Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。
はじめに結論から言ってしまいますが、自分が試した範囲では「Intel Arc Pro B60」は12万円の価値はありません。
記事を書いた当初は上のように書きましたが、vLLMの存在を知ってからちょっと認識が変わってきました。
確かに高い性能を感じます。
ただ、他のGPUとのvLLMでの比較ができないのでまだ半信半疑といったところです。
これが「Arc Pro」の付加価値なのか、みなさんの報告があれば評価も定まってくるかもしれませんね。
追記(2026/1/24)
コメントを参考に、vLLMの動作も試してみました。
近いうちに「OpenManus」を使ったAIエージェントの記事も書くつもりです。
追記(2025/12/1)
今まで全然気が付きませんでしたが、推論では「Pro B60」の価値は見出しにくかったですが、学習ならどうでしょう?学習なんて今までやったことはないのでこれから勉強することになりますし、ただの思いつきなのでどうなるかわかりませんが、ちょっと取り組んでみようかと思います。
学習もやってみました。こちらの記事でGPT-SoVITSについて書いています。
やはりVRAMは結構使いますね・・・。
追記(2025/11/25)
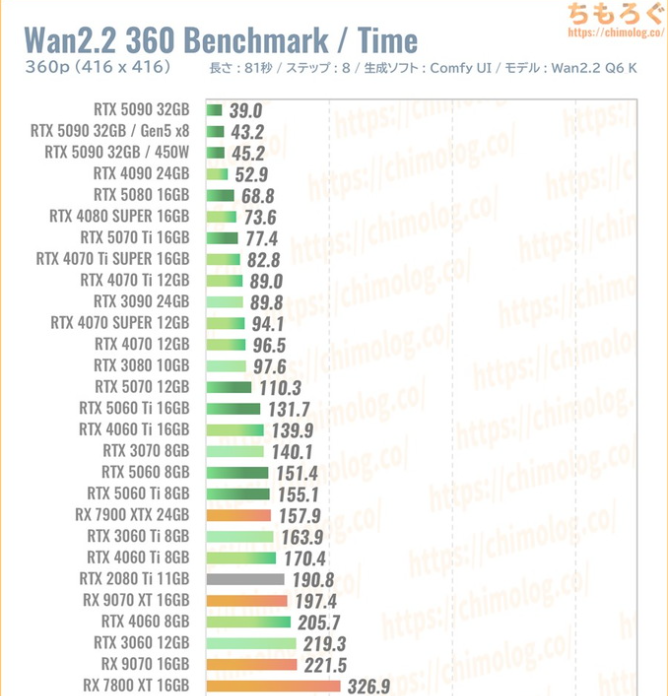
今回の記事で使用させていただいたちもろぐ氏のベンチ結果ですが、「Arc B580でも動く」というニュアンスで受け取ってしまわないよう追記しておきます。
