Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。
以前の記事で「ゼロショットTTS」を使って音声を生成しましたが、これは生成に使っている学習モデルはすでに用意されているものを使いました。
今回は、1〜2分の音声をIntel Arcを使って学習させてから音声を生成してみます。
今回も「Ubuntu日和」の記事を参考にしています。
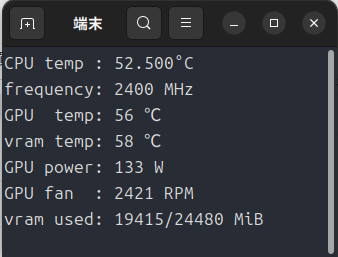
学習用途では「Arc Pro B60」は24GBもの大容量のVRAMをうまく利用することができるでしょうか?
それでは、やっていきましょう!
追記
今回の記事は「Intel Arc」用です。
「GeForce」と「Radeon」は本家GPT-SoVITSを使いましょう。
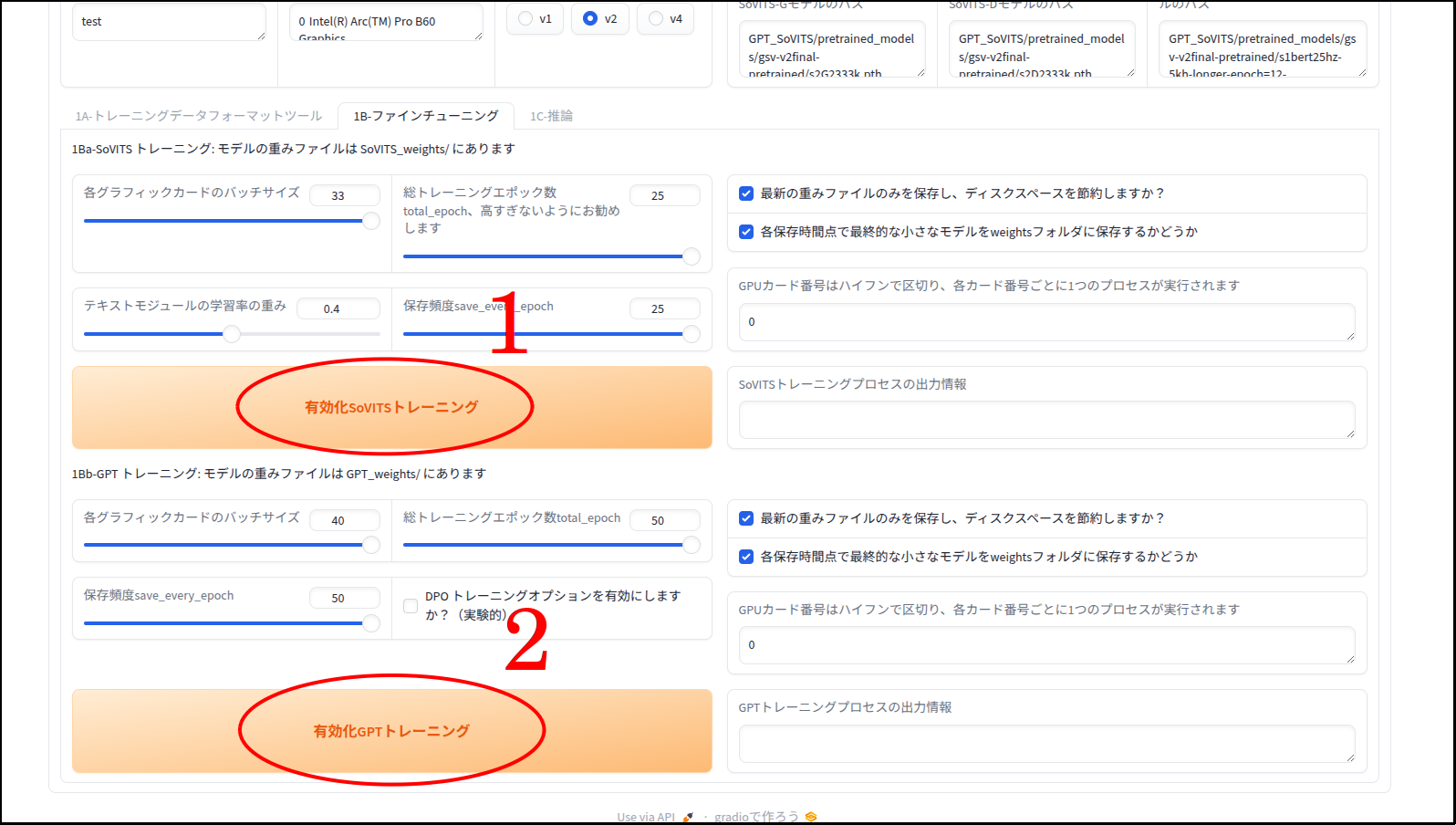
「GPTトレーニング」と「SoVITSトレーニング」について
「数ショットTTS」では「GPTトレーニング」と「SoVITSトレーニング」のふたつを行いますが、「GPT-SoVITS-For-Intel」をそのまま使っても動作自体はします。ただし「SoVITSトレーニング」の方の処理がCPUにフォールバックされて遅くなってしまいます。
これは、とてももったいないのでGeminiとケンカしながら、ふたつともXPUで動作するようソースコードを改造したpythonスクリプトを用意しました。あとで書いておきますね。
以下、「GPTトレーニング」と「SoVITSトレーニング」の違いをGeminiに教えてもらいました。
| 比較項目 | GPTトレーニング | SoVITSトレーニング |
| 担当要素 | 抑揚・リズム・間(話し方) | 音色・質感(声そのもの) |
| 主な入力 | テキスト(音素) | 中間トークン(セマンティック) |
| 主な出力 | 中間トークン | 最終的な音声波形 |
| 失敗した時の症状 | 棒読みになる、不自然な場所で切れる | 声がカサカサする、別人の声になる |
GPT-SoVITS-For-Intelを学習用としてインストール
#!/bin/bash
#インストールに必要なライブラリ等をインストール
sudo apt update
sudo apt install git
sudo apt install curl
sudo apt install build-essential cmake
# uvをcurlでインストール
curl -LsSf https://astral.sh/uv/install.sh | sh
source $HOME/.local/bin/env
#GPT-SoVITS-For-Intelのインストール
cd ~
mkdir -p install
cd install
git clone https://github.com/IzayoiSakuya16/GPT-SoVITS-For-Intel.git
cd GPT-SoVITS-For-Intel
#uvでpython3.10環境を作る
uv venv --python 3.10 --seed
# uv環境を有効化
source .venv/bin/activate
#IPEXのインストール(torch.xpuではありません)
python -m pip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0 --index-url https://download.pytorch.org/whl/xpu
python -m pip install intel-extension-for-pytorch==2.8.10+xpu --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
python -m pip install oneccl_bind_pt==2.8.0+xpu --index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
#音声データの文字起こしをするため「faster_whisper」をuv環境にインストール
uv pip install faster_whisper
# 「GPT-SoVITS-For-Intel」のrequirements.txtを実行
uv pip install -r requirements.txt
#モデルファイルのダウンロードと配置(git-lfs)
sudo apt install git-lfs
git lfs install
cd ~/install/GPT-SoVITS-For-Intel/GPT_SoVITS/pretrained_models/
git clone https://huggingface.co/lj1995/GPT-SoVITS
cp -r GPT-SoVITS/* .
