Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。
FramePack-eichiというフォーク版での動作には成功していましたが、肝心の本家ではVAEデコードでクラッシュする問題が解決できないでいましたが、このたび動作に成功しました。
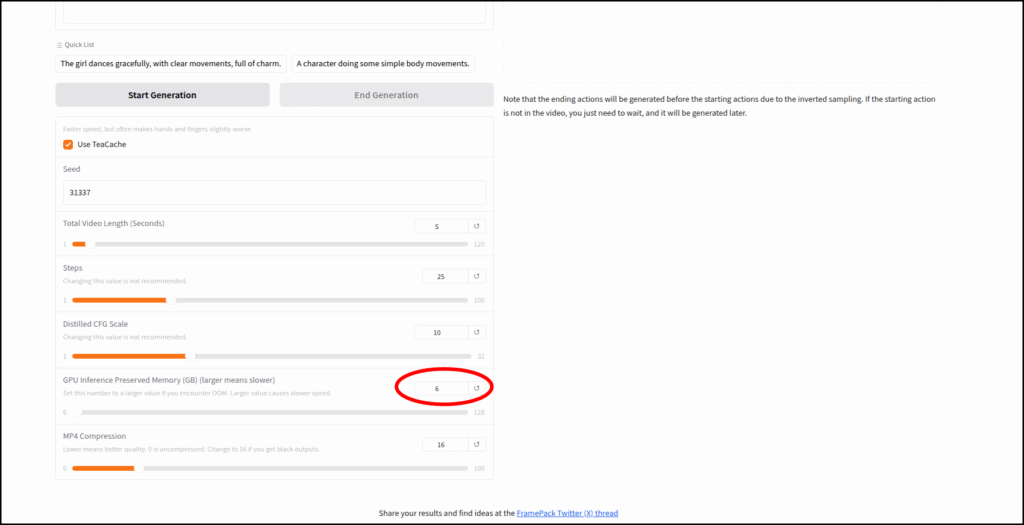
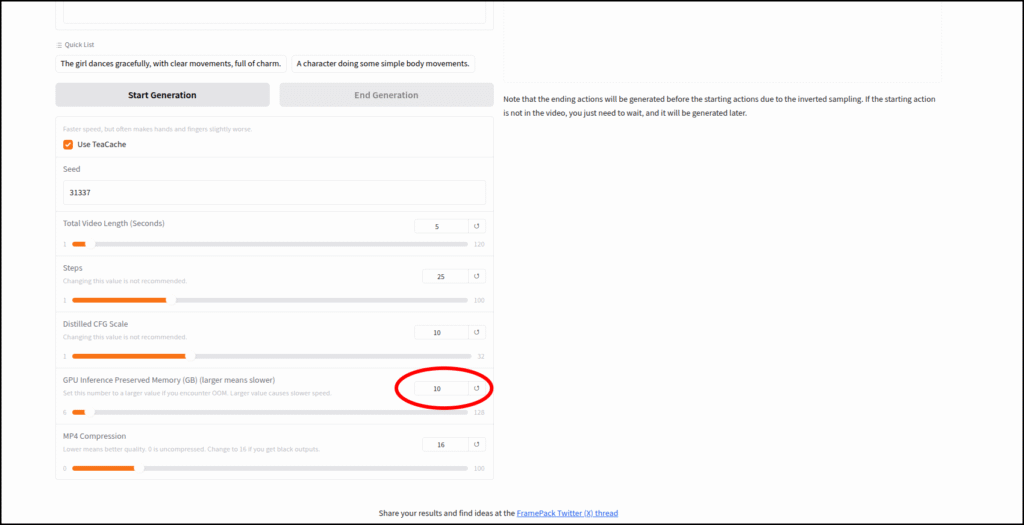
解決方法は単純で、gradioの「GPU Inference Preserved Memory (GB) (larger means slower)」の値を10GBに変更するだけでした。
以下は導入手順です。Ubuntu編ですがやっていること自体はWindowsと何も変わりません。
- Intel ARC用のmemory.pyの作成
- 本家FramePackのダウンロード
- 書き換えたmemory.pyを「diffusers_helper」に配置
- IPEXとrequirements.txtのインストール
- FramePackを起動し、「GPU Inference Preserved Memory (GB) (larger means slower)」のスライドを10GBに変更
以上です。
eichiのUbuntu編、Windows編が過去記事にありますが、eichiをダウンロードしない分簡単だと思います。過去記事を参照してください。
以下はUbuntuでの導入スクリプトですが、これまでの記事を読まれている方にとっては必要ないと思います。
#!/bin/bash
sudo apt update
sudo apt install -y git unzip python3 python3-pip python3-venv
sudo apt install -y libgoogle-perftools-dev
cd ~
mkdir -p install
cd install
touch memory.py
cat << 'EOF' > memory.py
#!/bin/bash
# By lllyasviel (XPU対応版)
import torch
cpu = torch.device('cpu')
gpu = torch.device(f"xpu:{torch.xpu.current_device()}")
gpu_complete_modules = []
class DynamicSwapInstaller:
@staticmethod
def _install_module(module: torch.nn.Module, **kwargs):
original_class = module.__class__
module.__dict__['forge_backup_original_class'] = original_class
def hacked_get_attr(self, name: str):
if '_parameters' in self.__dict__:
_parameters = self.__dict__['_parameters']
if name in _parameters:
p = _parameters[name]
if p is None:
return None
if isinstance(p, torch.nn.Parameter):
return torch.nn.Parameter(p.to(**kwargs), requires_grad=p.requires_grad)
else:
return p.to(**kwargs)
if '_buffers' in self.__dict__:
_buffers = self.__dict__['_buffers']
if name in _buffers:
return _buffers[name].to(**kwargs)
return super(original_class, self).__getattr__(name)
module.__class__ = type('DynamicSwap_' + original_class.__name__, (original_class,), {
'__getattr__': hacked_get_attr,
})
return
@staticmethod
def _uninstall_module(module: torch.nn.Module):
if 'forge_backup_original_class' in module.__dict__:
module.__class__ = module.__dict__.pop('forge_backup_original_class')
return
@staticmethod
def install_model(model: torch.nn.Module, **kwargs):
for m in model.modules():
DynamicSwapInstaller._install_module(m, **kwargs)
return
@staticmethod
