
Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。
Linuxの記事です。
新年の挨拶で、CES2026についてちょっと触れましたが、この時流れる動画はおそらく未翻訳となります。
今回の記事はそういった動画を自分で(というか自動で)翻訳するスクリプトの話です。
実はスクリプトをちょっと変更すれば英語に限らず翻訳することができます。
あ、自動といってもストリーミングで流れている動画を自動翻訳するわけではありません。
動画自体をなんらかの方法でPCに入れてからの操作になります。
試しに海外のテック系動画チャンネルの「Gamers Nexus」のIntel Arcについてとりあげた動画を3分ほどにカットして試してみました。
掲載するために解像度を落としていますが実際はこんな感じで滲んだりしないです。
Youtubeの動画は大体自動翻訳機能が使えるので、今回のようなスクリプトは使うことはありませんが、CES2026のような最新のストリーミング動画となると、日本のメディアを通じて翻訳記事が出るまで動画の内容がよくわからないといったことがおきます。
今回は自力でこれらをどうにかしようという記事です。
(もっといい方法があったら教えてください)
それでは、やっていきましょう。
個人的に最終形態版ができたので掲載します(翻訳の精度もこちらが上だと思います)。
英語の動画を自動翻訳する(個人的最終形態)
英語の動画を自動翻訳する(Radeon版)
以下の記事は、ソフトを作りたてで翻訳の精度がイマイチなので上のふたつのリンクをオススメします。
環境のインストール
ffmpegが必要になります。
こちらの記事を参考にインストールするか、面倒な人は
sudo apt install ffmpegでインストールしてください。
自分のPCがIntel Arcなので「torch.xpu」をインストールしていますが、Radeonなら「ROCm」に必要なものを、GeForceなら「cuda」に必要なものをインストールしましょう。
スクリプト自体はたいていのGPUで動作するはずです。
Windowsでも動くらしいです(試してません)。
#!/bin/bash
cd ~
mkdir -p install/insanely-fast-whisper
cd install/insanely-fast-whisper
uv venv --python 3.12 --seed
source .venv/bin/activate
#Intel Arcなのでtorch.xpuをインストール
#stable
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/xpu
#Radeonなら以下のコマンドのコメントアウトを消してください。
#pip install --pre torch torchvision --index-url https://download.pytorch.org/whl/nightly/rocm7.1
#「insanely-fast-whisper」を使うために必要なもの
uv pip install pydub tqdm sentencepiece sacremoses accelerate transformers例によってインストールフォルダを作ってからの環境構築です。
環境はuvを使っています。
Windowsならpowershellから以下で動く「らしい」です。
#以下のコマンドでuvのインストール
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"続いて、
# 1. デスクトップに移動 ($HOME はユーザーフォルダを指す変数です)
cd $HOME\Desktop
# 2. フォルダ作成 & 移動
# すでにフォルダがある場合のエラーを防ぐため、存在確認などの複雑なことはせず、
# シンプルに mkdir (作成) して cd (移動) します
mkdir insanely-fast-whisper
cd insanely-fast-whisper
# 3. 仮想環境作成 (Python 3.12指定)
uv venv --python 3.12 --seed
# 4. 【重要】仮想環境の有効化
.venv\Scripts\activate
# 5. PyTorch (Intel Arc/XPU版) のインストール
uv pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/xpu
# 6. その他ライブラリのインストール
uv pip install pydub tqdm sentencepiece sacremoses accelerate transformersで環境構築できるみたいです・・・。
Radeonのpytorchのインストールのところだけ、以下の動画が参考になるでしょう。
Windowsでもffmpegが必要になりますが・・・。
Windowsは個人的に嫌いなんで「Windows ffmpeg インストール」で検索してください。
パスをとおすのがめんどいです。
メインスクリプト
以下のスクリプトを「translate.py」という名前で作ってください。
import torch
import sys