#configファイルの配置(「GPT-SoVITS-For-Intel」には何故かこれらのファイルが存在しませんので、本家から拝借しています)
cd ~/install/GPT-SoVITS-For-Intel/GPT_SoVITS/configs/
git clone https://github.com/RVC-Boss/GPT-SoVITS.git
cd GPT-SoVITS/GPT_SoVITS
cp -r configs/* ~/install/GPT-SoVITS-For-Intel/GPT_SoVITS/configs/
cd ~/install//GPT-SoVITS-For-Intel最近はWindows11のゴタゴタがあって、Linuxに移行する人も増えてきているらしいですね。
自分は大したレベルではありませんが、bashを使えばインストールはとても楽になるので、是非使って欲しいと思います。
最近はチャットAIの普及でそのへんのハードルはグッと下がってきましたし。
追記
前回の記事でGPT-SoVITS-For-Intelをインストールされた方がもしいらっしゃいましたら、今回のスクリプトでインストールし直してください。
いろいろ足りないファイルなどを追加でインストールする仕組みになっています。
「SoVITSトレーニング」をXPUで動かす「s2_train.py」の作成
以下のスクリプトを「s2_train.py」として保存しておいてください。
あとで「GPT-SoVITS-For-Intel/GPT_SoVITS」の中にある「s2_train.py」と差し替えます。
import warnings
warnings.filterwarnings("ignore")
import os
import utils
import logging
import torch
import pathlib
import torch.distributed as dist
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdm
from random import randint
# PyTorch 2.6+ セキュリティ対策
torch.serialization.add_safe_globals([pathlib.PosixPath])
# --- Intel GPU (IPEX) 対応 ---
try:
import intel_extension_for_pytorch as ipex
except ImportError:
pass
from torch.amp import autocast
def get_grad_scaler(device_type, enabled):
try:
return torch.amp.GradScaler(device_type, enabled=enabled)
except:
return torch.cuda.amp.GradScaler(enabled=enabled)
# ----------------------------
from module import commons
from module.data_utils import (
DistributedBucketSampler,
TextAudioSpeakerCollate,
TextAudioSpeakerLoader,
)
from module.losses import discriminator_loss, feature_loss, generator_loss, kl_loss
from module.mel_processing import mel_spectrogram_torch, spec_to_mel_torch
from module.models import (
MultiPeriodDiscriminator,
SynthesizerTrn,
)
from process_ckpt import savee
logging.getLogger("matplotlib").setLevel(logging.INFO)
logging.getLogger("h5py").setLevel(logging.INFO)