def uninstall_model(model: torch.nn.Module):
for m in model.modules():
DynamicSwapInstaller._uninstall_module(m)
return
def fake_diffusers_current_device(model: torch.nn.Module, target_device: torch.device):
if hasattr(model, 'scale_shift_table'):
model.scale_shift_table.data = model.scale_shift_table.data.to(target_device)
return
for _, p in model.named_modules():
if hasattr(p, 'weight'):
p.to(target_device)
return
def get_cuda_free_memory_gb(device=None):
if device is None:
device = gpu
if device.type == "xpu":
try:
props = torch.xpu.get_device_properties(device)
total_memory = props.total_memory
allocated = torch.xpu.memory_allocated(device)
free = total_memory - allocated
return free / (1024 ** 3)
except Exception as e:
print("[Warning] Failed to get XPU memory info:", e)
return 0
# fallback for CUDA (if you run on CUDA system)
if device.type == "cuda":
try:
memory_stats = torch.cuda.memory_stats(device)
bytes_active = memory_stats.get('active_bytes.all.current', 0)
bytes_reserved = memory_stats.get('reserved_bytes.all.current', 0)
bytes_free_cuda, _ = torch.cuda.mem_get_info(device)
bytes_inactive_reserved = bytes_reserved - bytes_active
bytes_total_available = bytes_free_cuda + bytes_inactive_reserved
return bytes_total_available / (1024 ** 3)
except Exception as e:
print("[Warning] Failed to get CUDA memory info:", e)
return 0
return 0
def move_model_to_device_with_memory_preservation(model, target_device, preserved_memory_gb=0):
print(f'Moving {model.__class__.__name__} to {target_device} with preserved memory: {preserved_memory_gb} GB')
for m in model.modules():
if get_cuda_free_memory_gb(target_device) <= preserved_memory_gb:
return
if hasattr(m, 'weight'):
m.to(device=target_device)
model.to(device=target_device)
return
def offload_model_from_device_for_memory_preservation(model, target_device, preserved_memory_gb=0):
print(f'Offloading {model.__class__.__name__} from {target_device} to preserve memory: {preserved_memory_gb} GB')
for m in model.modules():
if get_cuda_free_memory_gb(target_device) >= preserved_memory_gb:
return
if hasattr(m, 'weight'):
m.to(device=cpu)
model.to(device=cpu)
return
def unload_complete_models(*args):
for m in gpu_complete_modules + list(args):
m.to(device=cpu)
print(f'Unloaded {m.__class__.__name__} as complete.')
