以前の記事でwhisperを使って音声ファイルの文字起こしをしましたが、30分の音声ファイルで40分以上かかっていました。
これは、whisperがcudaで動作するよう作られていたため、cudaを搭載していない自分のPCではCPU処理に切り替わっていることが原因でした。
今回は、whisperをROCmで動作させ、もうちょっと高速化を狙っていきます。
では、いってみましょう。
ROCmとffmpegの準備
ROCmのインストール方法はこちらの記事の「ROCmのインストール」を参考にしてください。
ffmpegは今回も「sudo apt install ffmpeg」で済ませます。
最新版のffmpegを自前でビルドしたいという方はこちらの記事を参考にしてください。
whisperの準備
sudo apt install -y git
sudo apt install ffmpeg #自前でビルドした場合はこの行はコメントアウトしてください。
sudo apt install -y python3-venv
cd ~
cd install
git clone https://github.com/openai/whisper.git
cd whisper
python3 -m venv venv
source venv/bin/activate
pip3 install --pre torch torchvision --index-url https://download.pytorch.org/whl/nightly/rocm7.0
pip install -U pip setuptools
pip install . 基本的には以前の記事と同じです。
「pip install -r requirements.txt」が無いくらいです。
ROCmはnightlyを使っていますが、お気に入りのバージョンがあればそちらを使ってください。
以上で準備は終わり
後は以前の記事と同じです。
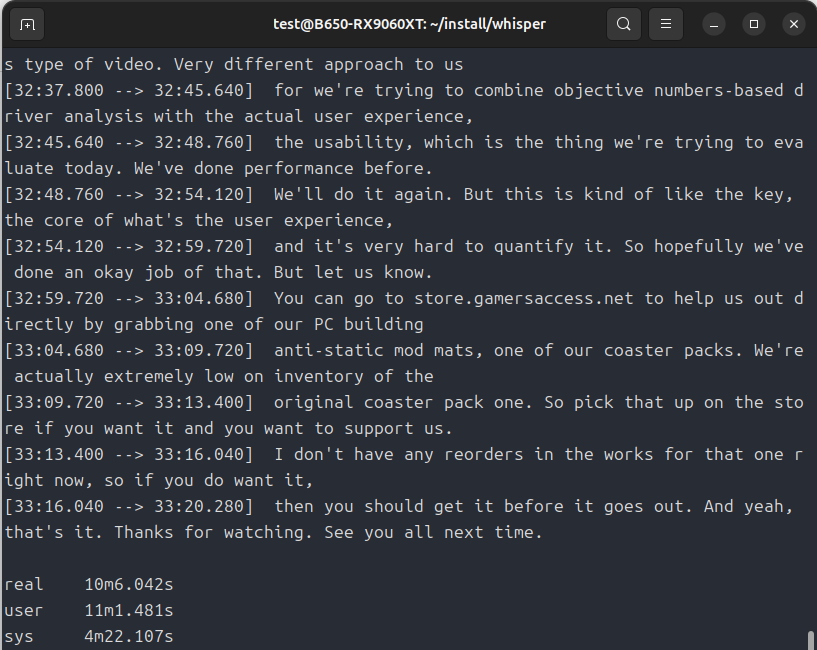
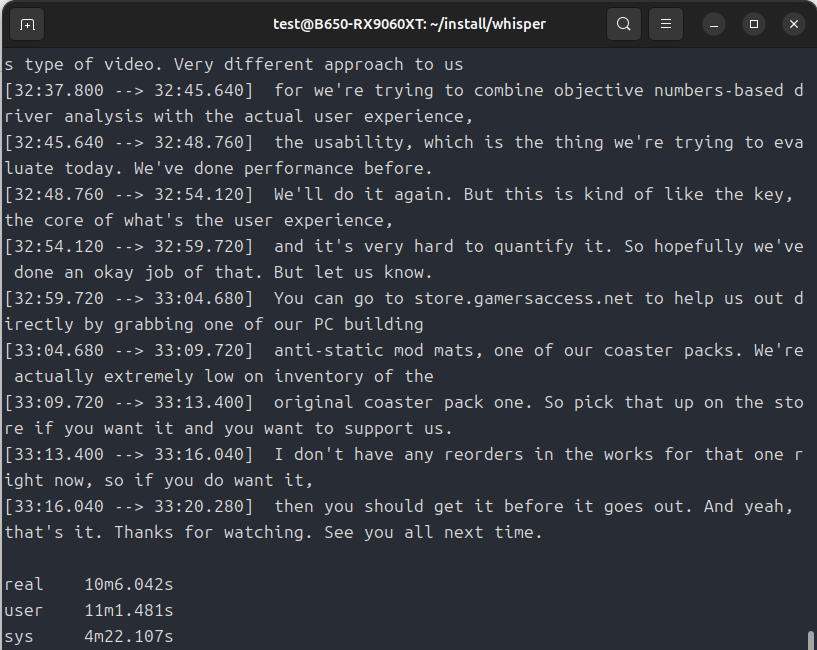
それでは動作速度をみてみましょう。
最後に
ROCmで動作させるとずいぶんと高速化しました。
モデルファイルも「turbo」を使うともっと速くなります。
興味のある方はいろいろ試してみてください。
今回は以上です。

コメント