logging.getLogger("numba").setLevel(logging.INFO)
hps = utils.get_hparams(stage=2)
os.environ["CUDA_VISIBLE_DEVICES"] = hps.train.gpu_numbers.replace("-", ",")
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = False
torch.set_float32_matmul_precision("medium")
global_step = 0
device_type = "xpu" if torch.xpu.is_available() else ("cuda" if torch.cuda.is_available() else "cpu")
def main():
# --- 安定化の核心: マルチプロセスを使わず直接 run を呼ぶ ---
n_gpus = 1
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = str(randint(20000, 55555))
run(0, n_gpus, hps)
def run(rank, n_gpus, hps):
global global_step
curr_device = f"{device_type}:{rank}" if device_type != "cpu" else "cpu"
if rank == 0:
logger = utils.get_logger(hps.data.exp_dir)
writer = SummaryWriter(log_dir=hps.s2_ckpt_dir)
writer_eval = SummaryWriter(log_dir=os.path.join(hps.s2_ckpt_dir, "eval"))
# 通信の初期化(シングルプロセスでも DDP 互換のために必要)
dist.init_process_group(backend="gloo", init_method="env://?use_libuv=False", world_size=n_gpus, rank=rank)
torch.manual_seed(hps.train.seed)
if device_type == "xpu": torch.xpu.set_device(rank)
elif device_type == "cuda": torch.cuda.set_device(rank)
train_dataset = TextAudioSpeakerLoader(hps.data)
train_sampler = DistributedBucketSampler(train_dataset, hps.train.batch_size, [32, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900], num_replicas=n_gpus, rank=rank, shuffle=True)
train_loader = DataLoader(train_dataset, num_workers=6, shuffle=False, pin_memory=True, collate_fn=TextAudioSpeakerCollate(), batch_sampler=train_sampler, persistent_workers=True, prefetch_factor=4)
net_g = SynthesizerTrn(hps.data.filter_length // 2 + 1, hps.train.segment_size // hps.data.hop_length, n_speakers=hps.data.n_speakers, **hps.model).to(curr_device)
net_d = MultiPeriodDiscriminator(hps.model.use_spectral_norm).to(curr_device)
