Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。
「YouTube」などそもそも自動翻訳機能があるサービスだと、翻訳なんてありがたくもない当たり前の機能ですよね。
今回は、そういったサービスがない動画で「音声を自動翻訳して字幕表示できるようにする」ソフトを記事にします。
動画の言語は自動判別になっていますので、英語に限らず翻訳できます。
現在は非公開となっていますが、今までにこの手の記事は3つ書きました。
この3つは、実は内部処理で「英文ひとつ」に対し、「翻訳文をひとつ」返すという処理になっていました。
このため、全体としての翻訳文の意味がわかりにくくなる場合がありました。
今回はこのあたりに手を入れ、ある程度まとまった英文を渡し、まとめて翻訳するという変更が入っています。
今までは「Qwen3」をメインにしていましたが、今回は「gpt-oss」を使っています。
ただし、前回までのようにスクリプトの中で外部ライブラリを呼び出して動かすという方法ではなく、「whisper」と「llama.cpp」をクローンしてメインスクリプトから呼び出す方法をとっています。
かなり大掛かりな変更だったため、デバッグも十分ではないかもしれません。
一応まっさらなUbuntuを入れ直してインストールからテストしていますが、何か不具合があったら連絡していただけるとうれしいです。
あと、今回のスクリプトはUbuntu用です。
開発は「Intel Arc」でやっています。
ソースコード自体は「GeForce」や「Radeon」でも動くよう書いたつもりですが、試してはいません。
インストールを工夫して、ソースコードを変更すれば、Windowsでも動くと思いますが、たぶんやらない・・・、かな?
それでは、いっていみましょう。
環境の準備
- Intel Arcの場合
- Radeonの場合
- ROCmのインストール(この記事の「ROCmのインストール」を参照。ただし、ROCmが動作するRadeonは現在RDNA2以上(VEGAは?)だと思います)。
- ffmpegのインストール
GeForceの場合はわかりません。持ってないもので・・・。
インストールスクリプト
以下は、「Intel Arc用」です。Radeonの場合はpytorchの部分が違います。
その場合は「#pip install –pre torch torchvision –index-url https://download.pytorch.org/whl/nightly/rocm7.1」のコメントアウトをはずし、「pip install –pre torch torchvision torchaudio –index-url https://download.pytorch.org/whl/nightly/xpu」をコメントアウトしてください。
#!/bin/bash
#インストールに必要なライブラリ等をインストール
sudo apt update
sudo apt install git
sudo apt install curl
sudo apt install build-essential cmake
#sudo apt install ffmpeg #自前でビルドした場合はこの行はコメントアウトしてください。
# uvをcurlでインストール
curl -LsSf https://astral.sh/uv/install.sh | sh
source $HOME/.local/bin/env
mkdir -p $HOME/install/langtrans_llama/input
mkdir -p $HOME/install/langtrans_llama/models
cd ~/install/langtrans_llama
#uvでpython3.12環境を作る
uv venv --python 3.12 --seed
source .venv/bin/activate
uv pip install openai requests
#whisperをクローン
git clone https://github.com/openai/whisper.git
cd whisper
#Radeonの場合のpytorchのインストール
#pip install --pre torch torchvision --index-url https://download.pytorch.org/whl/nightly/rocm7.1
#torch.xpuのstable
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/xpu
#whisperのセットアップ
uv pip install -U pip setuptools
uv pip install .