360pのベンチ結果で使用VRAMが17GBを超えていることからもわかるとおり、12GBのB580では満足に動きません。それはちもろぐ氏の検証結果のとおりです。(モデルをQ2_Kに変更すれば360pくらいはいけるかもしれません)。
B60がB580のVRAM増量版だと思ったのは、まだ記事にはしていませんが自分で用意した他のテスト結果から判断したものです。間違えないようお願いします。
追記(2025/12/7)
B580やB570でも動かせるワークフローはこちらの記事で一応紹介しています。
とりあえず、まずは動画生成でテスト
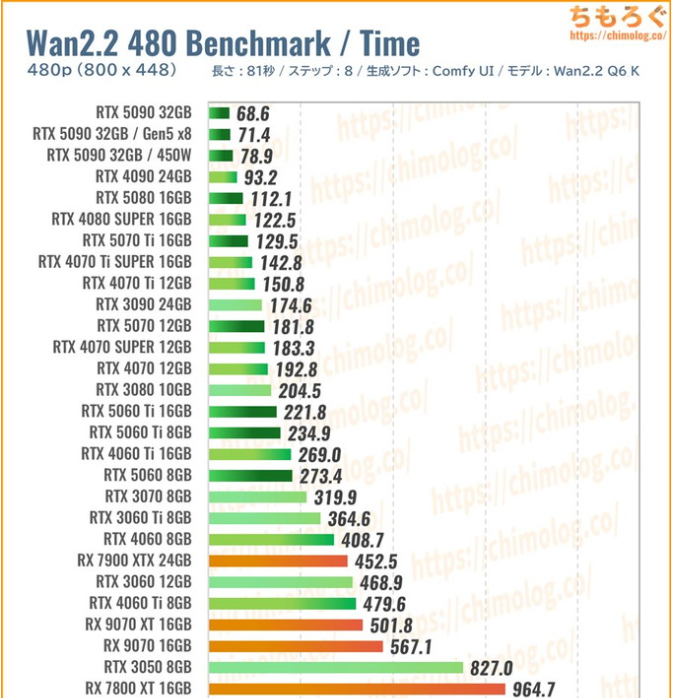
ちもろぐ氏の動画生成ベンチを使わせてもらおうと思います。

以前のArc B570では一番軽いベンチを完走すらできませんでした。
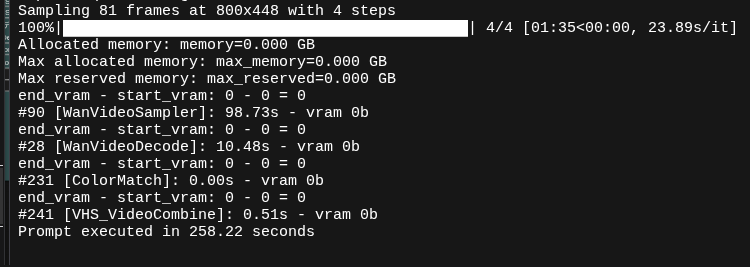
とはいえ、そのままではエラーを吐きまくるのでArcでも走るようにいろいろ変更しています。
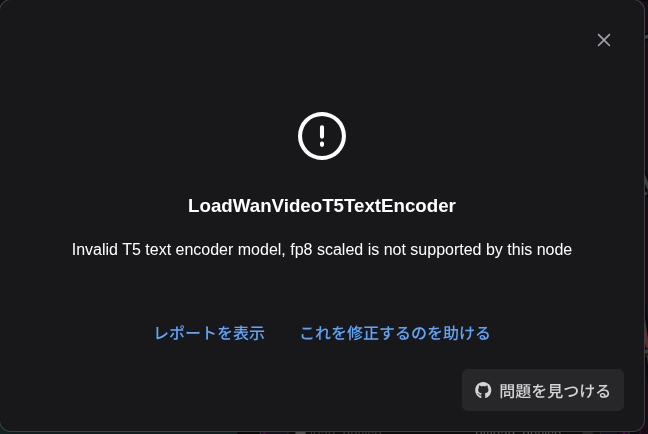
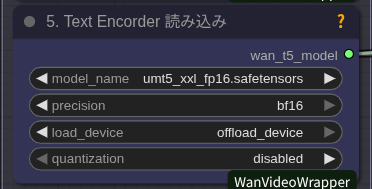

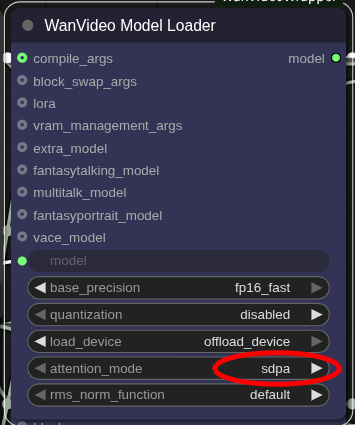
以上で「Arc Pro B60」でも一応走るようになりますが、もう公平な比較ベンチにはなりませんね。ということで参考程度に見てください。
sageattentionがあればもっと速くなるかもしれませんが、仕方ありません。