# Optimizer
te_p = list(map(id, net_g.enc_p.text_embedding.parameters())); et_p = list(map(id, net_g.enc_p.encoder_text.parameters())); mrte_p = list(map(id, net_g.enc_p.mrte.parameters()))
base_params = filter(lambda p: id(p) not in te_p + et_p + mrte_p and p.requires_grad, net_g.parameters())
optim_g = torch.optim.AdamW([{"params": base_params, "lr": hps.train.learning_rate}, {"params": net_g.enc_p.text_embedding.parameters(), "lr": hps.train.learning_rate * hps.train.text_low_lr_rate}, {"params": net_g.enc_p.encoder_text.parameters(), "lr": hps.train.learning_rate * hps.train.text_low_lr_rate}, {"params": net_g.enc_p.mrte.parameters(), "lr": hps.train.learning_rate * hps.train.text_low_lr_rate}], hps.train.learning_rate, betas=hps.train.betas, eps=hps.train.eps)
optim_d = torch.optim.AdamW(net_d.parameters(), hps.train.learning_rate, betas=hps.train.betas, eps=hps.train.eps)
# ロード処理
try:
_, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path("%s/logs_s2_%s" % (hps.data.exp_dir, hps.model.version), "D_*.pth"), net_d, optim_d)
_, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path("%s/logs_s2_%s" % (hps.data.exp_dir, hps.model.version), "G_*.pth"), net_g, optim_g)
epoch_str += 1; global_step = (epoch_str - 1) * len(train_loader)
except:
epoch_str = 1; global_step = 0
if hps.train.pretrained_s2G: net_g.load_state_dict(torch.load(hps.train.pretrained_s2G, map_location="cpu")["weight"], strict=False)
if hps.train.pretrained_s2D: net_d.load_state_dict(torch.load(hps.train.pretrained_s2D, map_location="cpu")["weight"])
scheduler_g = torch.optim.lr_scheduler.ExponentialLR(optim_g, gamma=hps.train.lr_decay, last_epoch=-1)
scheduler_d = torch.optim.lr_scheduler.ExponentialLR(optim_d, gamma=hps.train.lr_decay, last_epoch=-1)
for _ in range(epoch_str): scheduler_g.step(); scheduler_d.step()
scaler = get_grad_scaler(device_type, enabled=hps.train.fp16_run)
print(f"start training on {curr_device} from epoch {epoch_str}")