cd ../
#準備とllama.cppのクローン
sudo apt install -y cmake g++ libcurlpp-dev
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
#CPU用ビルド(ggufの変換で使う)
mkdir build-cpu
cmake -B build-cpu
cmake --build build-cpu --config Release -j$(nproc)
#sycl用ビルド
source /opt/intel/oneapi/setvars.sh
cmake -B build-sycl -DGGML_SYCL=ON -DCMAKE_C_COMPILER=icx -DCMAKE_CXX_COMPILER=icpx
cmake --build build-sycl --config Release -j$(nproc)
#vulkanビルド
sudo apt install -y libvulkan-dev glslc
cmake -B build-vulkan -DGGML_VULKAN=ON
cmake --build build-vulkan --config Release -j$(nproc)
追記(2026/2/28)
python環境を3.12にすることで問題なく動作しましたので、torch.xpuをstableに変更しました。
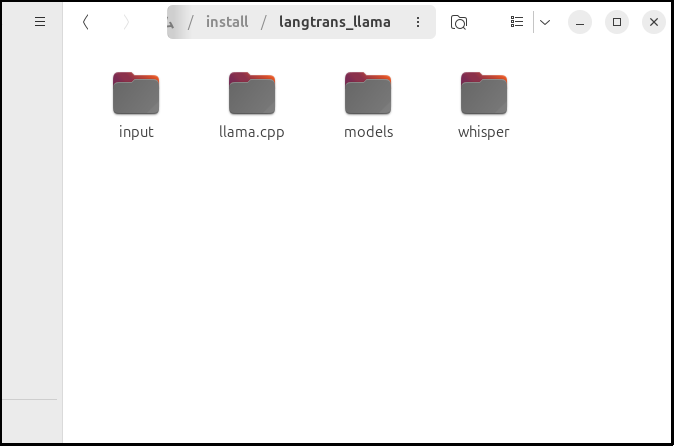
メインスクリプトの用意
以下のスクリプトを「langtrans_llama.py」として保存してください。
「gpt-oss-120b」がデフォルトになっていますので、20bが使いたい方は
# --- モデル設定 ---
#MODELS = "gpt-oss-120B-F16.gguf"
MODELS = "gpt-oss-20B-F16.gguf"上のように「#」を付け直して下さい。
import os
import sys
import subprocess
import time
import requests
import re
import torch
from openai import OpenAI
from pathlib import Path
# --- デバイス判定 ---
if hasattr(torch, "xpu") and torch.xpu.is_available():
DEVICE = "xpu"
W_DEVICE = "xpu"
BACKEND = "vulkan" # Arc GPU用
elif torch.cuda.is_available():
DEVICE = "cuda"
W_DEVICE = "cuda"
BACKEND = "vulkan"
else:
DEVICE = "cpu"
BACKEND = "cpu"
# ==========================================
# 設定変数(環境に合わせて調整してください)
# ==========================================
# --- 翻訳設定 ---
LANGUAGE = "日本語" #デフォルトは「日本語」です
BATCH_SIZE = 10 # 一回にまとめてLLMに渡す字幕の数。あまり多くすると翻訳ミスが多発します。
LIMIT = None # None に設定すると全件処理(デバッグ用)
MODEL = "local-model"
TEMPERATURE = 0.3
# --- whisperモデル ---
WHISPER_MODEL = "medium" #"tiny","base","small","medium","large","turbo"などから選んで下さい
#W_DEVICE = "cpu" # デバイス判定された値を上書きします
# --- 翻訳モデルの場所 ---
MODEL_PATH = Path("models") # 好きなモデルフォルダに指定できます
# --- モデル設定 ---
MODELS = "gpt-oss-120b-F16.gguf"
#MODELS = "gpt-oss-20b-F16.gguf"
# --- モデルの思考を可視化する ---
model_thinking = False # モデルの翻訳過程が見れるようになりますが、思考過程が字幕に混入するバグがあります。
# --- モデルの判別 ---
is_120b = "120b" in MODELS.lower()
# --- サーバー設定 ---
CONTEXT_LENGTH = 32784 #「0」だとVRAM空き容量分をほぼ全てコンテキスト長に当てます
PORT = 8080
BASE_URL = f"http://localhost:{PORT}/v1"
#--- CPU,GPUの割当変数を初期化 ---
CPU_MOE = None
N_GPU_LAYERS = None
#--- もし必要なら適当な数値を入れて下さい ---
# VRAMとメインメモリの割当が自動になったみたいなので変数自体オミットしています。
# どうしても割り当てたい時にコメントアウトを削除して下さい。
#CPU_MOE = 33 # 「0」に設定すると、全てのレイヤーをGPUに乗せます
#N_GPU_LAYERS = 99 # 学習モデルをいくつGPUレイヤーに乗せるかの設定値
#===========================================
# 以下はスクリプト本体です
#===========================================
full_path = MODEL_PATH / MODELS
# ファイルを取得
extensions = {".mp4", ".mkv", ".avi"}
FILE = next((p for p in Path("./input").iterdir() if p.suffix.lower() in extensions), None)
if FILE:
print(f"「{FILE.name}」が見つかりました。")
else:
print("inputフォルダの中に動画ファイルが見つかりません。")
sys.exit(1)
# パスの取得
temp_dir = Path(FILE.stem + "_temp")
temp_dir.mkdir(exist_ok=True)
audio_path = temp_dir / Path(FILE.stem + ".wav")
input_srt = temp_dir / Path(FILE.stem + ".srt")
translated_srt = temp_dir / Path(FILE.stem + "_translated.srt")
#===========================================
SERVER_BIN = f"./llama.cpp/build-{BACKEND}/bin/llama-server"
print(f"使用するバックエンド: {BACKEND}")
#===========================================
# 1. 動画から音声を抜き出す処理
def process_video(video_path):
print("--- 音声を抽出中 ---")
subprocess.run(["ffmpeg", "-y", "-i", str(video_path), "-vn", "-ac", "1", "-ar", "16000", str(audio_path), "-loglevel", "error"], check=True)
# 2. 音声からwhisperで文字起こしする処理(元のロジックに復元)
def run_whisper(audio_path, temp_dir):
print(f"--- Whisperで文字起こし中({W_DEVICE}) ---")
if W_DEVICE == "xpu":
subprocess.run([
"whisper", str(audio_path),
"--model", WHISPER_MODEL,
"--output_dir", str(temp_dir),
"--output_format", "srt",
"--device", "xpu"
], check=True)
else:
subprocess.run([
