前回の記事でIntel Arc用の自動翻訳を紹介しました。
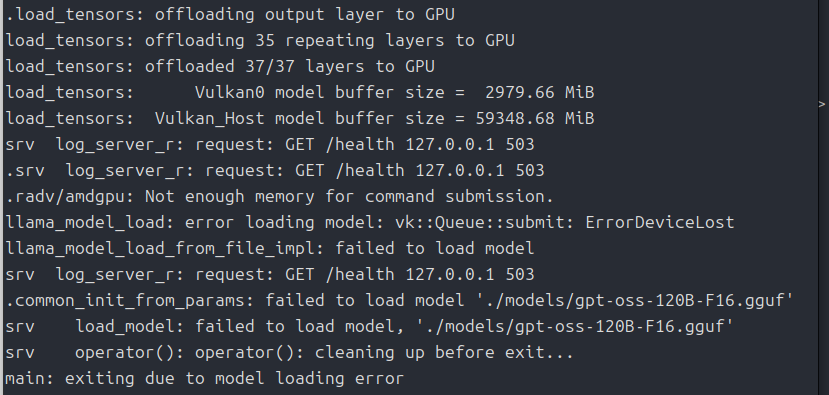
今回「RX9060XT 16GB」を使う機会があったので、動作確認しようと思ったのですが翻訳部分がうまく動きませんでした。
どうやらvulkanバックエンドではgpt-ossのモデルが読み込めていないようです。
llama.cppをvulkanでビルド(ROCmより速い!?)
上の記事の時点で動作はしていたので、何か自分でも忘れているのかもしれませんね。
ということで、ROCmで動くようにちょっと変更したスクリプトを書き留めておきます。
それでは、やっていきましょう。
環境の準備
- ROCmのインストール(この記事の「ROCmのインストール」を参照。ただし、ROCmが動作するRadeonは現在RDNA2以上(VEGAは?)だと思います)。
- ffmpegのインストール
インストールスクリプト
vulkanとsyclをの部分を削除して、ROCmを追記しました。
pytorchもROCm用のみにしてあります。
#!/bin/bash
#インストールに必要なライブラリ等をインストール
sudo apt update
sudo apt install git
sudo apt install curl
sudo apt install build-essential cmake
#sudo apt install ffmpeg #自前でビルドした場合はこの行はコメントアウトしてください。
# uvをcurlでインストール
curl -LsSf https://astral.sh/uv/install.sh | sh
source $HOME/.local/bin/env
mkdir -p $HOME/install/langtrans_llama_rocm/input
mkdir -p $HOME/install/langtrans_llama_rocm/models
cd ~/install/langtrans_llama_rocm
#uvでpython3.13環境を作る
uv venv --python 3.13 --seed
source .venv/bin/activate
uv pip install openai requests
#whisperをクローン
git clone https://github.com/openai/whisper.git
cd whisper
#Radeonの場合のpytorchのインストール
pip install --pre torch torchvision --index-url https://download.pytorch.org/whl/nightly/rocm7.1
#whisperのセットアップ
uv pip install -U pip setuptools
uv pip install .
cd ../
#準備とllama.cppのクローン
sudo apt install -y cmake g++ libcurlpp-dev
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
#CPU用ビルド(ggufの変換で使う)
mkdir build-cpu
cmake -B build-cpu
cmake --build build-cpu --config Release -j$(nproc)
# hipconfig コマンドで HIP コンパイラの場所を取得して変数 HIPCXX に設定
HIPCXX="$(hipconfig -l)/clang"
# HIP のルートパスを取得して変数 HIP_PATH に設定
HIP_PATH="$(hipconfig -R)"
# CMake でビルド設定を生成
cmake -S . -B build-rocm \
-DGGML_HIP=ON \
-DGPU_TARGETS=gfx1200 \
-DCMAKE_BUILD_TYPE=Release
# 生成した build-rocm ディレクトリでビルドを実行
cmake --build build-rocm --config Release -- -j $(nproc)「gfx1200」の部分は、自分が使っているRadeonに対応した数値に変更してください。
- RDNA4の場合は「gfx1200」
- RDNA3の場合は「gfx1100」
- RDNA2の場合は「gfx1030」
- だったかと思いますが・・・。
メインスクリプト(ROCm用)
import os
import sys
import subprocess
import time
import requests
import re
import torch
from openai import OpenAI
from pathlib import Path
# ==========================================
# 設定変数(環境に合わせて調整してください)
# ==========================================
# --- 翻訳設定 ---
LANGUAGE = "日本語" #デフォルトは「日本語」です
BATCH_SIZE = 15 # 一回にまとめてLLMに渡す字幕の数
LIMIT = None # None に設定すると全件処理(デバッグ用)
MODEL = "local-model"
TEMPERATURE = 0.3
# --- whisperモデル ---
WHISPER_MODEL = "medium" #文字起こしに使うモデルです。"tiny","base","small","medium","large","turbo"などから選んで下さい
# --- サーバー設定 ---
MODEL_PATH = "./models/gpt-oss-20b-F16.gguf" # 使用するモデルのパス
#MODEL_PATH = "./models/gpt-oss-120b-F16.gguf" # 使用するモデルのパス
CONTEXT_LENGTH = 16392 #「0」だとVRAM空き容量分をほぼ全てコンテキスト長に当てます(実際は学習モデルによります)
CPU_MOE = 0 # 「0」に設定すると、全てのレイヤーをGPUに乗せます
