Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。
以前、Intel ARC B570でチャットAIのllama.cppを動作させる記事を書きましたが、今回はRadeon RX9060XTで動かします。
VRAMが16GBとなったことでB570とくらべてどれだけ有利に働くか調べてみましょう。
ちなみにLMStudioでチャットAIを使う記事をこちらで書きましたが、llama.cppの方が動作が速いという情報を得ました。以下の記事を参考にさせていただいています。
「Ubuntu日和」のあわしろいくや氏の記事です。
「Ubuntu日和」はいつも読ませていただいております。
それでは、いってみましょう。
llama.cppでチャットAIを使うには
B570の時にも書きましたが、おおまかな手順です。
- llama.cppのソースコードをダウンロード
- llama.cppをCPU用とROCm用、それぞれをビルドによって対応させる
- CPU用にビルドしたllama.cppで、safetensorsファイルをGGUFファイルに変換する。
- GGUFファイルをROCm用にビルドしたllama.cppで動作させる。
以上になりますが、このうち「safetensorsファイルをGGUFファイルに変換する」手順はやりません。以前と同じです。
それに伴ってモデルファイルのダウンロードも今回は行いません。
以前のモデルファイルを使用します(まだの方は前回の記事の「モデルファイルのダウンロード」を参考にダウンロードと変換をしましょう)。
ROCmをインストール

上記リンクから辿っていって、目的のファイル「amdgpu-install_xxxxxxxxx_all.deb」をダウンロードしましょう。
2025/10/31現在、RX9060XT用のdebファイルは「amdgpu-install_7.1.70100-1_all.deb 」でした。
なのでもしシェルスクリプトで書くなら
cd ~
mkdir -p install
cd install
wget https://repo.radeon.com/amdgpu-install/latest/ubuntu/noble/amdgpu-install_7.1.70100-1_all.debとなるでしょう。
さらにそこから、
