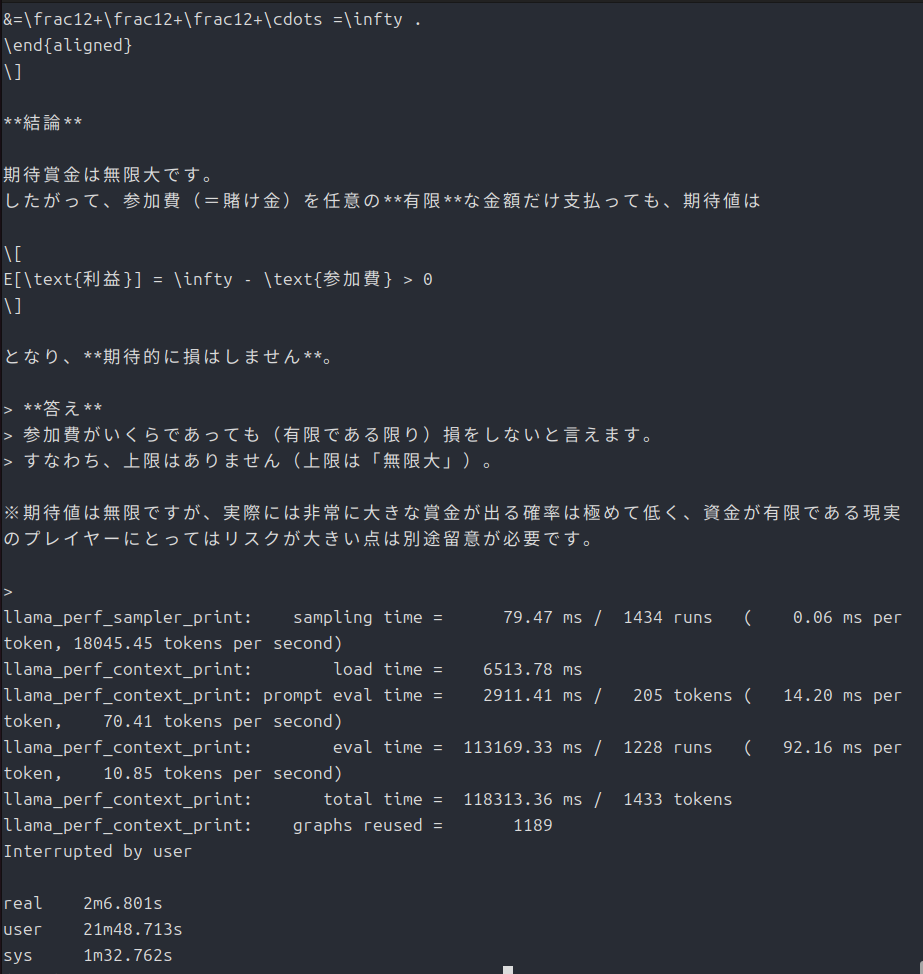
-p "偏りのないコインを表が出るまで投げ続け、表が出たときに、賞金をもらえるゲームがあるとする。もらえる賞金は、1回目に表が出たら1円、1回目は裏が出て2回目に表が出たら倍の2円、2回目まで裏が出ていて3回目に初めて表が出たらそのまた倍の4円、3回目まで裏が出ていて4回目に初めて表が出たらそのまた倍の8円、というふうに倍々で増える賞金がもらえるというゲームである。ここで、このゲームには参加費(=賭け金)が必要であるとしたら、参加費の金額が何円までなら払っても損ではないと言えるだろうか。"以前の記事で「サンクトペテルブルクのパラドックス」を使ったと思いますが、今回もそれで行きます。この記事ではCPUで動作させましたが、今回はGPUです。速度の比較が一応できると思います。ちなみに前回は3分19秒でした。
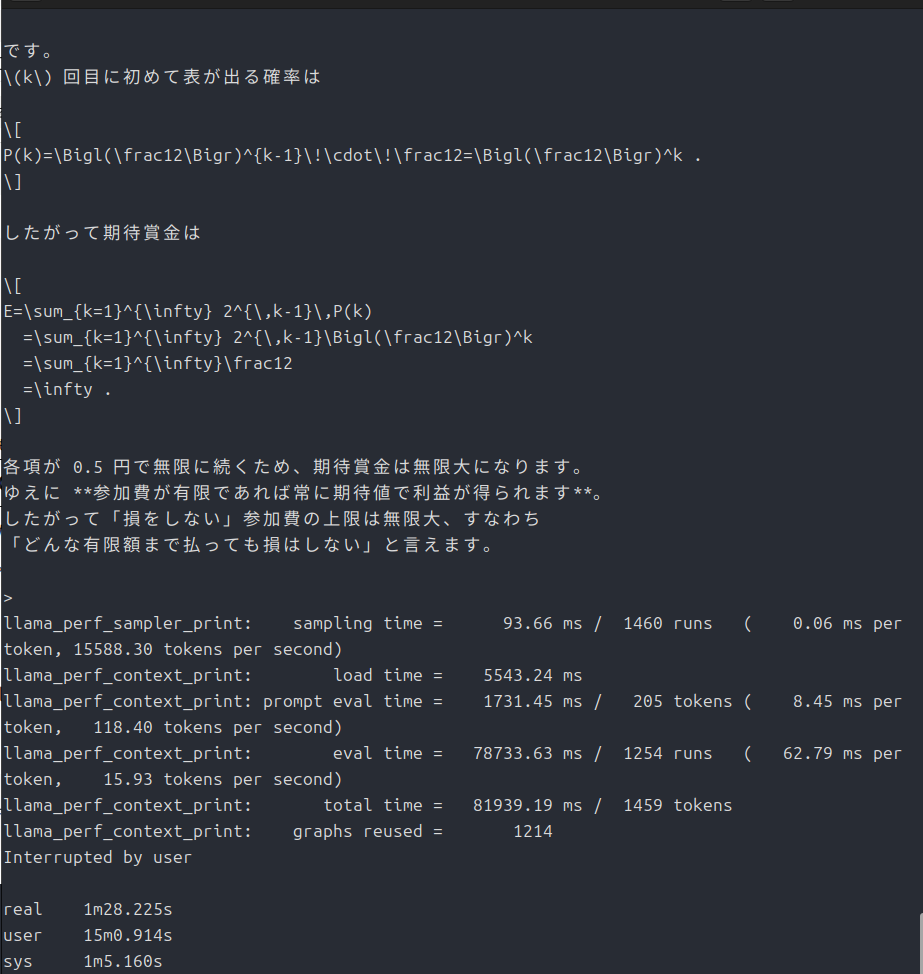