gpu_complete_modules.clear()
return
def load_model_as_complete(model, target_device, unload=True):
if unload:
unload_complete_models()
model.to(device=target_device)
print(f'Loaded {model.__class__.__name__} to {target_device} as complete.')
gpu_complete_modules.append(model)
return
EOF
git clone https://github.com/lllyasviel/FramePack.git
mv ./memory.py ./FramePack/diffusers_helper
cd ./FramePack
python3 -m venv venv
source ./venv/bin/activate
python -m pip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/xpu
python -m pip install intel-extension-for-pytorch==2.7.10+xpu oneccl_bind_pt==2.7.0+xpu --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
pip install -r ./requirements.txt
python ./demo_gradio.py --inbrowser
では今回は生成までやってみます

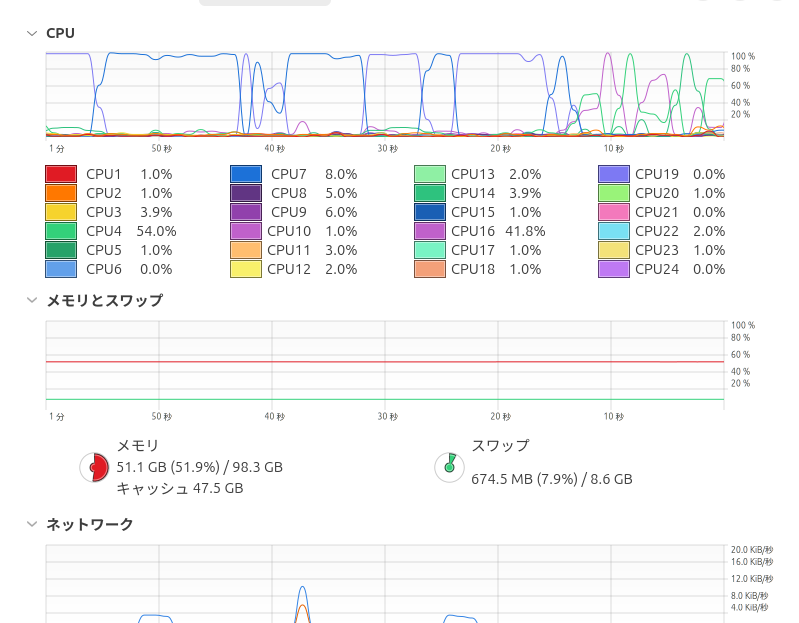
何度か試してみたんですが、生成時間は結構ばらつきが大きく13分を切ることもありました。
巷でけっこう言われているメインメモリの使用量はやはり多いです。
64GBはあった方が良いんじゃないでしょうか。
GeForceだともっと早いんでしょうね。持ってないので試せませんが。
今回使ったグラフィックスボードです。

SPARKLE Intel Arc B580 TITAN OC 12GB GPU
SPARKLE Intel Arc B580 グラフィックカードOC版 トリプルファン「TITAN」シリーズ がグラフィックボードストアでいつでもお買い得。当日お急ぎ便対象商品は、当日お届け可能です。アマゾン配送商品は、通常配送無料(一部除...
amzn.to
今はChallengerの方が安くていいですね。

Amazon | ASRock Intel Arc B580 Challenger PCIe 5.0対応 2.8GHz 12GB OC GDDR6搭載 ビデオカード 国内正規代理店品 B580 CL 12GO | ASRock | グラフィックボード 通販
ASRock Intel Arc B580 Challenger PCIe 5.0対応 2.8GHz 12GB OC GDDR6搭載 ビデオカード 国内正規代理店品 B580 CL 12GOがグラフィックボードストアでいつでもお買い得。当日...
amzn.to
今回は以上です。
コメント