sudo apt install ./amdgpu-install_7.1.70100-1_all.deb
sudo apt update
sudo amdgpu-install --usecase=graphics,rocm
sudo usermod -aG render $USER
sudo usermod -aG video $USERとすれば、ROCm(と、グラフィックスドライバ)のインストールは完了です。
一度再起動しましょう。
llama.cppのソースコードをダウンロード
B570の時と同じです。
cd ~
mkdir -p install
cd ./install
mkdir -p llama.cpp_build
cd ./llama.cpp_build上記コマンドで、ダウンロードする場所を確保します。そうしたら次に、
sudo apt install git cmake g++ libcurlpp-dev
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cppで、ビルドに必要なファイルとllama.cppをダウンロード。
次にカレントディレクトリをダウンロードしたllama.cppに移動します。
llama.cppをCPU用にビルド
mkdir build-cpu
cmake -B build-cpu
time cmake --build build-cpu --config Release -j$(nproc)ROCmでの動作だけなら必要ありませんが、今回は動作速度の比較のためCPU用でもビルドします。
ROCm用にビルド
https://github.com/ggml-org/llama.cpp/blob/master/docs/build.md
ビルド手順は上記のリンクを参考にしました。
# hipconfig コマンドで HIP コンパイラの場所を取得して変数 HIPCXX に設定
HIPCXX="$(hipconfig -l)/clang"
# HIP のルートパスを取得して変数 HIP_PATH に設定
HIP_PATH="$(hipconfig -R)"
# CMake でビルド設定を生成
cmake -S . -B build-rocm \
-DGGML_HIP=ON \
-DGPU_TARGETS=gfx1200 \
-DCMAKE_BUILD_TYPE=Release