for epoch in range(epoch_str, hps.train.epochs + 1):
train_and_evaluate(rank, epoch, hps, [net_g, net_d], [optim_g, optim_d], [scheduler_g, scheduler_d], scaler, [train_loader, None], logger if rank==0 else None, [writer, writer_eval] if rank==0 else None, curr_device)
scheduler_g.step(); scheduler_d.step()
# --- 保存処理 (必ずこのループの中にインデントして入れる必要があります) ---
if rank == 0 and epoch % hps.train.save_every_epoch == 0:
save_path = os.path.join(hps.data.exp_dir, f"logs_s2_{hps.model.version}")
os.makedirs(save_path, exist_ok=True)
utils.save_checkpoint(net_g, optim_g, hps.train.learning_rate, epoch, os.path.join(save_path, f"G_{global_step if hps.train.if_save_latest==0 else 233333333333}.pth"))
if hps.train.if_save_every_weights:
target_model = net_g.module if hasattr(net_g, 'module') else net_g
ckpt = target_model.state_dict()
savee(ckpt, hps.name + f"_e{epoch}_s{global_step}", epoch, global_step, hps)
def train_and_evaluate(rank, epoch, hps, nets, optims, schedulers, scaler, loaders, logger, writers, curr_device):
net_g, net_d = nets; optim_g, optim_d = optims; train_loader, _ = loaders
if writers: writer, writer_eval = writers
train_loader.batch_sampler.set_epoch(epoch)
global global_step
net_g.train(); net_d.train()
for batch_idx, (ssl, ssl_lengths, spec, spec_lengths, y, y_lengths, text, text_lengths) in enumerate(tqdm(train_loader)):
spec, spec_lengths = spec.to(curr_device, non_blocking=True), spec_lengths.to(curr_device, non_blocking=True)
y, y_lengths = y.to(curr_device, non_blocking=True), y_lengths.to(curr_device, non_blocking=True)
ssl = ssl.to(curr_device, non_blocking=True)
text, text_lengths = text.to(curr_device, non_blocking=True), text_lengths.to(curr_device, non_blocking=True)
with autocast(device_type=device_type, enabled=hps.train.fp16_run):
y_hat, kl_ssl, ids_slice, x_mask, z_mask, (z, z_p, m_p, logs_p, m_q, logs_q), stats_ssl = net_g(ssl, spec, spec_lengths, text, text_lengths)