import os
import subprocess
import gc
from pathlib import Path
from transformers import pipeline, AutoModelForCausalLM, AutoTokenizer
from pydub import AudioSegment
from pydub.silence import detect_nonsilent
from tqdm import tqdm
# --- 設定エリア ---
SOURCE_LANGUAGE = "english"
# 翻訳モデル設定
TRANSLATE_MODEL_ID = "Qwen/Qwen3-4B-Instruct-2507"
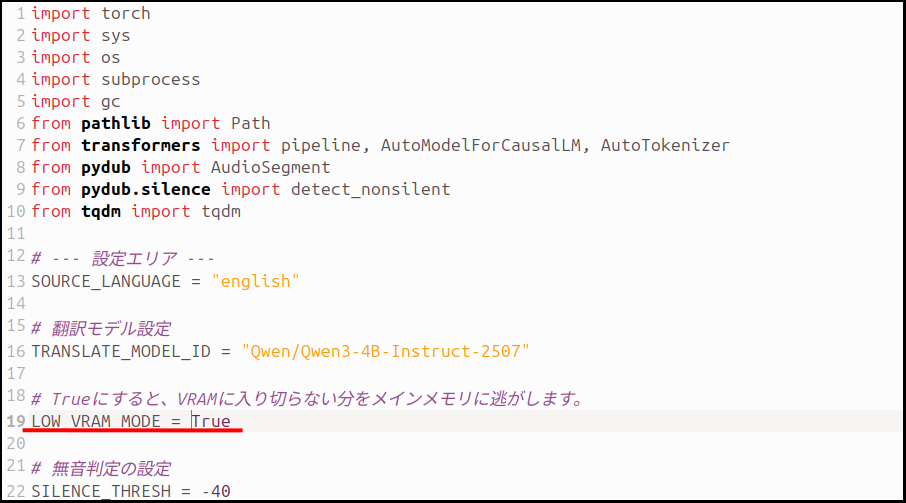
# Trueにすると、VRAMに入り切らない分をメインメモリに逃がします。
LOW_VRAM_MODE = True
# 無音判定の設定
SILENCE_THRESH = -40
MIN_SILENCE_LEN = 700
KEEP_SILENCE = 200
# -----------------
# ---------------------------------------------------------
# 1. GPU判定
# ---------------------------------------------------------
def get_device():
if torch.cuda.is_available():
return "cuda"
elif hasattr(torch, "xpu") and torch.xpu.is_available():
return "xpu"
else:
return "cpu"
# ---------------------------------------------------------
# 2. ファイル収集
# ---------------------------------------------------------
def get_target_files(base_dir="."):
current_dir = Path(base_dir)
target_extensions = ["*.mp4", "*.mkv"]
files = []
for ext in target_extensions:
files.extend(current_dir.glob(ext))
files.sort()
return files
# ---------------------------------------------------------
# 3. 翻訳機能 (LLM版: Qwen)
# ---------------------------------------------------------
def translate_text_segments_llm(segments, device_str):
"""
LLMを使って文脈を考慮した翻訳を行う
"""
print(f"\n -> Loading LLM for Translation ({TRANSLATE_MODEL_ID})...")
# 低VRAMモードなら device_map="auto" を使う
# これによりaccelerateライブラリが空きVRAMを計算して自動配置してくれる
if LOW_VRAM_MODE:
device_map_config = "auto"
print(" [INFO] LOW_VRAM_MODE is ON. Model will be offloaded to RAM if needed.")
else:
device_map_config = device_str
# モデルとトークナイザーをロード
# device_map="auto"を使う場合、明示的な .to(device) は不要になるケースが多いが
# dtypeの設定などはそのまま行う
dtype = torch.bfloat16 if device_str != "cpu" else torch.float32
try:
tokenizer = AutoTokenizer.from_pretrained(TRANSLATE_MODEL_ID)
model = AutoModelForCausalLM.from_pretrained(
TRANSLATE_MODEL_ID,
dtype=dtype,
device_map=device_map_config, # ここで分散配置を指定
trust_remote_code=True,
low_cpu_mem_usage=True # ロード時のメモリ消費も抑える
)
except Exception as e:
print(f"\n[Error] Failed to load model. If using LOW_VRAM_MODE on XPU, ensure accelerate is updated.\nError: {e}")
raise e
print(" -> Translating to Japanese (Context: PC Hardware)...")
