Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。
2025/5/3に記事を書き直しました。
FramePackのフォーク版のFramePack-eichiを本家FramePackで動かす方法を記事にしました。
GeForceではなくIntel ARCで動かします。
なぜ本家でないのかというと、本家の方はlatentの生成まではできるのですが、VAEエンコードでクラッシュする問題が解決できないからです。
こちらのeichiの方はなぜかクラッシュすることもなく動作します。
ちなみに今回もUbuntu編ですが、たぶんWindowsでも動くのではないかと思います。
インストール手順
- Intel ARC用のmemory.pyの作成
- FramePack-eichiをダウンロード
- 本家FramePackのダウンロード
- FramePack-eichiの「webui/diffusers_helper」を「FramePack/diffusers_helper」に配置
- 書き換えたmemory.pyを「diffusers_helper」に配置
- 「eichi」入りFramePackの起動
今回はインストールスクリプトで自動化できるところは自動化しようと思います。
インストールスクリプトの作成と実行
適当な場所でテキストファイルを作り、以下のスクリプトをコピペします。
#!/bin/bash
sudo apt update
sudo apt install -y git unzip python3 python3-pip python3-venv
sudo apt install -y libgoogle-perftools-dev
cd ~
mkdir -p install
cd install
touch memory.py
cat << 'EOF' > memory.py
#!/bin/bash
# By lllyasviel (XPU対応版)
import torch
cpu = torch.device('cpu')
gpu = torch.device(f"xpu:{torch.xpu.current_device()}")
gpu_complete_modules = []
class DynamicSwapInstaller:
@staticmethod
def _install_module(module: torch.nn.Module, **kwargs):
original_class = module.__class__
module.__dict__['forge_backup_original_class'] = original_class
def hacked_get_attr(self, name: str):
if '_parameters' in self.__dict__:
_parameters = self.__dict__['_parameters']
if name in _parameters:
p = _parameters[name]
if p is None:
return None
if isinstance(p, torch.nn.Parameter):
return torch.nn.Parameter(p.to(**kwargs), requires_grad=p.requires_grad)
else:
return p.to(**kwargs)
if '_buffers' in self.__dict__:
_buffers = self.__dict__['_buffers']
if name in _buffers:
return _buffers[name].to(**kwargs)
return super(original_class, self).__getattr__(name)
module.__class__ = type('DynamicSwap_' + original_class.__name__, (original_class,), {
'__getattr__': hacked_get_attr,
})
return
@staticmethod
def _uninstall_module(module: torch.nn.Module):
if 'forge_backup_original_class' in module.__dict__:
module.__class__ = module.__dict__.pop('forge_backup_original_class')
return
@staticmethod
def install_model(model: torch.nn.Module, **kwargs):
for m in model.modules():
DynamicSwapInstaller._install_module(m, **kwargs)
return
@staticmethod
def uninstall_model(model: torch.nn.Module):
for m in model.modules():
DynamicSwapInstaller._uninstall_module(m)
return
def fake_diffusers_current_device(model: torch.nn.Module, target_device: torch.device):
if hasattr(model, 'scale_shift_table'):
model.scale_shift_table.data = model.scale_shift_table.data.to(target_device)
return
for _, p in model.named_modules():
if hasattr(p, 'weight'):
p.to(target_device)
return
def get_cuda_free_memory_gb(device=None):
if device is None:
device = gpu
if device.type == "xpu":
try:
props = torch.xpu.get_device_properties(device)
total_memory = props.total_memory
allocated = torch.xpu.memory_allocated(device)
free = total_memory - allocated
return free / (1024 ** 3)
except Exception as e:
print("[Warning] Failed to get XPU memory info:", e)
return 0
# fallback for CUDA (if you run on CUDA system)
if device.type == "cuda":
try:
memory_stats = torch.cuda.memory_stats(device)
bytes_active = memory_stats.get('active_bytes.all.current', 0)
bytes_reserved = memory_stats.get('reserved_bytes.all.current', 0)
bytes_free_cuda, _ = torch.cuda.mem_get_info(device)
bytes_inactive_reserved = bytes_reserved - bytes_active
bytes_total_available = bytes_free_cuda + bytes_inactive_reserved
return bytes_total_available / (1024 ** 3)
except Exception as e:
print("[Warning] Failed to get CUDA memory info:", e)
return 0
return 0
def move_model_to_device_with_memory_preservation(model, target_device, preserved_memory_gb=0):
print(f'Moving {model.__class__.__name__} to {target_device} with preserved memory: {preserved_memory_gb} GB')
for m in model.modules():
if get_cuda_free_memory_gb(target_device) <= preserved_memory_gb:
return
if hasattr(m, 'weight'):
m.to(device=target_device)
model.to(device=target_device)
return
def offload_model_from_device_for_memory_preservation(model, target_device, preserved_memory_gb=0):
print(f'Offloading {model.__class__.__name__} from {target_device} to preserve memory: {preserved_memory_gb} GB')
for m in model.modules():
if get_cuda_free_memory_gb(target_device) >= preserved_memory_gb:
return
if hasattr(m, 'weight'):
m.to(device=cpu)
model.to(device=cpu)
return
def unload_complete_models(*args):
for m in gpu_complete_modules + list(args):
m.to(device=cpu)
print(f'Unloaded {m.__class__.__name__} as complete.')