spec_sliced = commons.slice_segments(spec, ids_slice, hps.train.segment_size // hps.data.hop_length)
y_mel = spec_to_mel_torch(spec_sliced, hps.data.filter_length, hps.data.n_mel_channels, hps.data.sampling_rate, hps.data.mel_fmin, hps.data.mel_fmax)
y_hat_mel = mel_spectrogram_torch(y_hat.squeeze(1), hps.data.filter_length, hps.data.n_mel_channels, hps.data.sampling_rate, hps.data.hop_length, hps.data.win_length, hps.data.mel_fmin, hps.data.mel_fmax)
y_sliced = commons.slice_segments(y, ids_slice * hps.data.hop_length, hps.train.segment_size)
y_d_hat_r, y_d_hat_g, _, _ = net_d(y_sliced, y_hat.detach())
with autocast(device_type=device_type, enabled=False):
loss_disc, _, _ = discriminator_loss(y_d_hat_r, y_d_hat_g)
optim_d.zero_grad()
scaler.scale(loss_disc).backward()
scaler.unscale_(optim_d)
scaler.step(optim_d)
with autocast(device_type=device_type, enabled=hps.train.fp16_run):
y_d_hat_r, y_d_hat_g, fmap_r, fmap_g = net_d(y_sliced, y_hat)
with autocast(device_type=device_type, enabled=False):
loss_mel = F.l1_loss(y_mel, y_hat_mel) * hps.train.c_mel
loss_kl = kl_loss(z_p, logs_q, m_p, logs_p, z_mask) * hps.train.c_kl
loss_fm = feature_loss(fmap_r, fmap_g)
loss_gen, _ = generator_loss(y_d_hat_g)
loss_gen_all = loss_gen + loss_fm + loss_mel + kl_ssl + loss_kl
optim_g.zero_grad()
scaler.scale(loss_gen_all).backward()
scaler.unscale_(optim_g)
scaler.step(optim_g)
scaler.update()
if rank == 0 and global_step % hps.train.log_interval == 0:
logger.info(f"Epoch: {epoch} Step: {global_step} Loss: {loss_gen_all.item():.4f}")
global_step += 1
if __name__ == "__main__":
main()必要なもの
- 1〜2分の音声ファイル(自分はmp3にしました)
- こちらの記事で使った3〜10秒の音声ファイル
- 3〜10秒の音声ファイルのテキスト
- 学習で作ったモデルに喋らせる適当なテキスト(今回も恥ずかしいポエムを使います)
注意点です。3〜10秒の音声ファイルですが、
この音声ファイルを例にしますが、テキストにすると
私はとある男のUbuntuというブログの管理人をしています。になりますが、よく聞くと