system_prompt = (
"あなたはPCハードウェア動画の翻訳者です。\n"
"入力された英語を、日本の自作PCユーザー向けの自然な日本語に翻訳してください。\n"
"専門用語(Driver→ドライバ、Crash→クラッシュ)はカタカナで表記すること。\n"
"**翻訳後の日本語のみを出力してください。元の英語や解説は一切不要です。**"
)
# モデルが実際に配置されているメインデバイスを取得(input転送用)
if LOW_VRAM_MODE and hasattr(model, "device"):
main_device = model.device
else:
main_device = torch.device(device_str)
for seg in tqdm(segments, desc=" Translating", unit="line"):
original_text = seg["text"]
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": original_text}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# device_map="auto" の場合、入力は model.device に送るのが定石
model_inputs = tokenizer([text], return_tensors="pt").to(main_device)
with torch.no_grad():
generated_ids = model.generate(
model_inputs.input_ids,
attention_mask=model_inputs.attention_mask,
pad_token_id=tokenizer.eos_token_id,
max_new_tokens=128,
temperature=0.3,
do_sample=True
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
seg["text"] = response.strip()
# メモリお掃除
del model
del tokenizer
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
elif hasattr(torch, "xpu"):
torch.xpu.empty_cache()
return segments
# ---------------------------------------------------------
# 4. SRT書き出し
# ---------------------------------------------------------
def format_timestamp(seconds):
if seconds is None: return "00:00:00,000"
milliseconds = round(seconds * 1000.0)
hours = milliseconds // 3600000
milliseconds %= 3600000
minutes = milliseconds // 60000
milliseconds %= 60000
seconds = milliseconds // 1000
milliseconds %= 1000
return f"{hours:02d}:{minutes:02d}:{seconds:02d},{milliseconds:03d}"
def write_srt_from_segments(segments, srt_path):
tqdm.write(f"Writing SRT to: {srt_path}")
with open(srt_path, "w", encoding="utf-8") as f:
for i, seg in enumerate(segments):
start_str = format_timestamp(seg["start"])
end_str = format_timestamp(seg["end"])
text = seg["text"].strip()
if not text: continue
f.write(f"{i + 1}\n")
f.write(f"{start_str} --> {end_str}\n")
f.write(f"{text}\n\n")
# ---------------------------------------------------------
# 5. 音声スライス処理
# ---------------------------------------------------------
def slice_audio_by_silence(audio_path):
tqdm.write(" -> Loading audio & detecting silence...")
audio = AudioSegment.from_file(audio_path)
nonsilent_ranges = detect_nonsilent(
audio,
min_silence_len=MIN_SILENCE_LEN,
silence_thresh=SILENCE_THRESH
)
chunks = []
for start_i, end_i in nonsilent_ranges:
start_i = max(0, start_i - KEEP_SILENCE)
end_i = min(len(audio), end_i + KEEP_SILENCE)
chunk_audio = audio[start_i:end_i]
chunks.append({
"start_sec": start_i / 1000.0,
"end_sec": end_i / 1000.0,
"audio_segment": chunk_audio
})
tqdm.write(f" -> Audio split into {len(chunks)} segments.")
return chunks
# ---------------------------------------------------------
# 6. 個別のファイル処理ロジック (音質維持・最適化版)
# ---------------------------------------------------------
def process_video_vad(input_video_path, model_id, device):
input_path = Path(input_video_path)
temp_dir_name = input_path.stem + "_temp"
temp_dir = input_path.parent / temp_dir_name
temp_dir.mkdir(exist_ok=True)
full_audio_path = temp_dir / "full_audio.wav"
chunk_audio_path = temp_dir / "chunk_temp.wav"
en_srt_path = temp_dir / "en.srt"
jp_srt_path = temp_dir / "subs_jp.srt"
output_path = input_path.parent / (input_path.stem + "_jp_subtitled.mp4")
tqdm.write(f"\n--- Target: {input_path.name} ---")
tqdm.write(f" Temp Folder: {temp_dir_name}")
# 1. 音声抽出
if not full_audio_path.exists():
cmd_extract = [
"ffmpeg", "-y", "-i", str(input_path),
"-vn", "-acodec", "pcm_s16le", "-ar", "16000", "-ac", "1",
"-loglevel", "error", str(full_audio_path)
]
subprocess.run(cmd_extract, check=True)
# 2. スライス
sliced_chunks = slice_audio_by_silence(full_audio_path)
# 3. Whisperモデルのロード
print("\n -> Loading Whisper for Transcription...")