"whisper", str(audio_path),
"--model", WHISPER_MODEL,
"--output_dir", str(temp_dir),
"--output_format", "srt"
], check=True)
# 3. llama-serverの起動
def start_llama_server():
"""llama-serverを起動し、準備ができるまで待機する"""
if DEVICE == "cpu":
cmd = [
SERVER_BIN,
"-m", str(full_path),
"--port", str(PORT),
]
else:
cmd = [
SERVER_BIN,
"-m", str(full_path),
"--port", str(PORT),
"-c", str(CONTEXT_LENGTH),
]
if not CPU_MOE is None:
cmd.extend([
"--n-cpu-moe", str(CPU_MOE)
])
if not N_GPU_LAYERS is None:
cmd.extend([
"-ngl", str(N_GPU_LAYERS)
])
if model_thinking:
cmd.extend([
"--chat-template",
"chatml"
])
print(f"llama-server を起動中: {' '.join(cmd)}")
process = subprocess.Popen(cmd, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
#process = subprocess.Popen(cmd, stdout=None, stderr=None)
print("サーバーの準備完了を待っています...", end="", flush=True)
max_retries = 90
for i in range(max_retries):
try:
response = requests.get(f"http://localhost:{PORT}/health", timeout=5)
if response.status_code == 200:
print("\nサーバー準備完了!")
return process
except requests.exceptions.ConnectionError:
pass
print(".", end="", flush=True)
time.sleep(1)
process.terminate()
raise TimeoutError("\nサーバーの起動がタイムアウトしました。")
# 4. LLMによる翻訳処理
def translate_batch(client, batch_data):
"""思考プロセスを表示しつつ翻訳する(テキストのみ渡し版)"""
if is_120b:
print(f"120B用のプロンプトを使います。")
system_prompt = (
f"あなたはプロの映像翻訳家です。提供されたテキストを英語から{LANGUAGE}に翻訳してください。\n"
"【厳守事項】\n"
"1. 各行の先頭にある「インデックス番号:」の形式を絶対に変更しないでください。\n"
"2. タイムスタンプや矢印(-->)は絶対に出力しないでください。\n"
"3. 翻訳結果のみを出力し、余計な解説や挨拶は省いてください。\n"
"出力例:\n"
"1: こんにちは\n"
"2: お元気ですか"
)
else:
print(f"20B用のテストプロンプトを使います。")
system_prompt = (
f"あなたはプロの映像翻訳家です。提供されたテキストを英語から{LANGUAGE}に翻訳してください。\n"
"【厳守事項】\n"
f" 渡された{BATCH_SIZE}行のテキストは適切に翻訳し、必ず{BATCH_SIZE}行の翻訳文になるように適切に分割して出力してください。\n"
f" 翻訳が終わったら、渡された{BATCH_SIZE}行のテキストと、翻訳された{BATCH_SIZE}行のテキストを見比べて下さい。整合が取れないようならやり直してください。\n"
"1. 各行の先頭にある「インデックス番号:」の形式を絶対に変更しないでください。\n"
"2. タイムスタンプや矢印(-->)は絶対に出力しないでください。\n"
"3. 翻訳結果のみを出力し、余計な解説や挨拶は省いてください。\n"
"出力例:\n"
"1: こんにちは\n"
"2: お元気ですか"
)
prompt_content = "\n".join([f"{d['index']}: {d['text']}" for d in batch_data])
try:
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt_content}
],
temperature=TEMPERATURE,
stream=True
)
full_content = ""
print("\n--- 思考・翻訳中 ---")
for chunk in response:
content = chunk.choices[0].delta.content
if content:
print(content, end="", flush=True)
full_content += content
print("\n-------------------\n")
# <think>タグの中身を除去(改行も考慮)
clean_content = re.sub(r'<think>.*?</think>', '', full_content, flags=re.DOTALL).strip()
return clean_content
except Exception as e:
print(f" [!] エラー: {e}")
return None
def input_srt_translate(input_srt, translated_srt):
if not os.path.exists(input_srt):
print("エラー: 字幕ファイルが見つかりません。")
return
client = OpenAI(base_url=BASE_URL, api_key="sk-no-key-required")
with open(input_srt, 'r', encoding='utf-8') as f:
content = f.read()
raw_blocks = [b.strip() for b in re.split(r'\n\s*\n', content.strip()) if b.strip()]
parsed_data = []
for block in raw_blocks:
lines = block.split('\n')
if len(lines) >= 3:
idx = lines[0].strip()
timestamp = lines[1].strip()
text = " ".join([l.strip() for l in lines[2:]])
parsed_data.append({"index": idx, "timestamp": timestamp, "text": text})
if not parsed_data:
print("エラー: 有効な字幕データがありません。")
return
detected_limit = int(parsed_data[-1]["index"])
final_limit = LIMIT if LIMIT is not None else detected_limit
print(f"--- 翻訳開始 ({LANGUAGE}) ---")
target_data = [d for d in parsed_data if int(d["index"]) <= final_limit]
translated_srt_blocks = []
for i in range(0, len(target_data), BATCH_SIZE):
batch = target_data[i : i + BATCH_SIZE]
current_range = f"{i+1}~{min(i + BATCH_SIZE, len(target_data))}"
print(f"[{current_range} / {len(target_data)}] 処理中...")
