Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。
前回の記事で、英語の動画を日本語に訳して字幕をつけるという自作ソフトを紹介しました。
ですが、この時は音声を抜き出した後、「息継ぎ」や「間」といった音声の切れ目を閾値によって判別するという手法をとっていたため、字幕の切れ目が不自然になったりしていました。
そのためか、日本語に意訳した時も意味の通じにくい字幕になっていたりと問題があったので、今回はここに手を入れてみました。
具体的には、音声から文字を起こす時、「本家whisper」を使うことで文字起こしが「より自然な形になるように」変更しました。
もうひとつ。
グラフィックスカードのVRAMが足りない場合、メインメモリに退避しながら処理するという方法をとっていましたが、「OpenVINO」を使うことでモデル自体のデータ型を「int4」や「int8」に変換してVRAM消費量を抑えるという改良もしてみました。
但し、OpenVINOのところはIntel GPUのみ対応です。
それ以外のGPUの場合はhaggingfaceのモデルのみ対応となります。
今回はgradio版のみ公開です。
それでは、いってみましょう。
環境構築
例によってuv環境を使っていきます(別にpython venvでもcondaでもいいと思いますが試してません)。
#!/bin/bash
mkdir -p ~/install/auto-langtrans
cd ~/install/auto-langtrans
uv venv --python 3.12 --seed
source .venv/bin/activate
#Intel Arcなのでtorch.xpuをインストール
#stable
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/xpu
#本スクリプトに使用
uv pip install tqdm transformers accelerate openai-whisper gradio
#OpenVINOを使う場合
uv pip install "optimum-intel[openvino]" openvino-tokenizers openvino-genaipythonは「3.12」でなければならないということはないと思いますが、「3.10」以上が良いんじゃないでしょうか。
「OpenVINOを使う場合」のところはIntel GPU以外の場合は入れなくていいです。
pytorchのところはそれぞれのGPUに対応したものを入れてください。

こちらのページを参考に。
メインスクリプト
といってもメインしかありません。
import torch
import whisper
import openvino_genai as ov_genai
from transformers import pipeline
import gc
import time
import subprocess
import gradio as gr
import os
from pathlib import Path
# --- デバイス検知 ---
if hasattr(torch, "xpu") and torch.xpu.is_available():
WHISPER_DEVICE = "xpu"
elif torch.cuda.is_available():
WHISPER_DEVICE = "cuda"
else:
WHISPER_DEVICE = "cpu"
OV_DEVICE = "GPU"
# --- 言語・モデル定義 ---
LANG_MAP = {
"English (英語)": ["en", "eng"],
"Japanese (日本語)": ["ja", "jpn"],
"French (フランス語)": ["fr", "fre"],
"Spanish (スペイン語)": ["es", "spa"],
"German (ドイツ語)": ["de", "ger"],
"Chinese (中国語)": ["zh", "chi"],
"Auto (自動判定)": [None, "jpn"]
}
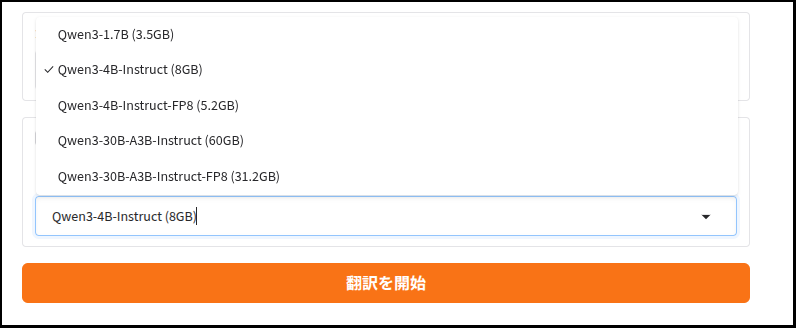
HF_MODEL_OPTIONS = {
"Qwen3-1.7B": "Qwen/Qwen3-1.7B",
"Qwen3-4B-Instruct": "Qwen/Qwen3-4B-Instruct-2507",
"Qwen3-4B-Instruct-FP8": "Qwen/Qwen3-4B-Instruct-2507-FP8",
"Qwen3-30B-A3B-Instruct": "Qwen/Qwen3-30B-A3B-Instruct-2507",
"Qwen3-30B-A3B-Instruct-FP8": "Qwen/Qwen3-30B-A3B-Instruct-2507-FP8"
}
# --- ヘルパー関数 ---
def get_local_ov_folders():
"""現在のディレクトリからOpenVINOモデル候補(フォルダ)を検索"""
return [f.name for f in Path(".").iterdir() if f.is_dir() and not f.name.startswith(".")]