# 生成した build-rocm ディレクトリでビルドを実行
cmake --build build-rocm --config Release -- -j $(nproc)
こちらもビルド用のフォルダを作ってその中で作業します。
llama.cppのビルドにROCmが必要になります。
ファイル構成
今回はモデルファイルをこんな感じで配置しています。

llama.cppのベンチマークを使う(CPU)
前回の記事では使わなかったのですが、今回は「llama_bench」を使って測定していきます。
#カレントディレクトリは「llama.cpp_build」
time ./llama.cpp/build-cpu/bin/llama-bench -m ./gpt-oss-20B-F16.gguf -t $(nproc)
#または
time ./llama.cpp/build-cpu/bin/llama-bench -m ./gpt-oss-20B-F16.gguf今回は「-t $(nproc)」は付けていません。
自分の環境(Ryzen9 7900無印)では、「-t $(nproc)」を付けると逆に遅くなるようです。

llama.cppのベンチマークを使う(RX9060XT)
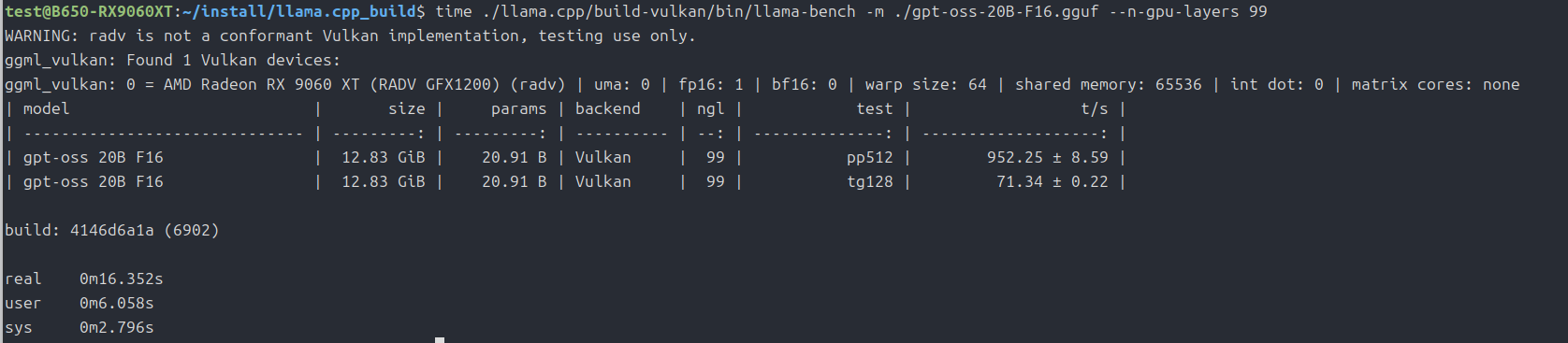
まずは「gpt-oss-20b」から。
time ./llama.cpp/build-rocm/bin/llama-bench -m ./gpt-oss-20B-F16.gguf --n-gpu-layers 99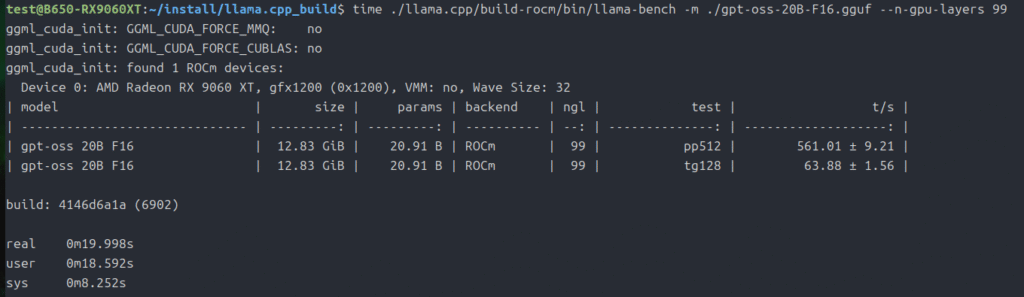
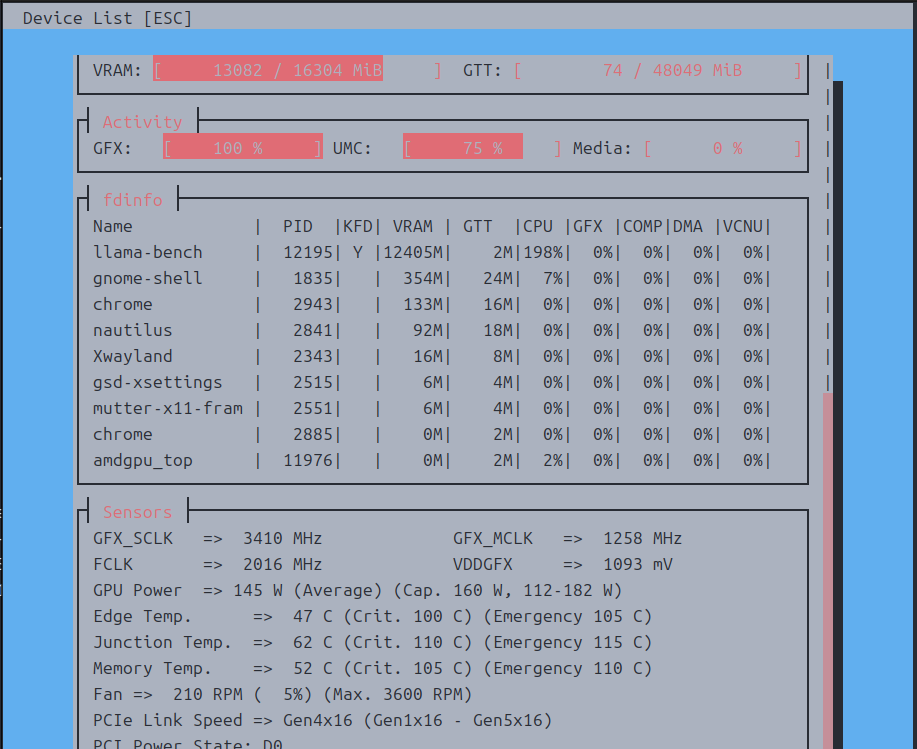
次は「gpt-oss-120b」です。
メインメモリも併用しないと動作しなかったので、丁度いいバランスを「–n-cpu-moe 29」でとっています。
time ./llama.cpp/build-rocm/bin/llama-bench -m ./gpt-oss-120B-F16.gguf --n-gpu-layers 99 --n-cpu-moe 29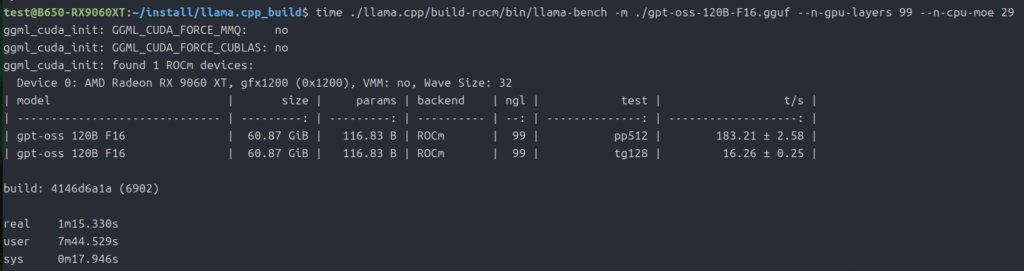

以前のデータと比較するために
B570の時はベンチマークを使わなかったので、このままでは比較ができません。