N_GPU_LAYERS = 99 # 学習モデルをいくつGPUレイヤーに乗せるかの設定値(基本的に「CPU_MOE」で調整します)
PORT = 8080
BASE_URL = f"http://localhost:{PORT}/v1"
#===========================================
#以下はスクリプトの一貫です。触る必要はありません
#===========================================
#ファイルを取得
# フォルダ内を調べて、拡張子が一致するものだけをリストにする
# 対象の拡張子
extensions = {".mp4", ".mkv", ".avi"}
# 最初に見つかった1つだけを FILE に代入。見つからなければ None
FILE = next((p for p in Path("./input").iterdir() if p.suffix.lower() in extensions), None)
if FILE:
print(f"「{FILE.name}」が見つかりました。")
else:
print("inputフォルダの中に動画ファイルが見つかりません。")
sys.exit(1)
#================================================
#パスの取得
temp_dir = Path(FILE.stem + "_temp")
temp_dir.mkdir(exist_ok=True)
audio_path = temp_dir / Path(FILE.stem + ".wav")
input_srt = temp_dir / Path(FILE.stem + ".srt")
translated_srt = temp_dir / Path(FILE.stem + "_translated.srt")
#===========================================
# デバイスの自動判別 (Whisper / Standard Transformers用)
if hasattr(torch, "xpu") and torch.xpu.is_available():
DEVICE = "xpu"
elif torch.cuda.is_available():
DEVICE = "cuda"
else:
DEVICE = "cpu"
print(f"使用デバイス: {DEVICE}")
#===========================================
#llama.cppのサーバーコマンド
if DEVICE == "xpu":
BACKEND = "sycl"
elif DEVICE == "cuda":
BACKEND = "rocm"
else:
BACKEND = "cpu"
SERVER_BIN = f"./llama.cpp/build-{BACKEND}/bin/llama-server"
# 確認用
print(f"使用するバックエンド: {BACKEND}")
#===========================================
# 1. 動画から音声を抜き出す処理
def process_video(video_path):
subprocess.run(["ffmpeg", "-i", str(video_path), "-vn", "-ac", "1", "-ar", "16000", str(audio_path), "-loglevel", "error"], check=True)
# 2. 音声からwhisperで文字起こしする処理
def run_whisper(audio_path, temp_dir):
print(f"--- Whisperの{WHISPER_MODEL}モデルで文字起こし中 ---")
if DEVICE == "xpu":
subprocess.run([
"whisper", str(audio_path),
"--model", WHISPER_MODEL,
"--output_dir", str(temp_dir),
"--output_format", "srt",
"--device", "xpu"
], check=True)
else:
subprocess.run([
"whisper", str(audio_path),
"--model", "medium",
"--output_dir", str(temp_dir),
"--output_format", "srt"
], check=True)
def start_llama_server():
"""llama-serverを起動し、準備ができるまで待機する"""
if DEVICE == "cpu":
cmd = [
SERVER_BIN,
"-m", MODEL_PATH,
"--port", str(PORT),
]
else:
cmd = [
SERVER_BIN,
"-m", MODEL_PATH,
"--port", str(PORT),
"-ngl", str(N_GPU_LAYERS),
"-c", str(CONTEXT_LENGTH),
"--n-cpu-moe", str(CPU_MOE)
]
print(f"llama-server を起動中: {' '.join(cmd)}")
# ログが混ざらないよう、標準出力は捨てます
process = subprocess.Popen(cmd, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
#process = subprocess.Popen(cmd, stdout=None, stderr=None)
# 起動完了を待機 (ポーリング)
print("サーバーの準備完了を待っています...", end="", flush=True)
max_retries = 90 # 大きなモデル用に長めに設定
for i in range(max_retries):
try:
# llama.cppのヘルスチェック用エンドポイントを確認
response = requests.get(f"http://localhost:{PORT}/health", timeout=5)
if response.status_code == 200:
print("\nサーバー準備完了!")