私は、とある男のUbuntuという、ブログの管理人をしています。という感じで息継ぎのような「間」が存在します。
このようにできるだけ正確にテキストを作ったほうが再現性が高くなるようです。
1〜2分の音声ファイルですが、自分は今回は以下のテキストを自分で読み上げて録音しています。
ルドルフ一世の死とともに、帝国の各地で共和主義者による叛乱が続発した。ルドルフの指導力と個性を喪失したいま、帝国はすぐにも崩壊するものと思われたのだが、それは楽観的にすぎた。ルドルフが40年の歳月をかけ、腹心として育成した貴族、軍隊、官僚の三位一体体制は、共和主義者たちの希望的観測よりはるかに強固であったのだ。
それを統率したのは皇父であり帝国宰相であったノイエ・シュタウフェン公ヨアヒムである。彼はルドルフが婿としてえらんだ人物だけあって沈着冷静な指導力を発揮し、もともと劣勢であった叛乱軍を、卵の殻でも踏みつけるように粉砕した。
叛乱に参加した5億余人が殺され、その家族など100億人以上が市民権を剥奪されて農奴階級におとされた。反対勢力を圧殺するに仮借するなかれ、との帝国の国是は忠実に遵守されたのである。
共和主義者たちはふたたび冬の時代をたえねばならなかった。
強力な専制政治の前に、厳しい冬は永遠に続くかと思われた。ヨアヒムの死後、シギスムントが親政をおこない、その没後を長子リヒャルトが継ぎ、その後に長子オトフリートが立った。至高の権力をえるのはルドルフの子孫にかぎられ、世襲だけが権力の移動のあるべき姿になったかにみえた。「銀河英雄伝説①黎明編 田中芳樹著」の一節から拝借(多分途中で漢字の読み間違いがあります)。
読み上げに90秒ほどかかっていますが、後の「ノイズ除去(これはやらなくてもいいのですが)」処理でいくらか短くなる可能性がありますので、60秒ちょうどのファイルだと、学習に足りなくなるかもしれません。
ちょっと余裕をみて録音しましょう。
「s2_train.py」差し替え
「GPT-SoVITS-For-Intel/GPT_SoVITS」の中にある「s2_train.py」と先程作ったファイルと差し替えます。
ついでに1〜2分の音声ファイル(今回は「output.mp3」)も入れてしまいます。
終わったら、
cd ~/install/GPT-SoVITS-For-Intel
source .venv/bin/activate
python ./webui.pyで起動します。
「GPT-SoVITS-For-Intel」の操作手順
では、これからWebUIでの操作手順の説明をしますが、
- 1〜2分の音声ファイルを数秒ごとのデータに分割する
- 各データのノイズを除去する
- 各データごとに発言内容を記載したラベルデータを作成する
- トレーニング用のメタデータを作成する
- データからSoVITSのトレーニングを行なう
- データからGPTのトレーニングを行なう
以上の流れになります。
面倒くさそうですが、WebUIの上から順番に実行していくだけです。
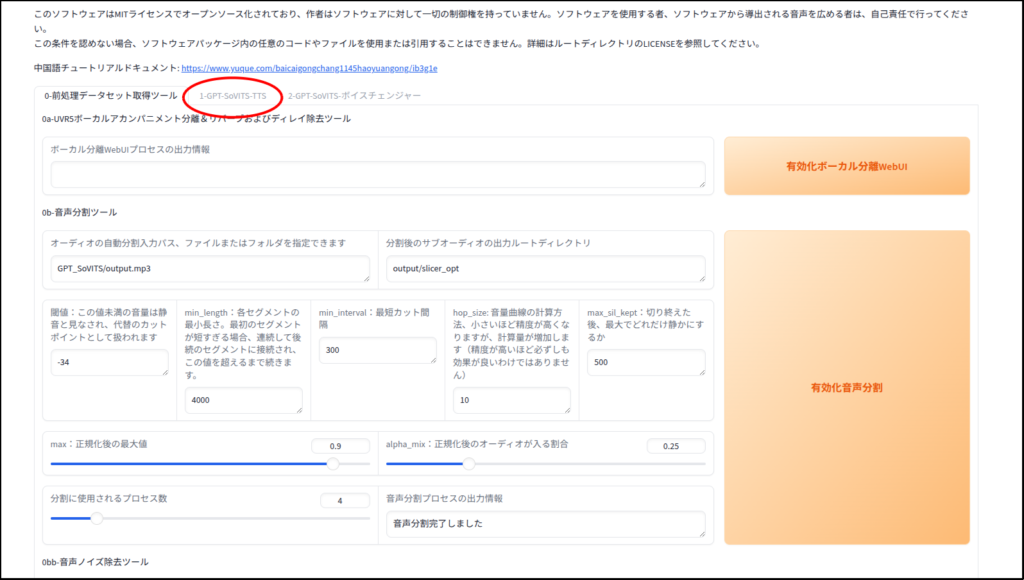
まずは音声ファイルの分割と文字起こし
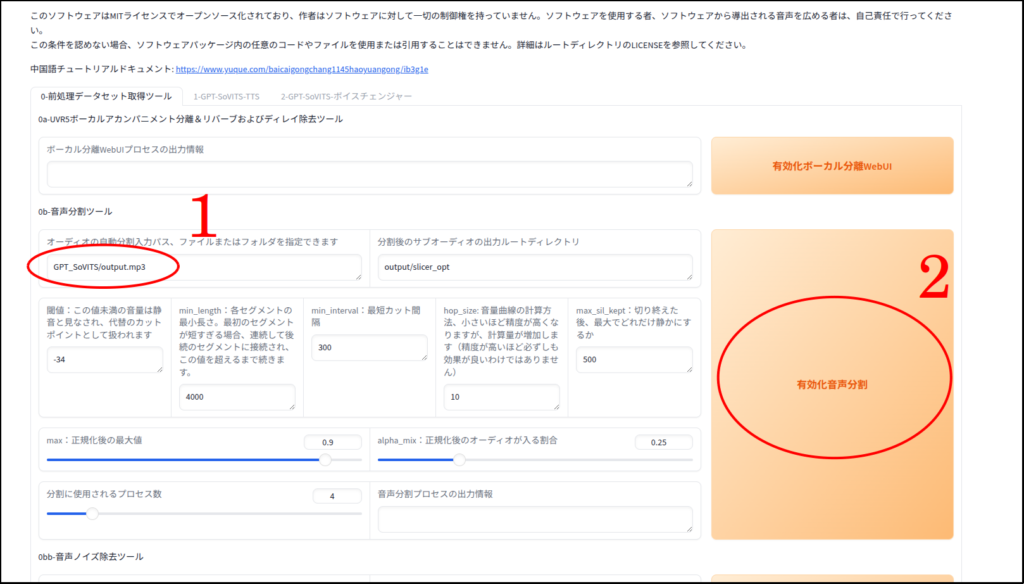
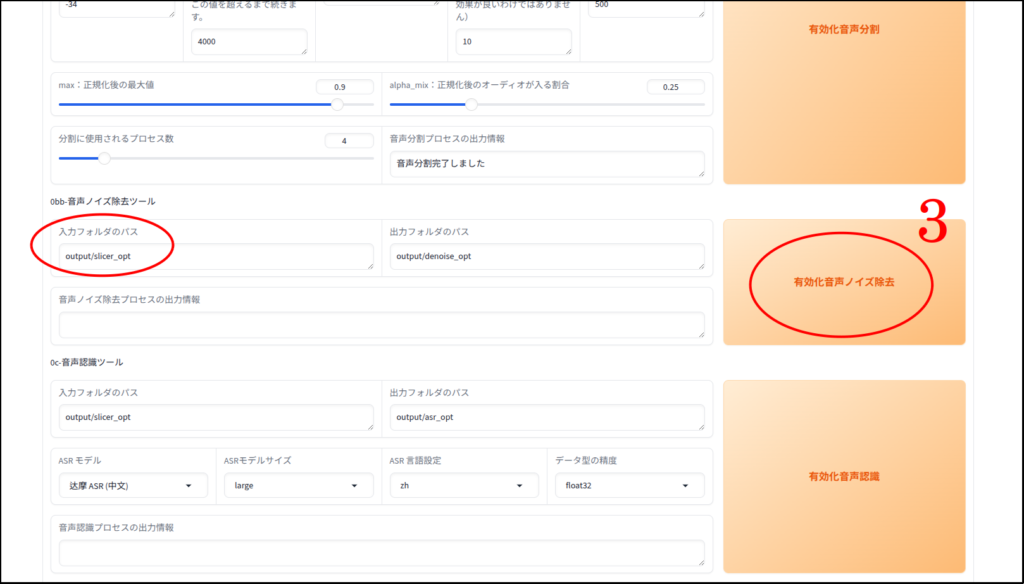
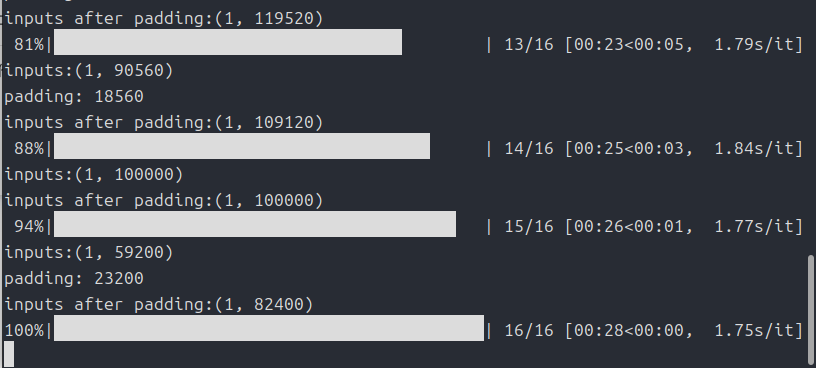
この「有効化音声ノイズ除去」処理はしなくてはならないということはありません。
実際自分はこの処理はいつもとばします。
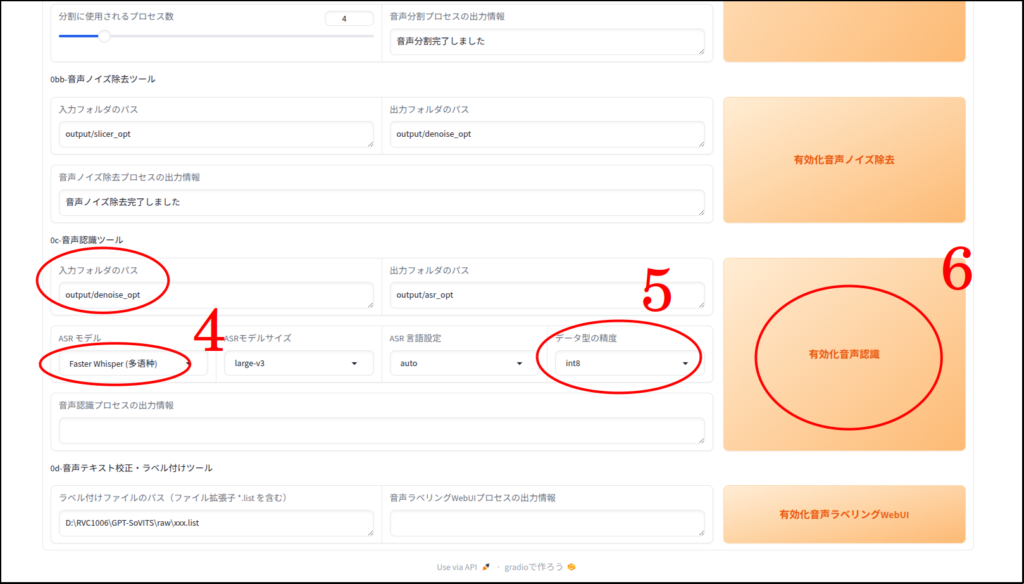
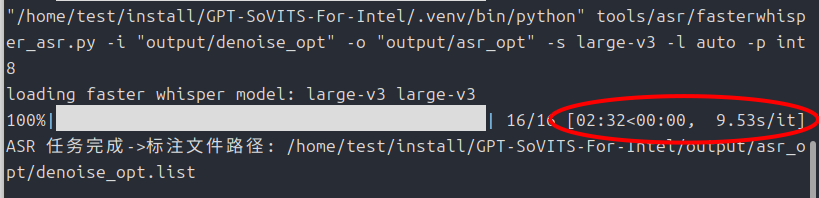
追記(2025/12/30)
「faster_whisper」ではなく「insanely-fast-whisper」を使うことでxpuに対応しました。速度も劇的に向上しています。
こちらの記事で紹介しています。

今回は利便性のため、あえて直さずにそのまま使います。
もし、生成結果が芳しくない場合は、全て「ひらがな」に直しても良いかもしれません。
メタデータの作成
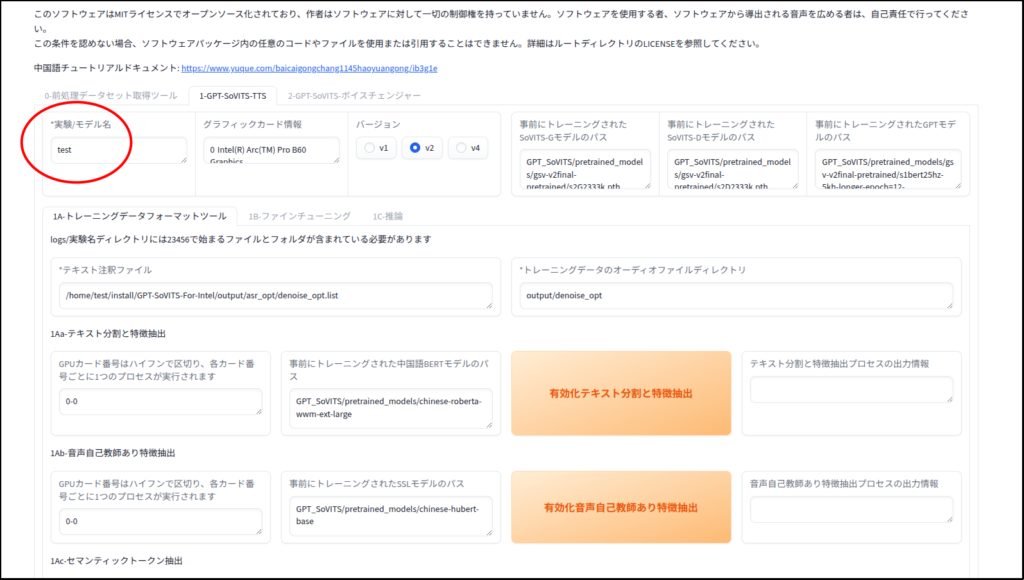
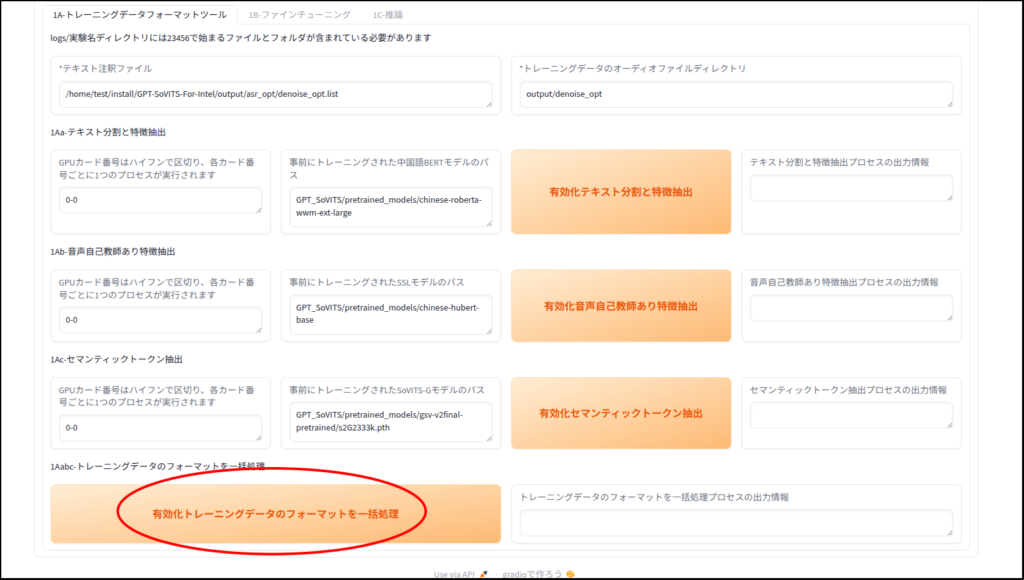