def format_timestamp(seconds):
td = torch.tensor(seconds)
milliseconds = int((td - int(td)) * 1000)
seconds = int(td)
minutes, seconds = divmod(seconds, 60)
hours, minutes = divmod(minutes, 60)
return f"{hours:02d}:{minutes:02d}:{seconds:02d},{milliseconds:03d}"
def write_srt(segments, srt_path):
with open(srt_path, "w", encoding="utf-8") as f:
for i, seg in enumerate(segments):
start_str = format_timestamp(seg["start"])
end_str = format_timestamp(seg["end"])
text = seg["text"].strip()
if not text: continue
f.write(f"{i + 1}\n{start_str} --> {end_str}\n{text}\n\n")
# --- UI連動ロジック ---
def toggle_model_list(use_ov):
if use_ov:
folders = get_local_ov_folders()
return gr.update(choices=folders, value=folders[0] if folders else None, label="OpenVINOフォルダを選択")
else:
choices = list(HF_MODEL_OPTIONS.keys())
return gr.update(choices=choices, value="Qwen3-4B-Instruct", label="Hugging Faceモデルを選択")
# --- メイン処理 ---
def run_pipeline(video_in, src_lang_key, target_lang_key, model_choice, use_ov, progress=gr.Progress()):
if not video_in: return None
src_code = LANG_MAP[src_lang_key][0]
target_name = target_lang_key.split(" ")[0]
iso_code = LANG_MAP[target_lang_key][1]
v_path = Path(video_in)
# --- 【修正】現在のディレクトリに temp_dir を作成し、その中に動画別フォルダを作る ---
base_output_dir = Path("temp_dir")
base_output_dir.mkdir(exist_ok=True)
# 動画ファイル名に基づいた専用フォルダ (例: temp_dir/my_video/)
work_dir = base_output_dir / v_path.stem
work_dir.mkdir(exist_ok=True)
audio_path = work_dir / "audio.wav"
source_srt = work_dir / "source.srt"
output_srt = work_dir / "output.srt"
output_video = work_dir / f"{v_path.stem}_subtitled.mp4"
# -----------------------------------------------------------------------
# 1. 音声抽出
progress(0.1, desc="音声抽出中...")
subprocess.run(["ffmpeg", "-y", "-i", str(v_path), "-vn", "-ac", "1", "-ar", "16000", str(audio_path), "-loglevel", "error"], check=True)
# 2. Whisper文字起こし (XPU対応)
progress(0.2, desc="Whisperで文字起こし中...")