gpu_complete_modules.clear()
return
def load_model_as_complete(model, target_device, unload=True):
if unload:
unload_complete_models()
model.to(device=target_device)
print(f'Loaded {model.__class__.__name__} to {target_device} as complete.')
gpu_complete_modules.append(model)
return
EOF
git clone https://github.com/git-ai-code/FramePack-eichi.git
git clone https://github.com/lllyasviel/FramePack.git
cp -rf ./FramePack-eichi/webui/* ./FramePack
mv ./memory.py ./FramePack/diffusers_helper
cd ./FramePack
python3 -m venv venv
source ./venv/bin/activate
python -m pip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/xpu
python -m pip install intel-extension-for-pytorch==2.7.10+xpu oneccl_bind_pt==2.7.0+xpu --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
pip install -r ./requirements.txt
python ./endframe_ichi.py --inbrowserコピペしたファイルに「install.sh」と名前をつけて保存し、
bash ./install.shで実行します。
モデルファイルのダウンロードが40GBほどあるので時間がかかりますが、我慢して待ちましょう。
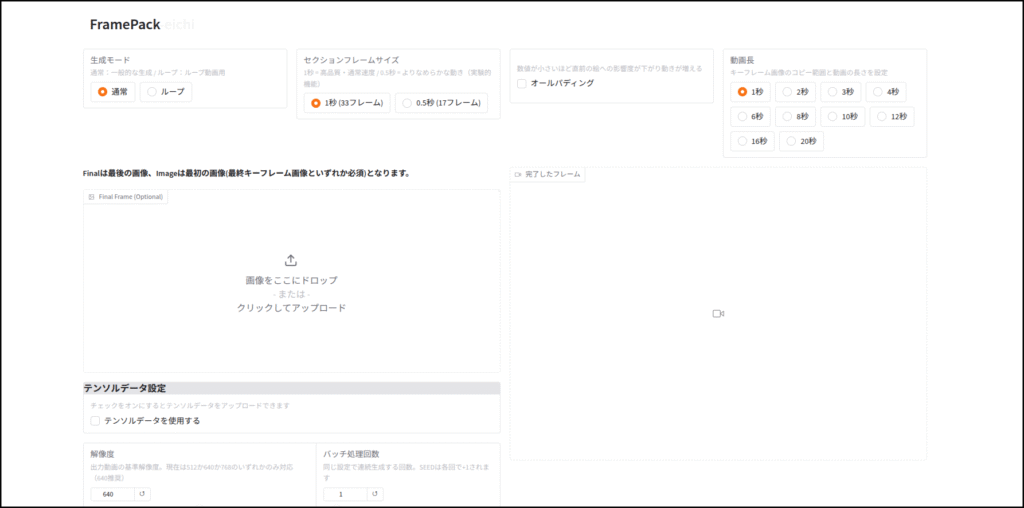
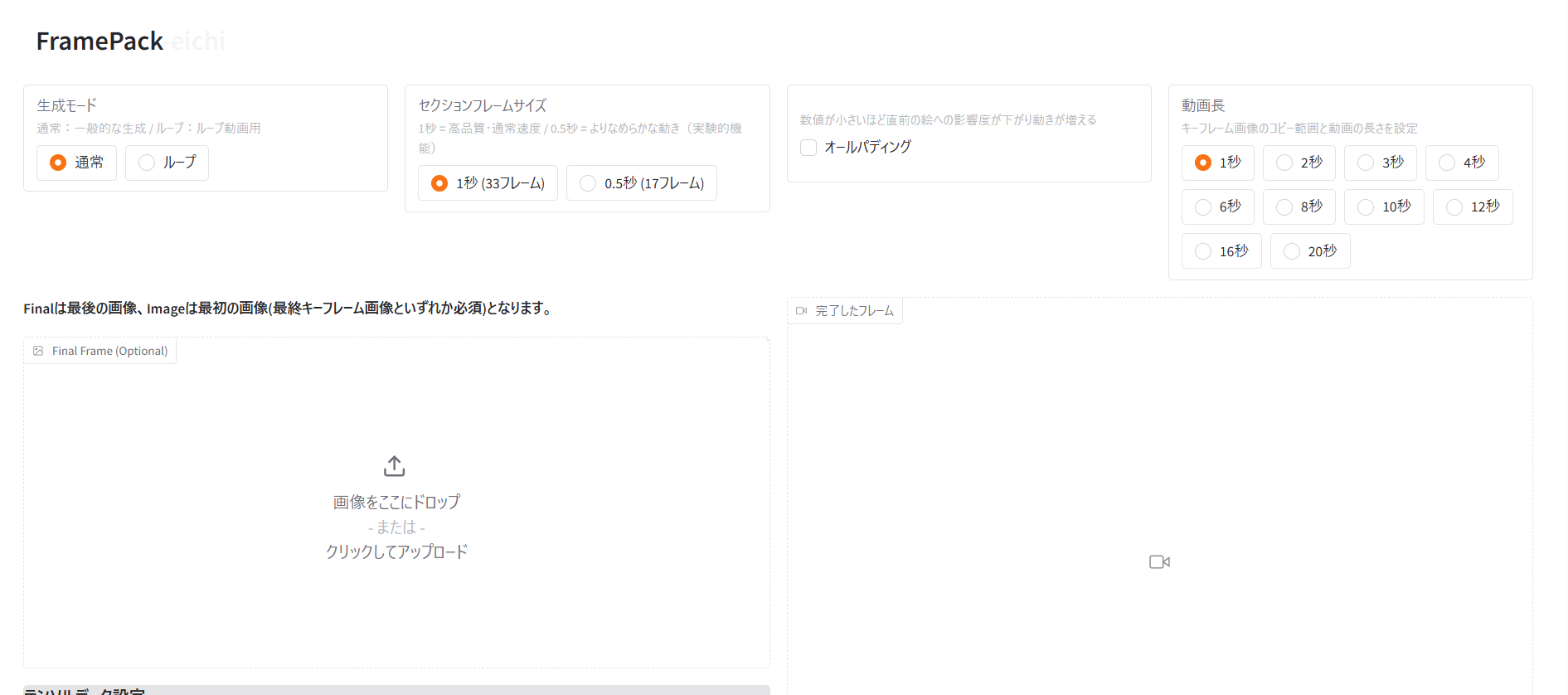
使い方はyoutubeとかみれば情報はたくさんあると思います。
ちなみに今回から、Intel Extension for PyTorch「v2.7.10 + xpu」を使用しています。
これはIntel ARC AシリーズとBシリーズの両方に対応していますので、インストール方法は同じはずです(Aシリーズ持ってないから試せない・・・)。
2025/11/8追記
最近この記事のアクセス数が増えているようです。
理由はわかりませんが、FramePack-eichiは後のバージョンでエラーが出ることをこの記事で書いています。
もし、エラーで困っている場合は参考にしてください。
2025/11/8追記2
この記事ではIPEX(v2.7.10 + xpu)の導入について書いていますが、最近ではtorch.xpuがありますのでこちらの記事を参考にしてください。メインメモリの使用量に変化があるようです。
ただ、最近自分はIntel ARCを手放してしまっているので、導入のテストができません。
もし、torch.xpuで実行できない場合はIPEXを代用してください。
2025/11/8追記3
どうやら「https://github.com/git-ai-code/FramePack-eichi.git」は現在リポジトリが消滅してしまっているようです。
フォーク版などが存在するようですが、そちらを使用する場合は
git clone https://github.com/git-ai-code/FramePack-eichi.git
git clone https://github.com/lllyasviel/FramePack.git
cp -rf ./FramePack-eichi/webui/* ./FramePackこのあたりのコードを書き換える必要がありそうです。
更にその時は、こちらの記事内容は通用しなくなるかもしれません。
今回使ったB580です。

Challenger安くなってますね。

今回は以上です。
コメント