pipe = pipeline(
"automatic-speech-recognition",
model=model_id,
device=device,
dtype=torch.bfloat16 if device != "cpu" else torch.float32,
model_kwargs={"low_cpu_mem_usage": True}
)
# 4. 文字起こし (英語)
final_segments = []
generate_args = {}
if SOURCE_LANGUAGE:
generate_args["language"] = SOURCE_LANGUAGE
for chunk_data in tqdm(sliced_chunks, desc=" Transcribing (En)", unit="slice", leave=False):
chunk_data["audio_segment"].export(chunk_audio_path, format="wav")
offset = chunk_data["start_sec"]
try:
result = pipe(
str(chunk_audio_path),
batch_size=1,
return_timestamps=True,
generate_kwargs=generate_args
)
for inner_chunk in result["chunks"]:
text = inner_chunk.get("text", "").strip()
timestamp = inner_chunk.get("timestamp")
if text and timestamp:
start_ts, end_ts = timestamp
if end_ts is None: end_ts = start_ts + 5.0
final_segments.append({
"start": offset + start_ts,
"end": offset + end_ts,
"text": text
})
except Exception as e:
tqdm.write(f" Error on slice: {e}")
write_srt_from_segments(final_segments, en_srt_path)
tqdm.write(" -> English SRT saved.")
# Whisperメモリ解放
del pipe
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
elif hasattr(torch, "xpu"):