なので、ここは例の「サンクトペテルスブルクのパラドックス」でいきましょう。
まずは20bから。
time ./llama.cpp/build-rocm/bin/llama-cli -m ./gpt-oss-20B-F16.gguf --n-gpu-layers 99 -p "偏りのないコインを表が出るまで投げ続け、表が出たときに、賞金をもらえるゲームがあるとする。もらえる賞金は、1回目に表が出たら1円、1回目は裏が出て2回目に表が出たら倍の2円、2回目まで裏が出ていて3回目に初めて表が出たらそのまた倍の4円、3回目まで 裏が出ていて4回目に初めて表が出たらそのまた倍の8円、というふうに倍々で増える賞金がもらえるというゲームである。ここで、このゲームには参加費(=賭け金)が必要であるとしたら、参加費の金額が何円までなら払っても損ではないと言えるだろうか。"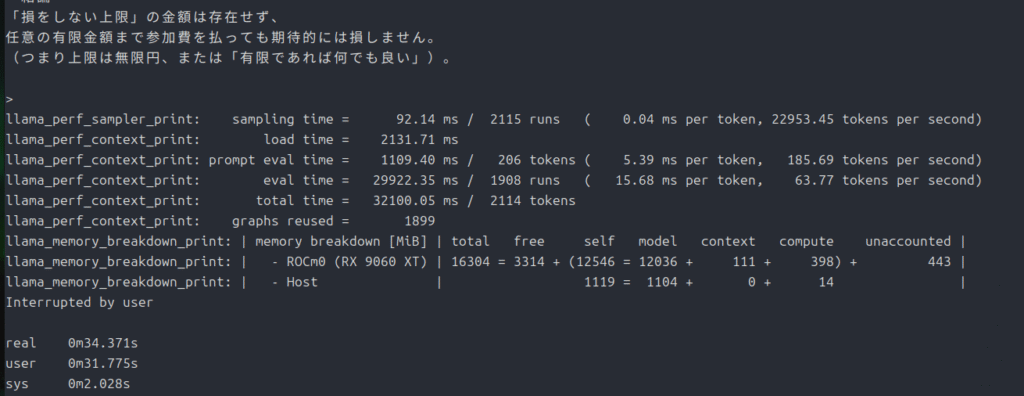
次は120b。
time ./llama.cpp/build-rocm/bin/llama-cli -m ./gpt-oss-120B-F16.gguf --n-gpu-layers 99 --n-cpu-moe 29 -p "偏りのないコインを表が出るまで投げ続け、表が出たときに、賞金をもらえるゲームがあるとする。もらえる賞金は、1回目に表が出たら1円、1回目は裏が出て2回目に表が出たら倍の2円、2回目まで裏が出ていて3回目に初めて表が出たらそのまた倍の4円、3回目まで 裏が出ていて4回目に初めて表が出たらそのまた倍の8円、というふうに倍々で増える賞金がもらえるというゲームである。ここで、このゲームには参加費(=賭け金)が必要であるとしたら、参加費の金額が何円までなら払っても損ではないと言えるだろうか。"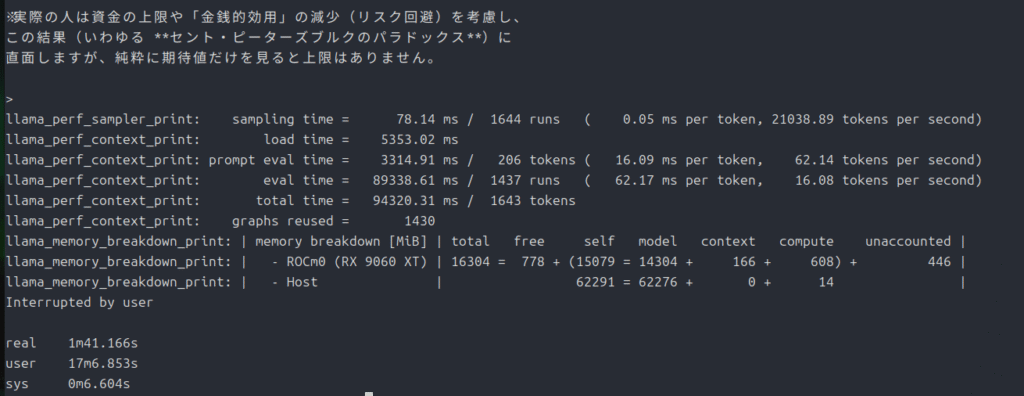
最後に
やはりモデルファイルがVRAMに収まってしまう場合は速度が俄然違ってきます。
gpt-oss-120bは65GBという大容量なので、当分はVRAMに収まるなんてことはなさそうですね。


一応存在はするんですが(VRAM 96GB)、買うには現実的でない金額になります。
今回は以上です。
追記
今回紹介したllama.cppにブラウザのUIを使って利用する記事を書きました。




コメント