前回の記事でollama-ipex-llmを素のままで動作させてみました。
ただ、モデルファイルは5.2GBしかないのでVRAMに十分収まる容量でした。
B570はVRAMは10GBしかありませんので、ollamaで大きなモデルを動作させるにはちょっとした調整が必要です。
ということで、今回は「deepseek-r1:32b」の 19GBにチャレンジしてみます。
ちなみに同様の方法で「deepseek-r1:70b」の42GBの動作も確認しています。
ただ、モデルが大きくなるほどGPUに割り当てる層が少なくなるので、速度向上の影響は少なくなっていきます・・・。
それでは、やっていきましょう。
ドライバとoneAPIのインストール
前回の記事とやり方は同じです。
ollama-ipex-llmのダウンロード
前回の記事とやり方は同じです。
start-ollama.shの書き換え
ollama-ipex-llmのフォルダ内に移動して「start-ollama.sh」を実行するのですが、環境変数の書き換えが必要です。
以下は原文です。
#!/bin/bash
export OLLAMA_NUM_GPU=999
export no_proxy=localhost,127.0.0.1
export ZES_ENABLE_SYSMAN=1
export OLLAMA_KEEP_ALIVE=10m
# [optional] under most circumstances, the following environment variable may improve performance, but sometimes this may also cause performance degradation
export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
export OLLAMA_HOST='127.0.0.1:11434'
# [optional] if you want to run on single GPU, use below command to limit GPU may improve performance
# export ONEAPI_DEVICE_SELECTOR=level_zero:0
# If you have more than one dGPUs, according to your configuration you can use configuration like below, it will use the first and second card.
# export ONEAPI_DEVICE_SELECTOR="level_zero:0;level_zero:1"
./ollama serveこれに変更を加え、以下のように書き換えます。
#!/bin/bash
export OLLAMA_NUM_PARALLEL=1
unset OLLAMA_NUM_GPU #GPUに乗せる層数の自動指定
unset OLLAMA_CONTEXT_LENGTH || true #コンテキストも自動指定
export OLLAMA_FLASH_ATTENTION=1