model = whisper.load_model("medium", device=WHISPER_DEVICE)
result = model.transcribe(str(audio_path), language=src_code, verbose=True)
segments = [{"start": s["start"], "end": s["end"], "text": s["text"]} for s in result["segments"]]
write_srt(segments, source_srt) # source.srtの保存
del model
gc.collect()
if WHISPER_DEVICE == "xpu": torch.xpu.empty_cache()
# 3. 翻訳 (LLM)
sys_prompt = f"あなたは自作PC動画の翻訳者です。自然な{target_name}に翻訳してください。専門用語は日本の界隈の慣習(Driver→ドライバ等)に従うこと。"
if use_ov:
pipe = ov_genai.LLMPipeline(model_choice, OV_DEVICE)
def gen(t):
p = f"<|im_start|>system\n{sys_prompt}<|im_end|>\n<|im_start|>user\n{t}<|im_end|>\n<|im_start|>assistant\n"
return pipe.generate(p, max_new_tokens=256, temperature=0.3).strip()
else:
model_id = HF_MODEL_OPTIONS[model_choice]
pipe = pipeline("text-generation", model=model_id, device_map="auto", torch_dtype="auto", trust_remote_code=True)
def gen(t):
m = [{"role": "system", "content": sys_prompt}, {"role": "user", "content": t}]