自分でビルドして解決するなら良いんですがね。
360p
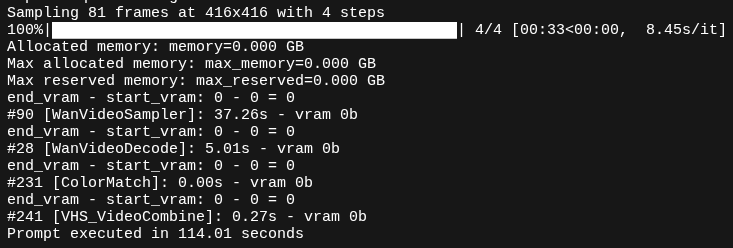
GPUのモニタリングについてはこちらの記事を参考にして下さい。
ちなみに出来上がった動画です。
480p
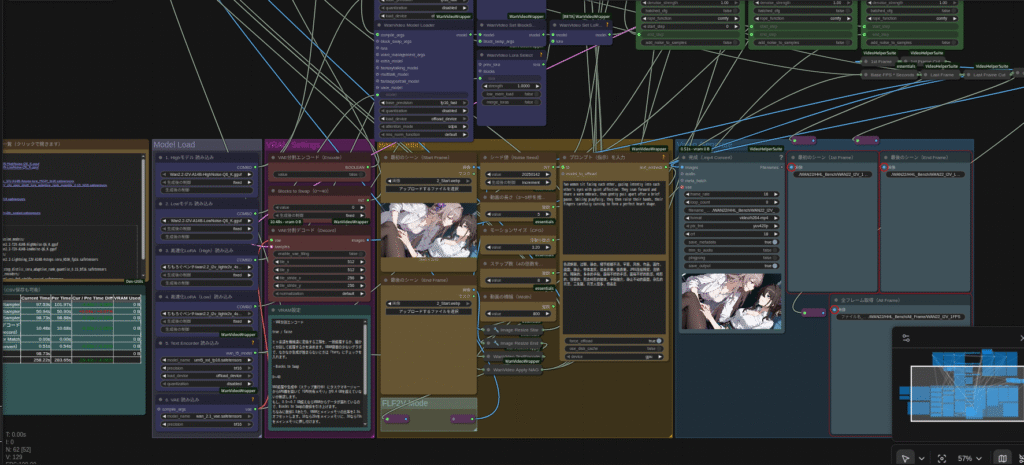
出来上がった動画です。
720p
この後、画面が暗転したりチラついたりとクラッシュ寸前だったので処理を中断しました。
blocks to swapを使えばいけるかなぁって思ったんですが、こちらもエラーで完走しませんでした。
更に「–novram」も試しましたがこのベンチで使われているカスタムノード「WanVideoWrapper」ではVRAM系の起動オプションは受け付けないみたいです。
追記(2025/12/12)
自分でワークフローを作った後、「–novram」でなんとか720pの生成をやってみました。
完全再現はできてませんが、興味がある方はこちらの記事をどうぞ。
最後に
というわけで、動画生成を見ていきました。
Arc B580にVRAMがあったらこのくらいの性能だよね。
あと、生成する解像度が上がってくるとGeForceとの差が広がるみたいですね。
sageattentionの効果でしょうか。
まだ「Arc Pro B60」にはLLMがあるじゃん!
って思った方おられるかもしれませんが・・・、まぁその話は別の記事で。
ところで、この記事をご覧の方は途中気になったことは無かったでしょうか?
ありましたよね?