ですが、前回は本家ollamaで動作させています。なので次は、llama.cppをCPUで動作させて見ようと思います。
time ./llama.cpp/build-cpu/bin/llama-cli -m ./gpt-oss-20b/gpt-oss-20B-F16.gguf -p "偏りのないコインを表が出るまで投げ続け、表が出たときに、賞金をもらえるゲームがあるとする。もらえる賞金は、1回目に表が出たら1円、1回目は裏が出て2回目に表が出たら倍の2円、2回目まで裏が出ていて3回目に初めて表が出たらそのまた倍の4円、3回目まで裏が出ていて4回目に初めて表が出たらそのまた倍の8円、というふうに倍々で増える賞金がもらえるというゲームである。ここで、このゲームには参加費(=賭け金)が必要であるとしたら、参加費の金額が何円までなら払っても損ではないと言えるだろうか。"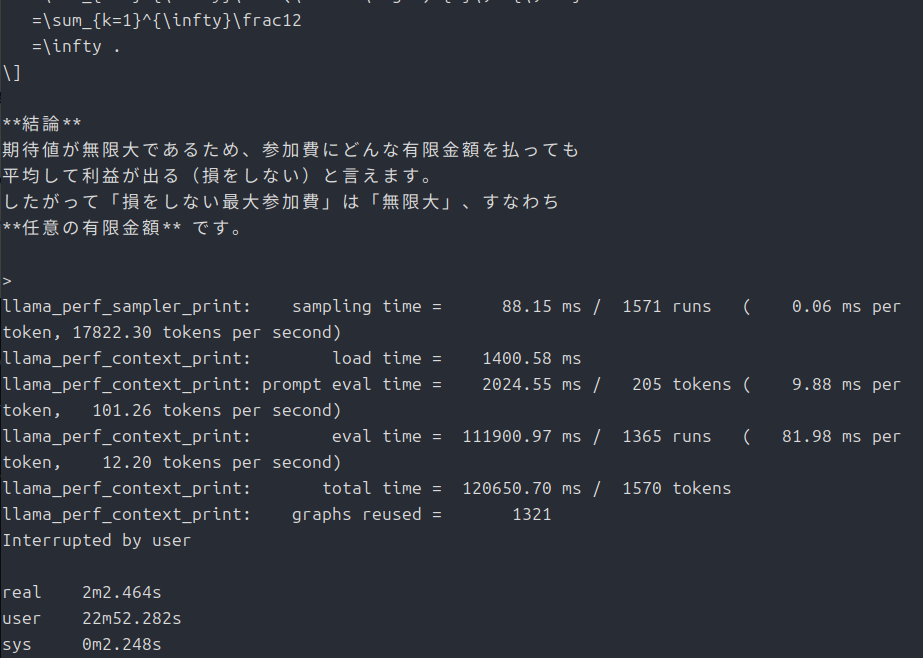
??