res = pipe(m, max_new_tokens=256, temperature=0.3)
return res[0]['generated_text'][-1]['content'].strip()
translated = []
for seg in progress.tqdm(segments, desc="翻訳中..."):
try: seg["text"] = gen(seg["text"])
except: pass
translated.append(seg)
write_srt(translated, output_srt)
del pipe
gc.collect()
# 4. 結合
progress(0.9, desc="字幕結合中...")
subprocess.run(["ffmpeg", "-y", "-i", str(v_path), "-i", str(output_srt), "-c", "copy", "-c:s", "mov_text",
"-metadata:s:s:0", f"language={iso_code}", str(output_video), "-loglevel", "error"], check=True)
# Gradioに返すパスは作成した output_video (Pathオブジェクト) の文字列
return str(output_video)
# --- GUI 構築 ---
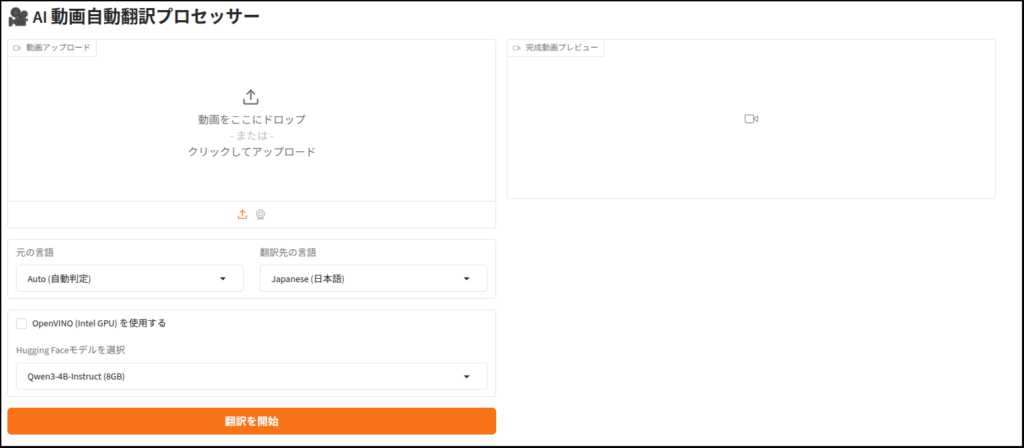
with gr.Blocks(title="Video Translator Pro") as demo:
gr.Markdown("# 🎥 AI 動画自動翻訳プロセッサー")
with gr.Row():
with gr.Column():
video_input = gr.Video(label="動画アップロード")
with gr.Row():
src_lang = gr.Dropdown(choices=list(LANG_MAP.keys()), value="English (英語)", label="元の言語")