このカードの写真を載せた記事があったと思うのですが、ブロワーファンです。
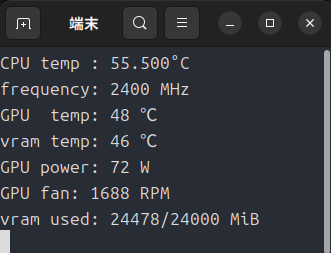
それが3300回転ともなると物凄い轟音になります。
35秒あたりから回転数が上がり始めます。
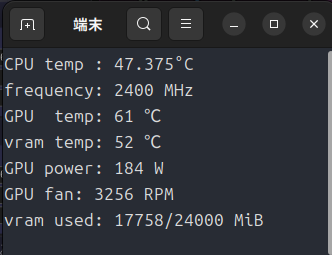
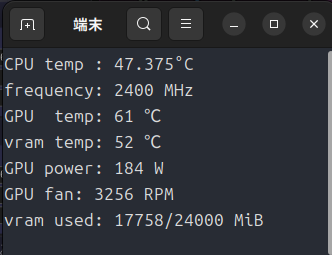
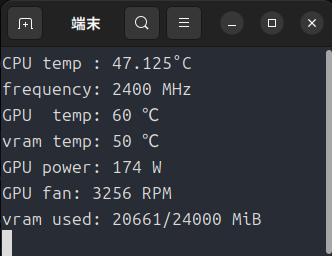
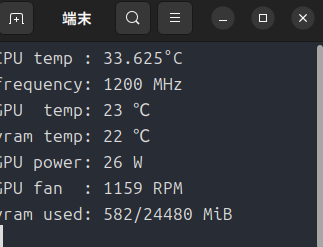
ちなみに負荷がかかっていない状態は下のとおりです。
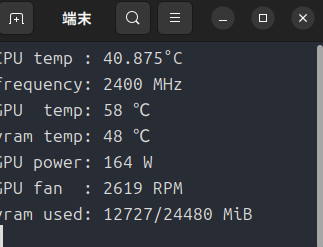
ここから負荷がかかるとGPU温度が上昇し、52℃あたりから回転数が急上昇します。
Windowsならファンコントロールできるかもしれませんが、Ubuntuだと結構困ることになります。(GPU温度が60℃程度ならもっと回転数を絞っても良さそうなものですが・・・。)
こういったソフトもあるのですが、Arc Pro B60の場合はファンコントロールの部分がグレーアウトしてました。
xpu-managerでは電力制限や温度によるパフォーマンスの調整も受付けない状態です。
さて、どうしたものか。
追記(2026/1/9)
(2026/1/25時点での情報)
相変わらず表記が「A60」になっていてアヤシイですが、一応在庫はあるようです。

Sparkleのデュアルファンタイプの在庫が復活しているようですね。
全長240mmと小さいので取り回しも良くオススメです。
負荷中はちょっとうるさいかもしれませんが、B60のブロワーよりははるかにマシでしょう。


コメント
B60、いまちょっと注目しているんですが、LLMでシングルで走らせるとたぶんGeForceとかの方がCuda使えるのでパフォーマンスも良いと思うのですが、AIエージェント作ろうと思うとLLMをマルチで走らせるセッションのパフォーマンスが高い必要が出てくるので、B60ってわりとコスパいいんじゃないかなぁとおもっています。
vLLMとかでOpenManusとかを動かしたときに、どんなものでしょう。gpt-oss 20bとかでも16並列とかで動いたら相当使えそうだと思うのですが。
コメントありがとうございます。
内容についてですが、vLLMもOpenManusも使ったことがなく、どういったものかもよくわかりません。
現在チャットAIを通じて勉強していますが、コメントにある質問には答える知識がありません。ごめんなさい。
たぶんもうご覧になっているかと思いますが、B60を8枚連結で動作させているブログ記事があるようです。
「https://blog.vllm.ai/2025/11/11/intel-arc-pro-b.html」
vLLMを使うとパフォーマンスが劇的に変わったりするものなのでしょうか?