torch.xpu.empty_cache()
print(" -> Whisper unloaded. VRAM cleared.")
# 5. 日本語へ翻訳 (LLM使用)
final_segments = translate_text_segments_llm(final_segments, device)
# 6. 日本語SRT生成 & 結合
write_srt_from_segments(final_segments, jp_srt_path)
cmd_merge = [
"ffmpeg", "-y",
"-i", str(input_path),
"-i", str(jp_srt_path),
"-map", "0:v",
"-map", "0:a",
"-map", "1:s",
"-c:v", "copy",
"-c:a", "copy",
"-c:s", "mov_text",
"-metadata:s:s:0", "language=jpn",
"-loglevel", "error",
str(output_path)
]
subprocess.run(cmd_merge, check=True)
tqdm.write(f" -> Done! Saved as: {output_path.name}")
# ---------------------------------------------------------
# 7. メイン処理
# ---------------------------------------------------------
if __name__ == "__main__":
files = get_target_files()
if not files:
sys.exit("No video files found.")
device = get_device()
whisper_model_id = "openai/whisper-large-v3-turbo"
count = 0
for file in tqdm(files, desc="Total Progress", unit="video"):
if "_subtitled" in file.name or "_temp" in str(file): continue
try:
process_video_vad(file, whisper_model_id, device)
count += 1
except Exception as e:
tqdm.write(f"Error: {e}")