target_lang = gr.Dropdown(choices=list(LANG_MAP.keys()), value="Japanese (日本語)", label="翻訳先の言語")
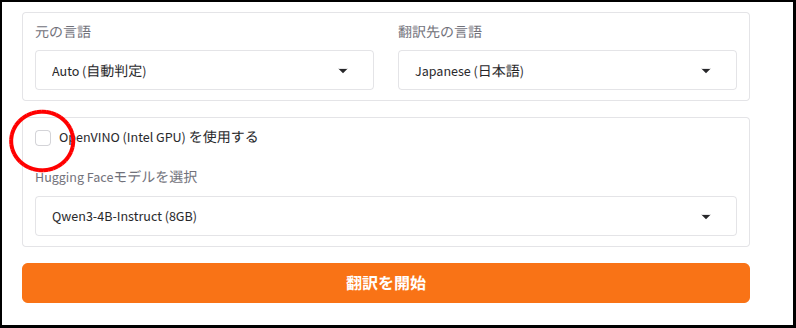
use_ov = gr.Checkbox(label="OpenVINO (Intel GPU) を使用する", value=True)
model_drop = gr.Dropdown(choices=get_local_ov_folders(), label="翻訳モデルを選択")
btn = gr.Button("翻訳を開始", variant="primary")
with gr.Column():
video_output = gr.Video(label="完成動画プレビュー")
gr.Info(f"システム情報: Whisper={WHISPER_DEVICE}, OV={OV_DEVICE}")
use_ov.change(fn=toggle_model_list, inputs=use_ov, outputs=model_drop)
btn.click(fn=run_pipeline, inputs=[video_input, src_lang, target_lang, model_drop, use_ov], outputs=[video_output])
if __name__ == "__main__":
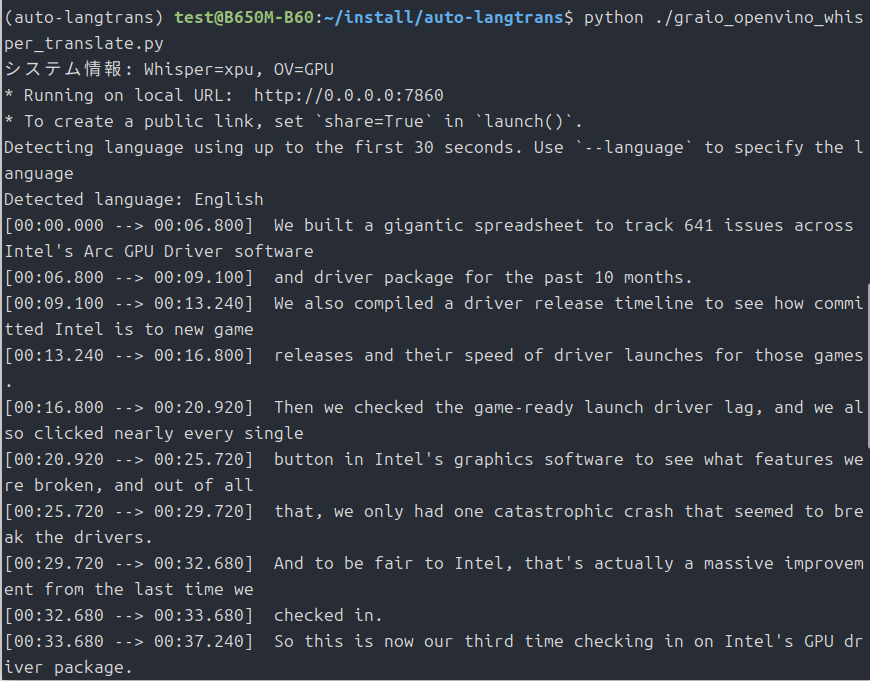
demo.launch(server_name="0.0.0.0", share=False, inbrowser=True)自分は「graio_openvino_whisper_translate.py」という名前で保存していますが、好きに変えてください。
起動
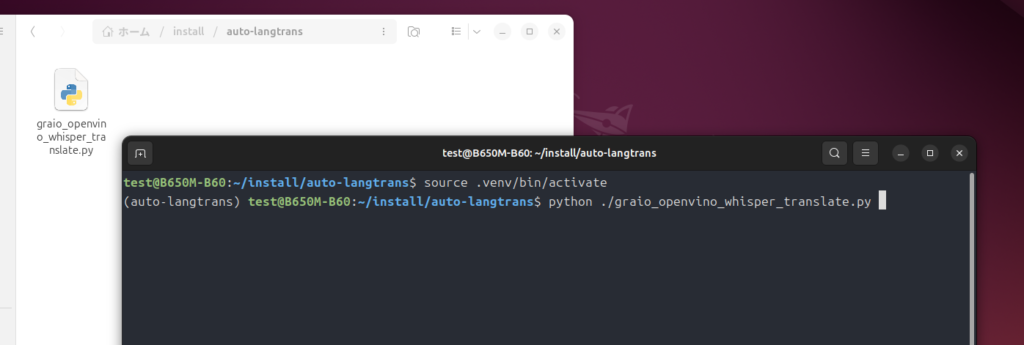
source .venv/bin/activate