llama.cppをUbuntuで使っている限りですと、RX9060XT16GBの半分のパフォーマンスしか出ません。
Windowsでもトントンといったところです。
YoutubeでLMStudioの検証している方がおられました。
「https://www.youtube.com/watch?v=zhHjRF4KxEM」
とりあえず、時間がとれたらvLLMについて検証してみます。
とりあえずvLLMのベンチマークをチャットAIに相談しながら実行してみました。
4並列
============ Serving Benchmark Result ============
Successful requests: 15
Failed requests: 5
Request rate configured (RPS): 4.00
Benchmark duration (s): 5.00
Total input tokens: 1920
Total generated tokens: 1053
Request throughput (req/s): 3.00
Output token throughput (tok/s): 210.49
Peak output token throughput (tok/s): 489.00
Peak concurrent requests: 12.00
Total token throughput (tok/s): 594.30
—————Time to First Token—————-
Mean TTFT (ms): 84.75
Median TTFT (ms): 81.58
P99 TTFT (ms): 101.73
—–Time per Output Token (excl. 1st token)——
Mean TPOT (ms): 98.77
Median TPOT (ms): 19.06
P99 TPOT (ms): 261.56
—————Inter-token Latency—————-
Mean ITL (ms): 17.51
Median ITL (ms): 15.90
P99 ITL (ms): 59.48
==================================================
8並列
============ Serving Benchmark Result ============
Successful requests: 40
Failed requests: 0
Request rate configured (RPS): 8.00
Benchmark duration (s): 7.10
Total input tokens: 5120
Total generated tokens: 5120
Request throughput (req/s): 5.64
Output token throughput (tok/s): 721.32
Peak output token throughput (tok/s): 1133.00
Peak concurrent requests: 32.00
Total token throughput (tok/s): 1442.64
—————Time to First Token—————-
Mean TTFT (ms): 83.42
Median TTFT (ms): 80.19
P99 TTFT (ms): 130.21
—–Time per Output Token (excl. 1st token)——
Mean TPOT (ms): 22.32
Median TPOT (ms): 23.46
P99 TPOT (ms): 25.11
—————Inter-token Latency—————-
Mean ITL (ms): 22.32
Median ITL (ms): 20.37
P99 ITL (ms): 56.71
==================================================
16並列
============ Serving Benchmark Result ============
Successful requests: 64
Failed requests: 0
Request rate configured (RPS): 16.00
Benchmark duration (s): 7.83
Total input tokens: 8192
Total generated tokens: 8192
Request throughput (req/s): 8.17
Output token throughput (tok/s): 1046.24
Peak output token throughput (tok/s): 1780.00
Peak concurrent requests: 64.00
Total token throughput (tok/s): 2092.48
—————Time to First Token—————-
Mean TTFT (ms): 157.52
Median TTFT (ms): 152.05
P99 TTFT (ms): 261.61
—–Time per Output Token (excl. 1st token)——
Mean TPOT (ms): 36.56
Median TPOT (ms): 37.62
P99 TPOT (ms): 42.00
—————Inter-token Latency—————-
Mean ITL (ms): 36.56
Median ITL (ms): 30.53
P99 ITL (ms): 114.82
==================================================
これがどのような性能なのかさっぱりわかりませんが、どうでしょうか?ちなみに今コマンドは、
「# 16並列
vllm bench serve \
–backend vllm \
–base-url http://localhost:8000 \
–model openai/gpt-oss-20b \
–dataset-name random \
–random-input-len 128 \
–random-output-len 128 \
–num-prompts 64 \
–request-rate 16」 のような感じです。
4並列の結果がちょっと変だったのでやり直してみました。
「============ Serving Benchmark Result ============
Successful requests: 20
Failed requests: 0
Request rate configured (RPS): 4.00
Benchmark duration (s): 6.63
Total input tokens: 2560
Total generated tokens: 2560
Request throughput (req/s): 3.02
Output token throughput (tok/s): 386.19
Peak output token throughput (tok/s): 611.00
Peak concurrent requests: 13.00
Total token throughput (tok/s): 772.38
—————Time to First Token—————-
Mean TTFT (ms): 66.01
Median TTFT (ms): 63.39
P99 TTFT (ms): 91.95
—–Time per Output Token (excl. 1st token)——
Mean TPOT (ms): 14.81
Median TPOT (ms): 14.01
P99 TPOT (ms): 17.93
—————Inter-token Latency—————-
Mean ITL (ms): 14.81
Median ITL (ms): 13.02
P99 ITL (ms): 43.65
==================================================
」