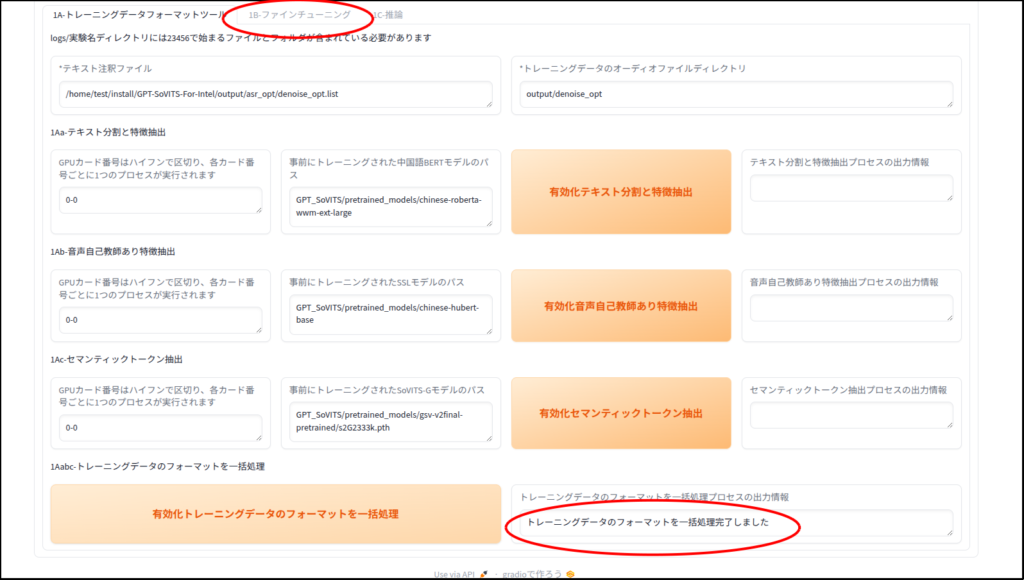
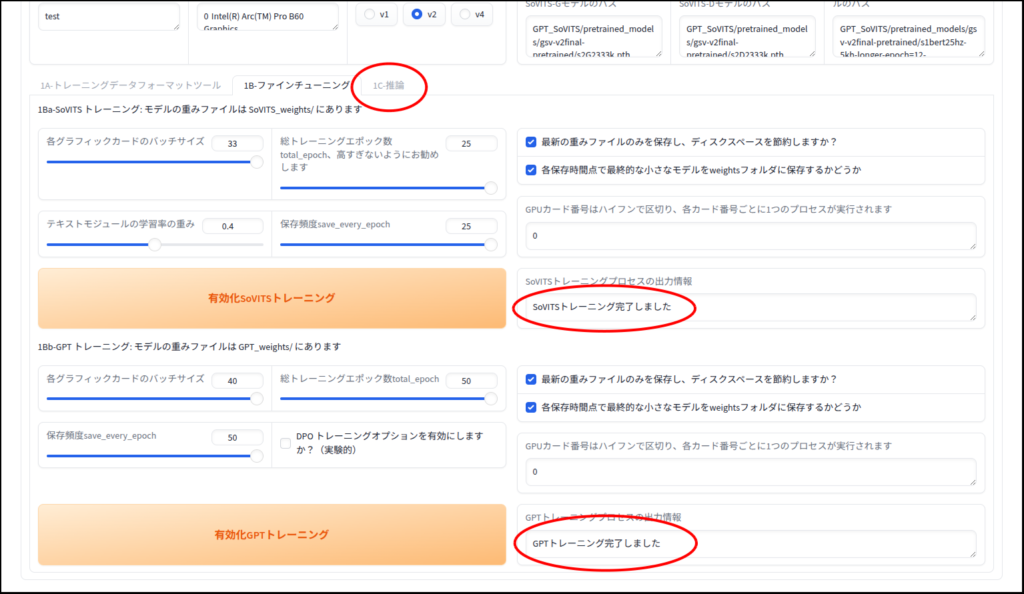
ファインチューニング
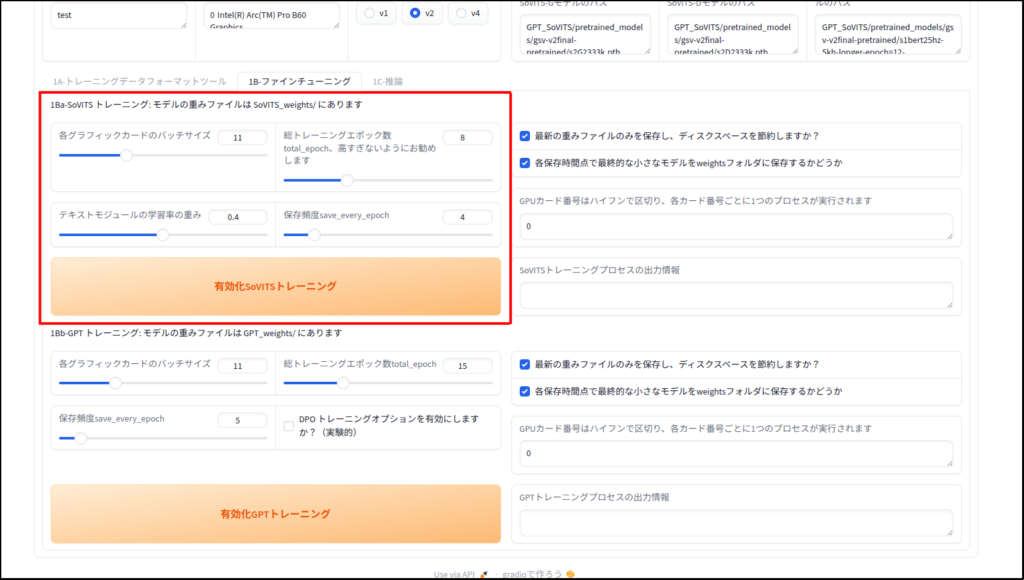
以下Geminiの解説です。
各グラフィックカードのバッチサイズ (Batch size):
- 一度の学習ステップでGPUに読み込ませるデータの量です。
- 数値を大きくすると学習速度が上がりますが、ビデオメモリ(VRAM)をより多く消費します。エラー(Out of Memory)が出る場合は、この数値を下げます。
- (補足)自分の環境では、下げすぎてもエラーが出ました。
総トレーニングエポック数 (Total epochs):
- 用意した学習データを合計で何回繰り返して学習させるかという回数です。
- 「高すぎないようにお勧めします」とある通り、多すぎると特定のデータに過剰に適応してしまい(過学習)、声が不自然になったり、汎用性が失われたりします。通常は10〜25程度が目安とされることが多いです。
テキストモジュールの学習率の重み:
- テキスト(文字)を解析する部分の学習の強さを調整します。
- 基本的にはデフォルト値で問題ありませんが、読み上げのアクセントなどを微調整したい場合に調整することがあります。
保存頻度 save_every_epoch:
- 何エポックごとにモデルの中間ファイルを保存するかを指定します。
- 例えば「4」に設定されている場合、4エポック目、8エポック目…というタイミングでモデルが保存されます。
- (補足)この数値は「総トレーニングエポック数 」と同数にしておいてください。
下の「GPTトレーニング」の部分も共通認識で良いと思います。
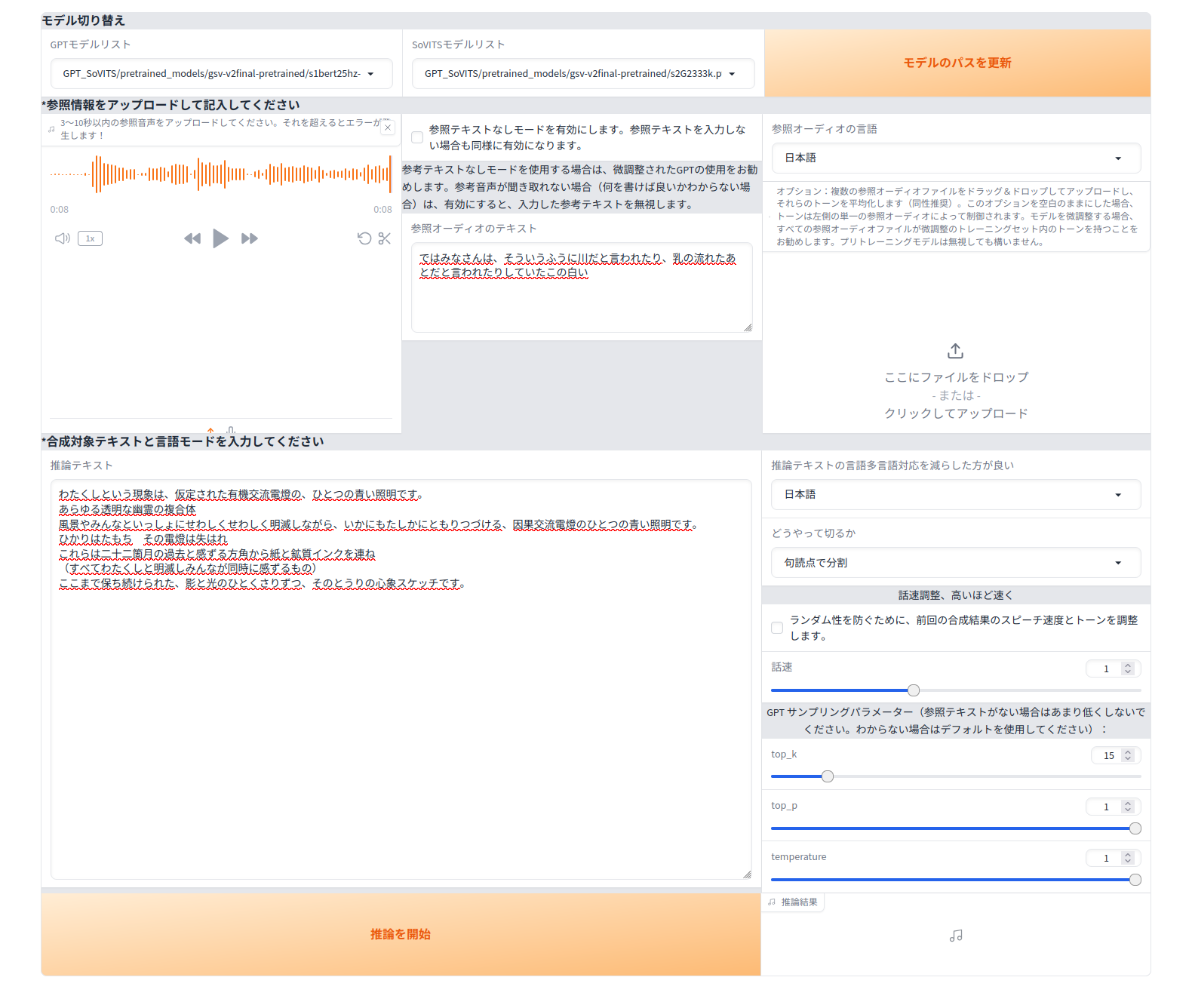
推論で音声を生成してみましょう
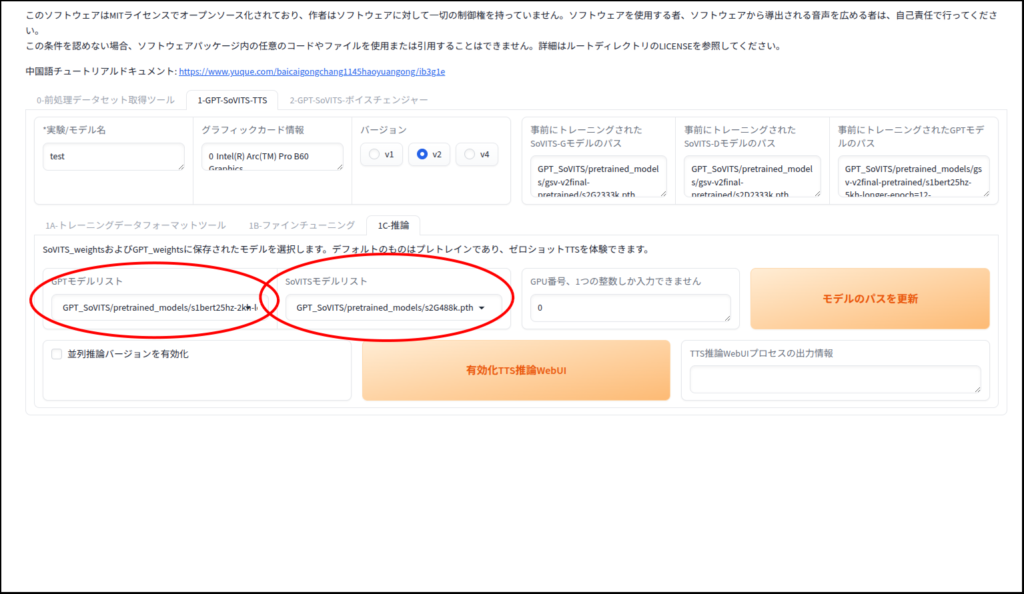
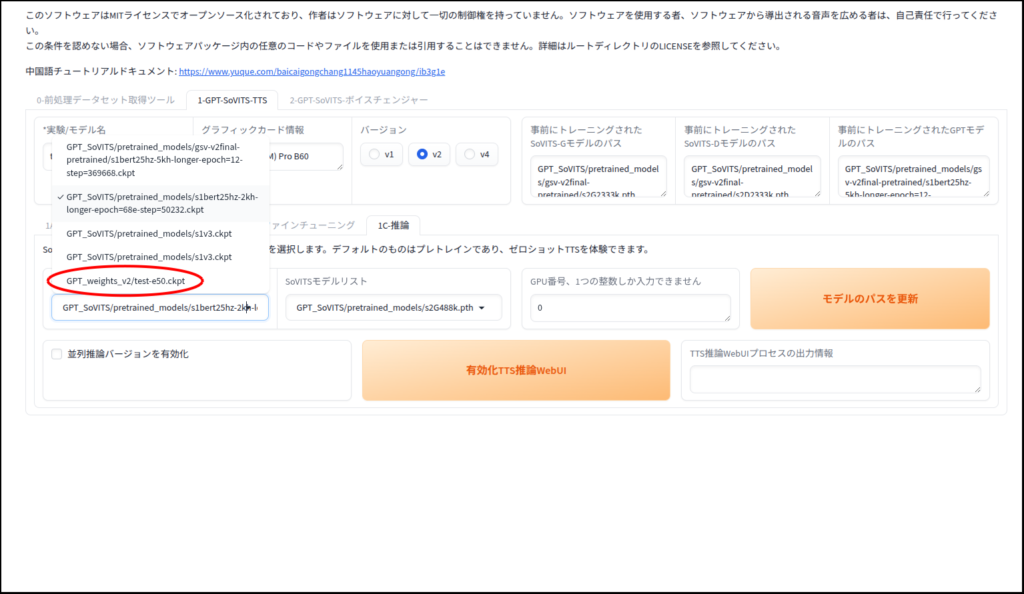
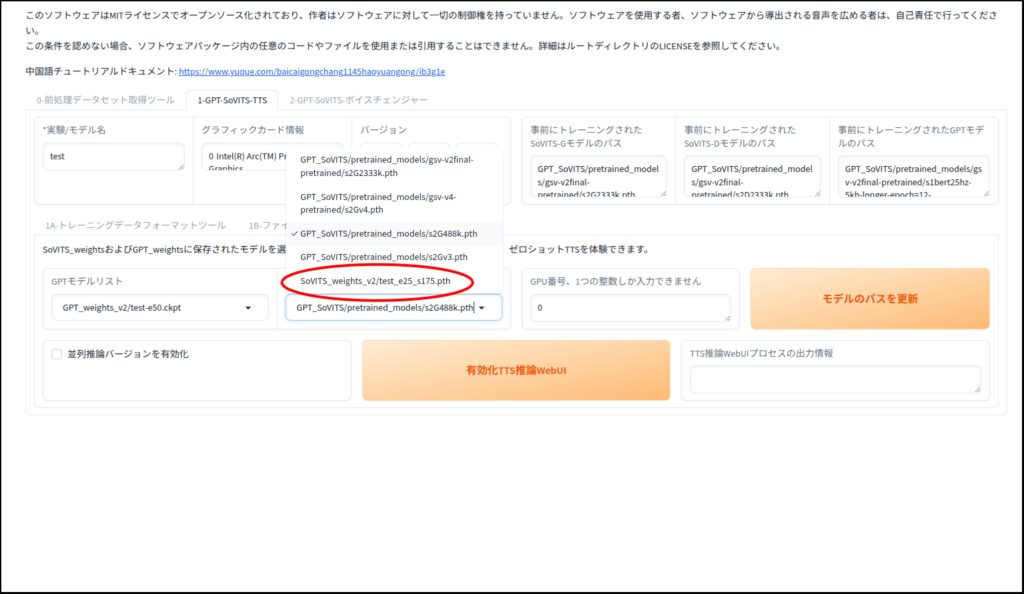
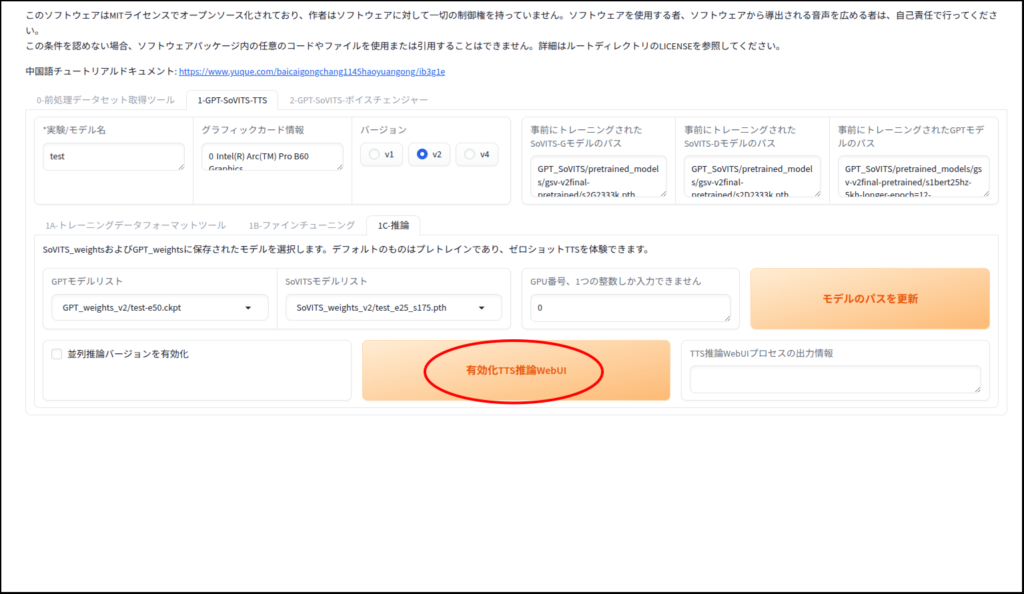
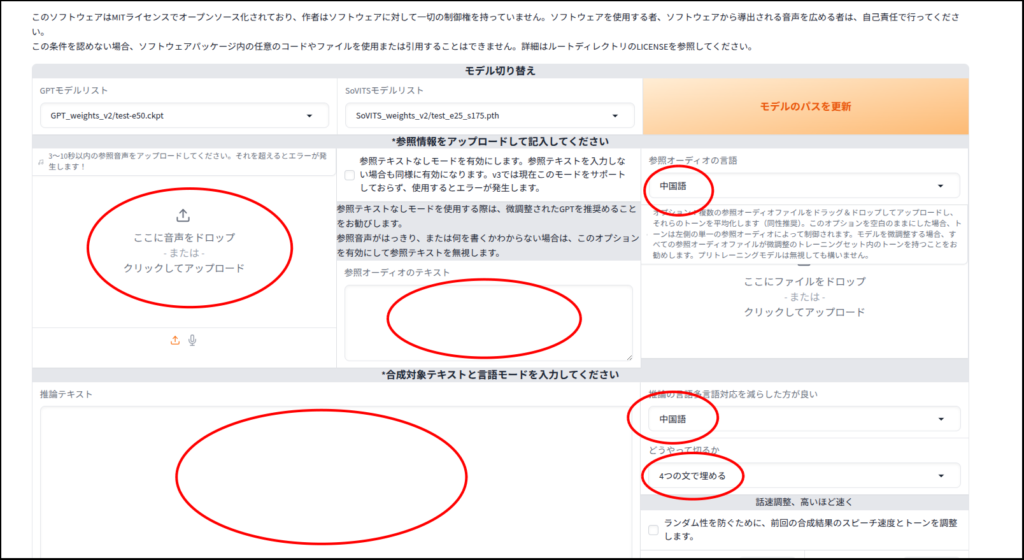
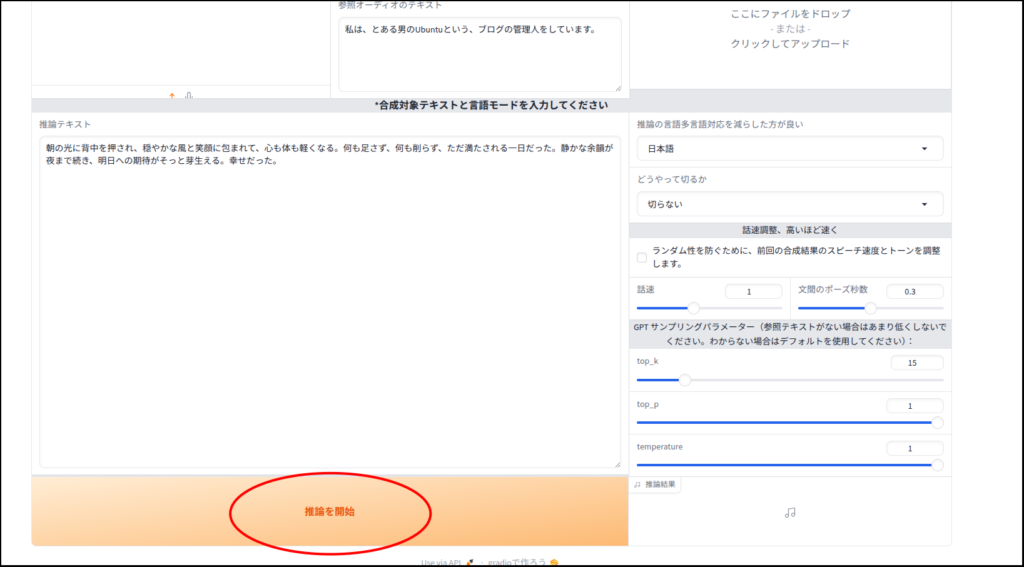
生成完了
今回生成した音声です。
ちなみに前回のゼロショットでの生成音声です。
ゼロショットのモデルが非常に優秀です(メチャかっこいい!)。
でもこれって自分の声では無いような・・・。
ひきかえ、自分の音声を学習した方は素人感丸出しといった感じですね・・・。
ただ、こちらはまさに自分の声といった感じです。
現実なんてこんなもんですよ・・・。
追記(2026/1/16)
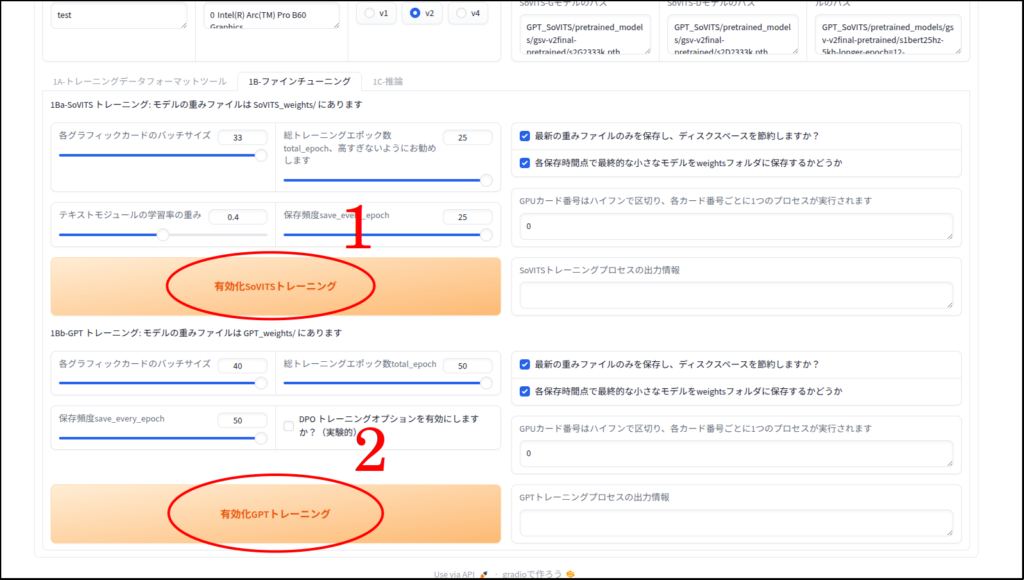
SoVITSとGPTの両方のトレーニングエポック数を最大にしていましたが、過学習の傾向がでていたかもしれません。
トレーニングエポック数を変更します。SoVITSを「8」に、GPTを「15」にして学習し直してから、音声を生成してみました。
素人くささは仕方ないですが、こちらの方がスムーズで音の途切れも無くなったと思います。
最後に
3日間まるまる使って記事作成に試行錯誤していました。
Geminiとケンカしながらソースコードをいじったり、ただそのせいで生成される音声のひどい出来に悩まされ、何度も何度もトライアンドエラーを繰り返す。
4つのpythonスクリプトをいじっていたのですが、実はいじるのはひとつだけで良かった、と気づいてからまたコードの書き直し(Geminiが)。
ようやく再現性が確認できて記事としてアップできるところまで来ました。
今回は以上です。
自分が使っている「Pro B60」ですが、記事を書いている現在は在庫が全滅しています。
価格.comでも全て空ですね。
こんな高価なのは、無理に買わなくても下のB580の方が個人的にオススメです。

B580は玄人志向のDFが安く、全長240mmと小さいので取り回しも良くオススメです。
負荷中はちょっとうるさいかもしれませんが、B60よりははるかにマシでしょう。


コメント