python ./graio_openvino_whisper_translate.pyで起動。
モデルをOpenVINOで軽量化
ひととおりの使い方は上のチャプターで説明しましたので、今度はVRAMの削減方法を。
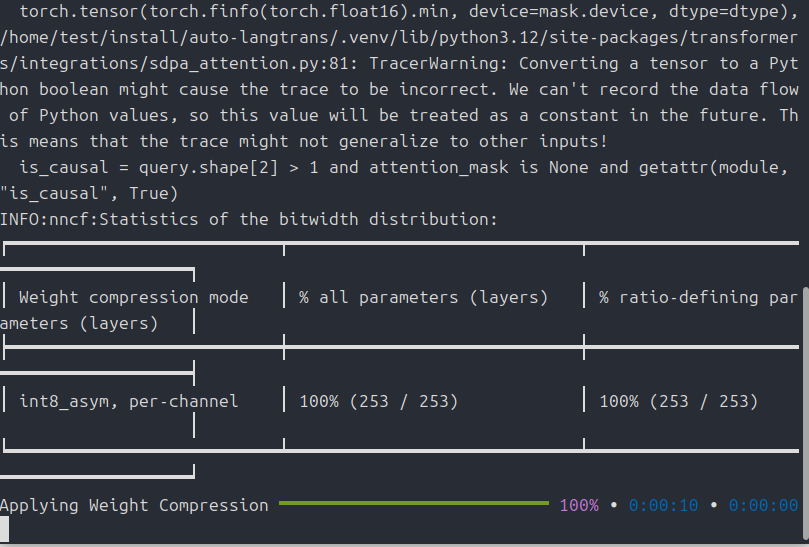
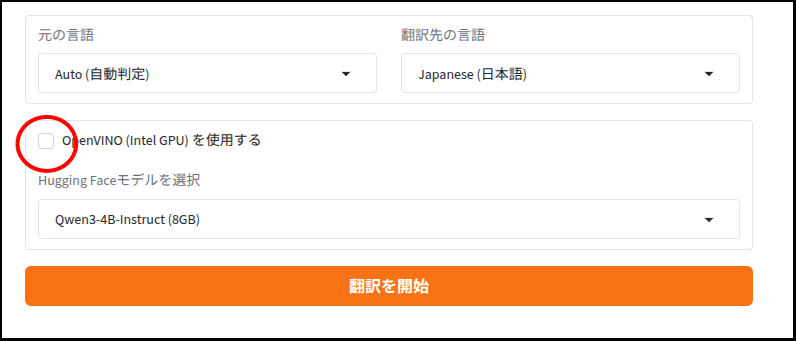
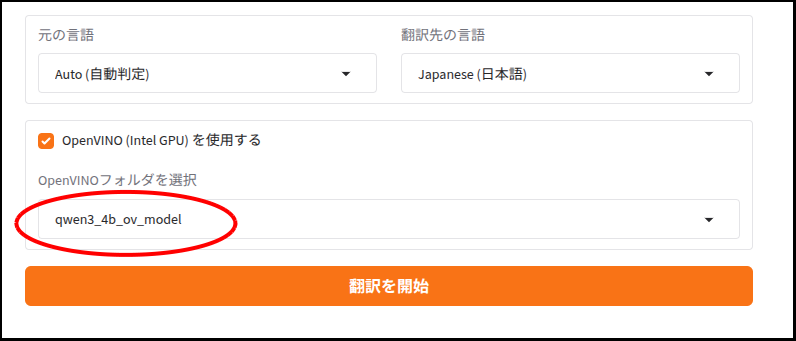
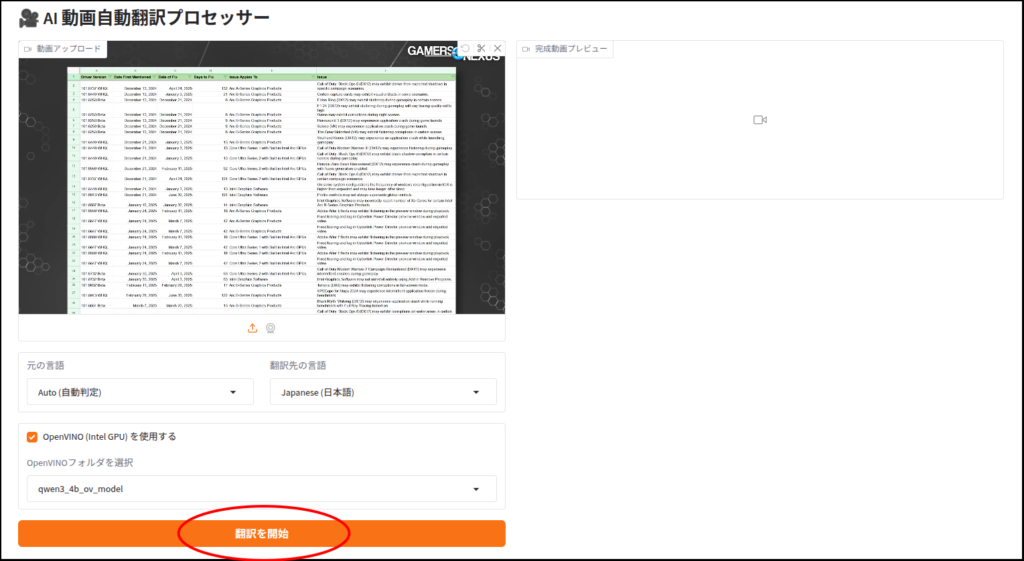
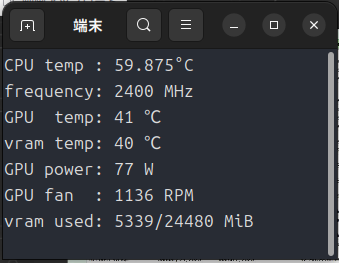
ただし出来栄えの方は・・・
int8に変換した場合のサンプルの動画が以下です。
今度は、文字起こしは当ソフトを使い、翻訳をGeminiにやってもらって、元の動画に結合してみました。
最後に
質を求めるなら、この記事で紹介したwhisperを使って文字起こしをして、GeminiやChatGPTを使って翻訳するのが最上かと思います。
めんどいですが。
このソフトのいいところは全自動で最後まで処理してくれるところにあると思います。
今回は以上です。
追記
今回の処理自動翻訳ソフトですが、まだその出来に納得していないのでもうちょっと改善してみるつもりです。アイデアはいくらかあるので。
今回のCES2026には間に合いませんが・・・。
追記(2026/1/8)
こちらで改善したスクリプトの記事を書きました。
複雑な処理になっていますが、自動化はできています。
自分が使っている「Pro B60」ですが、記事を書いている現在は在庫が全滅しています。
価格.comでも全て空ですね。
こんな高価なのは、無理に買わなくても下のB580の方が個人的にオススメです。

B580は玄人志向のDFが安く、全長240mmと小さいので取り回しも良くオススメです。
負荷中はちょっとうるさいかもしれませんが、B60よりははるかにマシでしょう。
が、ジワジワ価格が上昇しているようです・・・。

RX9060XTの16GB版ですが、やはり値段がかなり上がってきてますね。


コメント