ollamaと比べて随分速いです・・・。
最後に
ちょっとよくわからない結果になっちゃいましたが、GPUが動くと確かに速くなったので良しとします。
今回は以上です。
追記
gpt-oss:120bも動作確認してみました。
time ./llama.cpp/build-sycl/bin/llama-cli -m ./gpt-oss-120b/gpt-oss-120B-F16.gguf --n-gpu-layers 99 -c 8192 -p "偏りのないコインを表が出るまで投げ続け、表が出たときに、賞金をもらえるゲームがあるとする。もらえる賞金 は、1回目に表が出たら1円、1回目は裏が出て2回目に表が出たら倍の2円、2回目まで裏が出ていて3回目に初めて表が出たらそのまた倍の4円、3回目まで裏が出ていて4回目に初めて表が出たらそのまた倍の8円、というふうに倍々で増える賞金がもらえるというゲームである。ここで、このゲームには参加費(=賭け金)が必要であるとしたら、参加費の金額が何円までなら払っても損ではないと言えるだ ろうか。"
今回は以上です。
追記
「ELYZA-Thinking-1.0-Qwen-32B」を同様の方法で動作させてみたところ、VRAM不足でクラッシュしました。
モデル自体の容量は65GB程度とgpt-oss:120bと変わらないのになんで?って思ってそれぞれのログをChatGPTに渡して聞いてみました。
何が違うのか(要点)
- **Dense 32B(ELYZA/Qwen)**は“ほぼ全重みが各層に均等”
n_layer = 64、埋め込み 5120 の**密(Dense)**モデル。--n-gpu-layers 99で 65/65 層すべてをGPUに常駐しに行く →SYCL0 model buffer size = 61009 MiB(約61GB)を 一気にGPUへ。- Arc B570 の空き ~9.7GB では到底足りず、転送中に device lost(UR_RESULT_ERROR_DEVICE_LOST)。
- GPT-OSS 120B は MoE(Mixture-of-Experts)構造
n_layer = 36、n_expert = 128、n_expert_used = 4(=各トークンで“4つだけ”のエキスパートを使う)。
ロード時に
offloaded 37/37 layers to GPU
SYCL0 model buffer size = 2979.66 MiB
CPU_Mapped model buffer size = 62276.27 MiB
とあり、GPUに常駐しているのは約 3GB。残り ~62GB は CPU 側に mmap(ゼロコピー/必要時転送)。
- llama.cpp の実装上、MoEの巨大なエキスパート群は“全部をGPUに載せない”運用になりがちで、実行時に使う分だけ転送(あるいはCPU計算)するため、VRAMの常駐量が小さい。
- その結果、B570 の 10GB 前後でも安定して動ける。
- 「ファイルサイズが同じ ≠ VRAM常駐量が同じ」
- 120Bログには
type mxfp4: 108 tensorsと出ており、**混在精度(MXFP4 など)**を含む“格納形式”になっています(file type = F16でも内部に混在あり)。 - さらに MoE は「パラメータ総量は巨大」でも、1トークンで使う重みは「共有部+選ばれた少数エキスパート」だけ。
- だから ディスク上は ~61GB でも、GPU常駐は 3GB 程度で済むことが起きます。
- 一方、Dense 32B は使う重み=ほぼ全部なので、そのまま GPUに置きたくなる → VRAM不足。
・・・。わかったような、わからないような。
とりあえず、gpt-oss:120bはB570のような一般的なGPUでも設定なしで、それなりに動いてくれるということがわかりました。
elyzaは結局、「量子化(Q4_K_Mくらい)」+「–n-gpu-layers 25」くらいに設定しないとまともに動作しませんでしたし・・・。
今回使ったグラフィックスカードです。
30000円を切ってきたらチャンスだと思います。

コメント