export OLLAMA_MAX_LOADED_MODELS=1
export no_proxy=localhost,127.0.0.1
export ZES_ENABLE_SYSMAN=1
export OLLAMA_KEEP_ALIVE=10m
export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
export OLLAMA_INTEL_GPU=true
export OLLAMA_HOST='127.0.0.1:11434'
# [optional] if you want to run on single GPU, use below command to limit GPU may improve performance
# export ONEAPI_DEVICE_SELECTOR=level_zero:0
# If you have more than one dGPUs, according to your configuration you can use configuration like below, it will use the first and second card.
# export ONEAPI_DEVICE_SELECTOR="level_zero:0;level_zero:1"
./ollama serve書き換えたら保存して「start-ollama.sh」を実行します。
モデルのダウンロード
「start-ollama.sh」を実行したら、別のターミナルを開いて
ollama pull deepseek-r1:32bでモデルをダウンロードします。
実行テスト
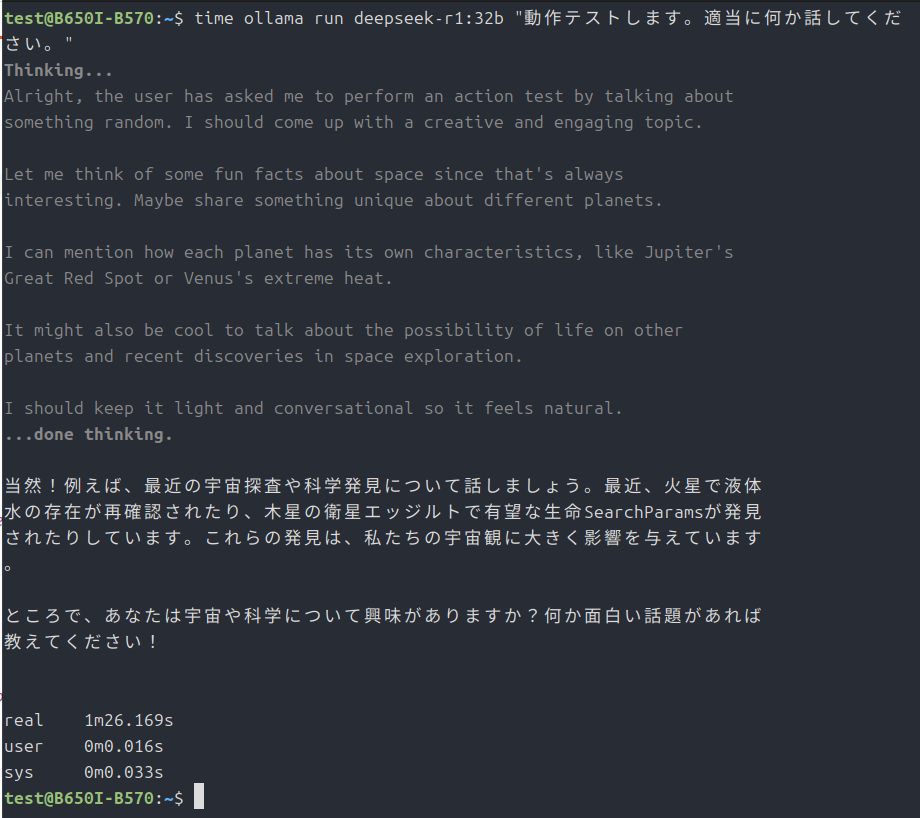
time ollama run deepseek-r1:32b "動作テストします。適当に何か話してください。"で実行テストを開始します。
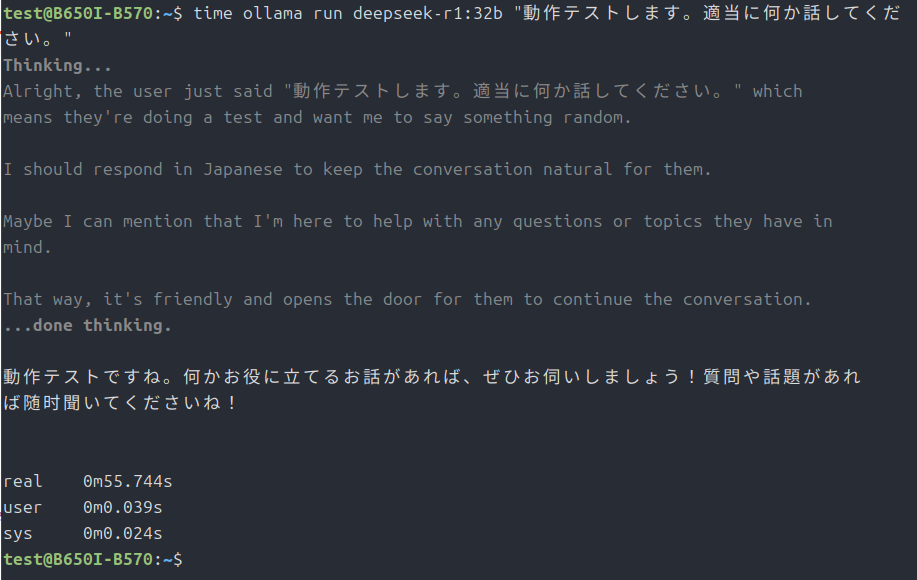
なので、本家ollamaでCPU動作させてみました。
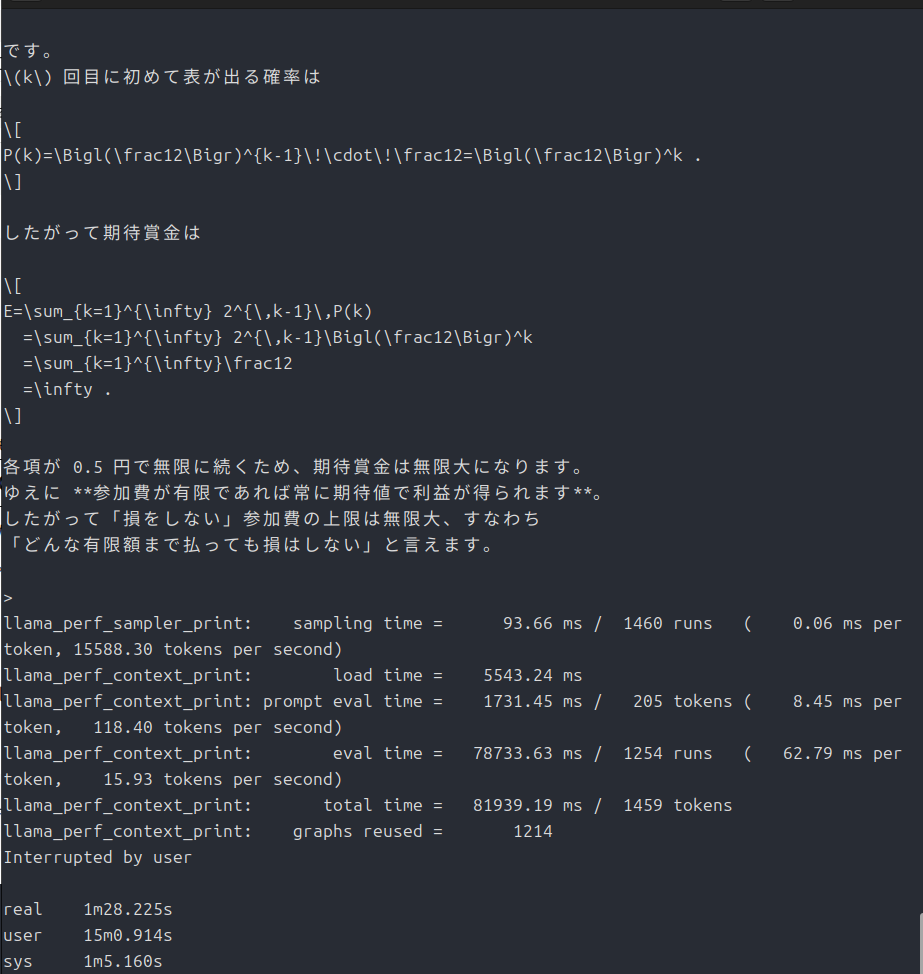
GPUに乗せる層数
通常は起動オプションに「-ngl」以下で数値を指定するらしいのですが、今回は「unset OLLAMA_NUM_GPU」とすることで自動設定するようにしています。
VRAMの多いGPUなら速度もより向上すると思います。
細かく指定したいときは「export OLLAMA_NUM_GPU=24」みたいな感じで詰めていけば良いと思います。
乗り切らなかった層はCPUで処理することになるので、CPUの性能も必要になってくるでしょう。
最後に
今回のテストでは、GPU使用時のB570の消費電力は15W程度となっていました。
つまりほとんど動いていません。
もっと良い環境変数の設定があるのかもしれませんが、自分にはわかりません。
モデル容量が14GBとかだと、同じ設定でも30W〜40Wくらいは使ってくれます。
正直VRAMを超えるモデルを扱うと、処理速度がグッと下がるので、できればよりVRAMの多いGPUがあった方がいいと思いました。
ARC PRO B50が早く出てくれればなぁ・・・。
今回は以上です。
コメント