print(f"\nAll tasks finished. Processed {count} videos.")作った「translate.py」を「insanely-fast-whisper」に置く
「translate.py」と「翻訳したい動画」を「insanely-fast-whisper」に移動。
実行
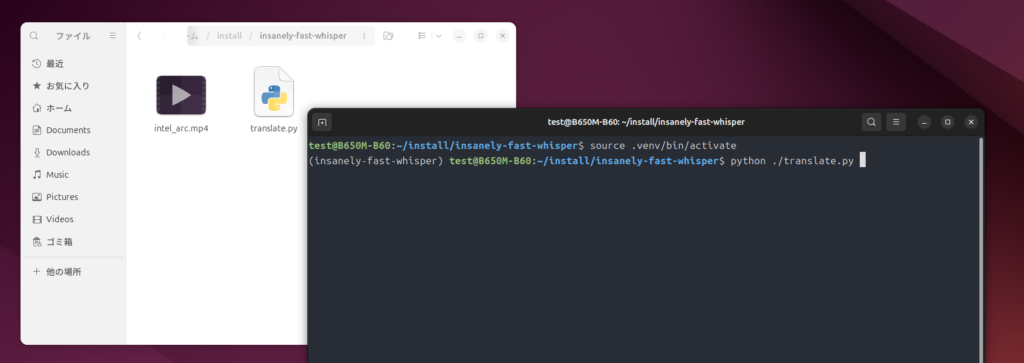
source .venv/bin/activate
python ./translate.py で実行します。
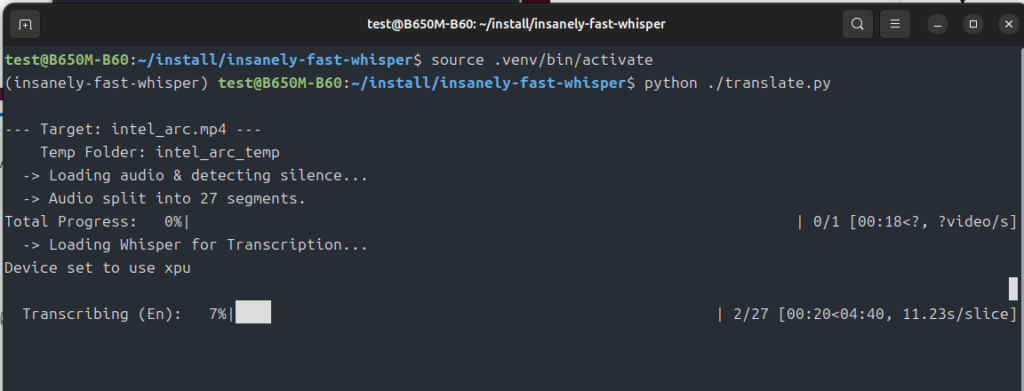
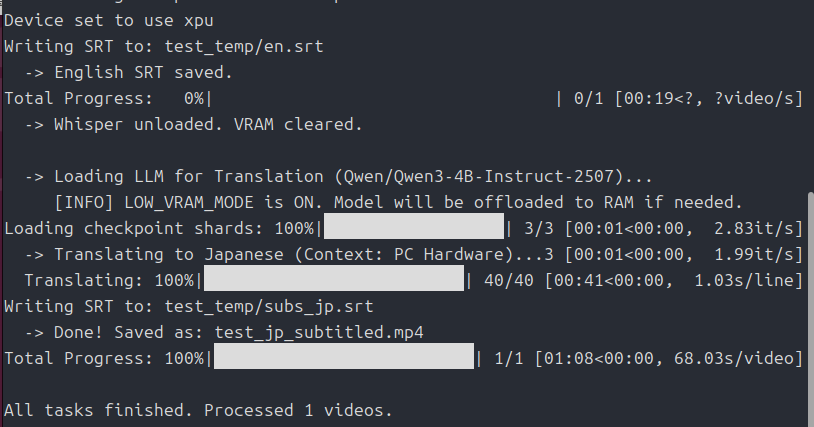
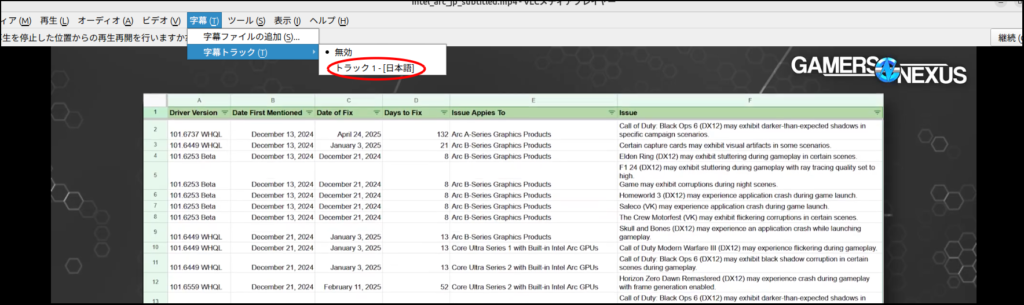
さて、気になるVRAM事情ですが・・・
このスクリプトは、「whisper」を使ってまず動画の音声を英文に起こします。
次に起こした英文を日本語に翻訳(意訳)していくわけです。
ただ、文字起こしまではVRAMが4GBもあれば大丈夫ですが・・・、
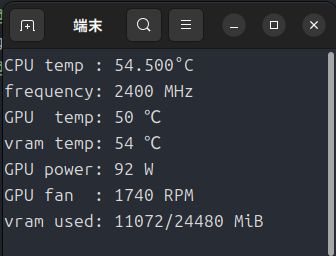
VRAM12GBくらいあれば大丈夫ですが、それより少ないグラフィックスカードだとクラッシュするかもしれないので、
ただ、自分のグラフィックスカードでは試せないので、もし「B570」や「A750」で試された方がいたら報告していただけると助かります。
ちなみにモデルファイルも変更することができます。
こちらを参考にモデルを変更してみるのも良いかと。
ただ、あまり軽いモデルを選ぶとまともに翻訳してくれなくなります。
重たいモデルファイルを選べば翻訳の質は向上しますが、終了までの時間が飛躍的に伸びます。
RadeonのRX9000シリーズやGeForceのRTX4000シリーズ以降を使っている方なら「fp8」のモデルも使えるかもしれません。
最後に
Geminiがあまりに優秀なので、お遊びでgradio対応版も作ってみました。
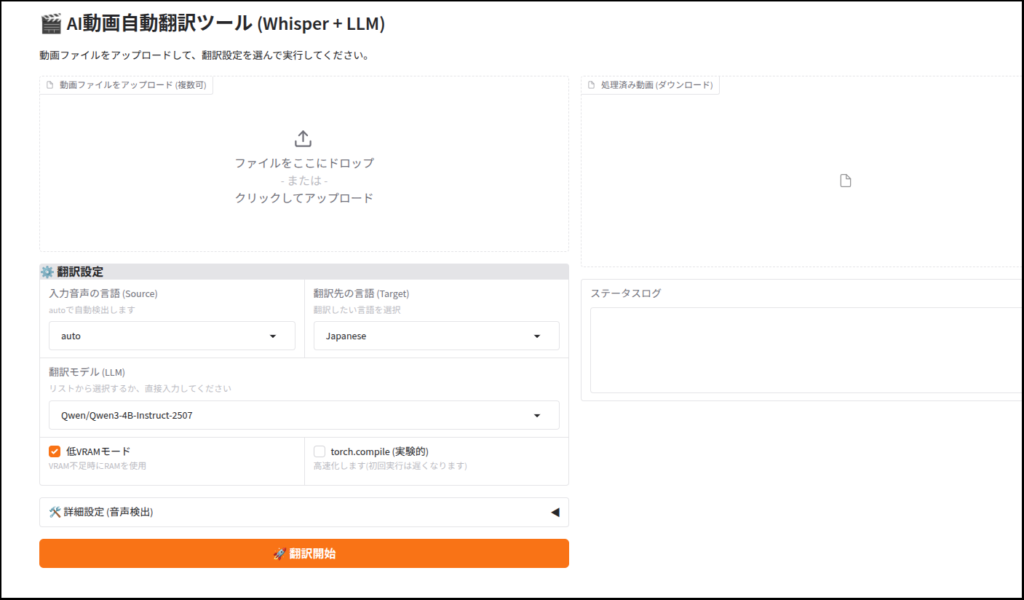
今回は以上です。
自分が使っている「Pro B60」ですが、記事を書いている現在は在庫が全滅しています。
価格.comでも全て空ですね。
こんな高価なのは、無理に買わなくても下のB580の方が個人的にオススメです。

B580は玄人志向のDFが安く、全長240mmと小さいので取り回しも良くオススメです。
負荷中はちょっとうるさいかもしれませんが、B60よりははるかにマシでしょう。
が、ジワジワ価格が上昇しているようです・・・。

RX9060XTの16GB版ですが、やはり値段がかなり上がってきてますね。


コメント