return process
except requests.exceptions.ConnectionError:
pass
print(".", end="", flush=True)
time.sleep(1)
process.terminate()
raise TimeoutError("\nサーバーの起動がタイムアウトしました。パスやモデルを確認してください。")
def translate_batch(client, batch_content):
"""思考プロセスを表示しつつ翻訳する(ストリーミング版)"""
system_prompt = (
f"あなたはプロの翻訳家です。SRT形式を守り、英語を{LANGUAGE}に翻訳してください。\n"
"インデックスがずれないようにしてください。\n"
"思考プロセスを出力しても構いませんが、最終的な回答は必ずSRT形式にしてください。"
)
print(f"翻訳後の言語: {LANGUAGE} ")
try:
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": batch_content}
],
temperature=TEMPERATURE,
stream=True
)
full_content = ""
print("\n--- 思考・翻訳中 ---")
for chunk in response:
content = chunk.choices[0].delta.content
if content:
print(content, end="", flush=True)
full_content += content
print("\n-------------------\n")
# <think>タグの中身を除去して保存用テキストを作成
clean_content = re.sub(r'<think>.*?</think>', '', full_content, flags=re.DOTALL).strip()
return clean_content
except Exception as e:
print(f" [!] エラー: {e}")
return None
def input_srt_translate(input_srt, translated_srt):
if not os.path.exists(input_srt):
print("エラー: 字幕ファイルが見つかりません。")
return
# 2. クライアント初期化
client = OpenAI(base_url=BASE_URL, api_key="sk-no-key-required")
# 3. 字幕ファイルの読み込みと処理
with open(input_srt, 'r', encoding='utf-8') as f:
content = f.read()
raw_blocks = [b.strip() for b in re.split(r'\n\s*\n', content.strip()) if b.strip()]
indices = []
for b in raw_blocks:
lines = b.split('\n')
match = re.search(r'(\d+)$', lines[0])
if match:
indices.append(int(match.group(1)))
detected_limit = max(indices) if indices else 0
final_limit = LIMIT if LIMIT is not None else detected_limit
print("--- 翻訳開始 ---")
target_blocks = []
for block in raw_blocks:
lines = block.split('\n')
match = re.search(r'(\d+)$', lines[0])
if match and int(match.group(1)) > final_limit:
break
target_blocks.append(block)
translated_full_text = []
# 4. バッチ処理実行
for i in range(0, len(target_blocks), BATCH_SIZE):
batch = target_blocks[i : i + BATCH_SIZE]
batch_text = "\n\n".join(batch)
current_range = f"{i+1}~{min(i + BATCH_SIZE, len(target_blocks))}"
print(f"[{current_range} / {len(target_blocks)}] 処理中...")
result = translate_batch(client, batch_text)
translated_full_text.append(result if result else batch_text)
# 5. 保存
with open(translated_srt, 'w', encoding='utf-8') as f:
f.write("\n\n".join(translated_full_text) + "\n")
print("--- 完了! 翻訳した字幕を出力しました ---")
def Combining_srt_an_video(video_path, srt_path, server_process, temp_dir):
try:
FILE = Path(video_path)
output_path = Path(f"{temp_dir}") / f"{Path(video_path).stem}_subtitled.mp4"
print(f"--- 字幕と動画を結合中 ---")
# -c copy: 映像と音声を再エンコードせずにコピー
# -c:s mov_text: MP4で利用可能な字幕形式に変換
# -map 0: 元動画の全ストリームを使用
# -map 1: 字幕ファイルのストリームを使用
if LANGUAGE == "日本語":
cmd = [
"ffmpeg", "-y",
"-i", str(FILE),
"-i", str(srt_path),
"-c", "copy",
"-c:s", "mov_text",
"-map", "0",
"-map", "1",
"-metadata:s:s:0", "language=jpn",
"-metadata:s:s:0", "title=Japanese",
str(output_path),
"-loglevel", "error"
]
else:
cmd = [
"ffmpeg", "-y",
"-i", str(FILE),
"-i", str(srt_path),
"-c", "copy",
"-c:s", "mov_text",
"-map", "0",
"-map", "1",
"-metadata:s:s:0", "language=xxx",
"-metadata:s:s:0", "title=xxx",
str(output_path),
"-loglevel", "error"
]
try:
subprocess.run(cmd, check=True)
print("--- 結合完了 ---")
except subprocess.CalledProcessError as e:
print(f"結合エラー: {e}")
finally:
# サーバーを確実に停止
if server_process:
print("\nサーバーを停止しています...")
server_process.terminate()
try:
server_process.wait(timeout=10) # 10秒待機
except subprocess.TimeoutExpired:
print("応答がないため強制終了します...")
server_process.kill() # 強制終了
server_process.wait()
print("サーバーを正常に終了しました。")
if __name__ == "__main__":
if FILE:
process_video(FILE)
run_whisper(audio_path, temp_dir)
server_process = None
server_process = start_llama_server()
input_srt_translate(input_srt, translated_srt)
Combining_srt_an_video(FILE, translated_srt, server_process, temp_dir)変更したのは2点。
if DEVICE == “xpu”:
BACKEND = “sycl”
elif DEVICE == “cuda”:
BACKEND = “rocm” #ここを”vulkan”から”rocm”に変更
else:
BACKEND = “cpu”
SERVER_BIN = f”./llama.cpp/build-{BACKEND}/bin/llama-server”
MODEL_PATH = “./models/gpt-oss-20b-F16.gguf”
ROCmで「gpt-oss-120b-F16.gguf」を使った場合、メインメモリは55GBくらい使ってしまっていたので、20bに変更しておきました。
以下から「gpt-oss-20b-F16.gguf」のダウンロードができます。

最後に
なぜ、vulkanで動かなくなってしまったのかよくわかっていません。
もしわかったら、追記すると思います。
今回は以上です。

コメント