result_text = translate_batch(client, batch)
translated_dict = {}
if result_text:
#matches = re.findall(r'^(\d+)[::]\s*(.*)', result_text, flags=re.MULTILINE)
matches = re.findall(r'^(\d+)[::]\s*([\s\S]*?)(?=^\d+[::]|\Z)', result_text, flags=re.MULTILINE)
for match_idx, match_text in matches:
translated_dict[match_idx] = match_text.strip()
for item in batch:
idx = item["index"]
timestamp = item["timestamp"]
trans_text = translated_dict.get(idx, item["text"])
srt_block = f"{idx}\n{timestamp}\n{trans_text}"
translated_srt_blocks.append(srt_block)
with open(translated_srt, 'w', encoding='utf-8') as f:
f.write("\n\n".join(translated_srt_blocks) + "\n")
print("--- 完了! 翻訳した字幕を出力しました ---")
# 5. 動画と字幕の結合
def Combining_srt_an_video(video_path, srt_path, server_process, temp_dir):
try:
output_path = Path(f"{temp_dir}") / f"{Path(video_path).stem}_subtitled.mp4"
print(f"--- 字幕と動画を結合中 ---")
if LANGUAGE == "日本語":
lang_code, title = "jpn", "Japanese"
else:
lang_code, title = "xxx", "Translated"
cmd = [
"ffmpeg", "-y", "-fflags", "+genpts",
"-i", str(FILE),
"-i", str(srt_path),
"-c", "copy",
"-c:s", "mov_text",
"-map", "0:v",
"-map", "0:a",
"-map", "1:0",
"-metadata:s:s:0", f"language={lang_code}",
"-metadata:s:s:0", f"title={title}",
str(output_path),
"-loglevel", "error"
]
try:
subprocess.run(cmd, check=True)
print("--- 結合完了 ---")
except subprocess.CalledProcessError as e:
print(f"結合エラー: {e}")
finally:
if server_process:
print("\nサーバーを停止しています...")
server_process.terminate()
try:
server_process.wait(timeout=10)
except subprocess.TimeoutExpired:
print("応答がないため強制終了します...")
server_process.kill()
server_process.wait()
print("サーバーを正常に終了しました。")
if __name__ == "__main__":
if FILE:
# --- 追加:字幕ファイルが既に存在するかチェック ---
if input_srt.exists():
print(f"「{input_srt.name}」が既に存在するため、音声抽出とWhisperの処理をスキップします。")
else:
process_video(FILE)
run_whisper(audio_path, temp_dir)
# ------------------------------------------------
server_process = None
try:
server_process = start_llama_server()
input_srt_translate(input_srt, translated_srt)
Combining_srt_an_video(FILE, translated_srt, server_process, temp_dir)
except Exception as e:
print(f"予期せぬエラーが発生しました: {e}")
if server_process:
server_process.terminate()
追記(2026/2/28)
動画と音声と字幕ファイルの結合処理でエラーが発生することが多かったため、スクリプトを全体的に見直してもらいました(Geminiに)。
以前と比べ、エラーは発生しなくなったと思います。
あとは、whisperで文字起こしをするデバイスを選べるようにしました。
36行目の「W_DEVICE = “cpu” # デバイス判定された値を上書きします」のところです。
CPU処理にしたい場合など、「#」を削除してください。
追記(2026/3/14)
すでにwhisperで文字起こしが済んでいる場合、重複して文字起こししないように変更しました。
モデルファイルの格納場所を指定できるようにしました。
他のソフトと共有したい場合は利用して下さい。
モデルの思考過程を表示できるようにしました。
45行目の「model_thinking = False」をTrueに変更することで可視化できます。現状バグがあるのでお試し用です。
テスト用に「gpt-oss-20b」でも動作するようにしました。
専用のプロンプトで動かします。
まだ、誤訳が多いですがメモリの厳しい人は使ってみて下さい。
Intel Arcの動作バックエンドを「vulkan」に変更しました。
「llama.cpp」の「sycl」はデータ型「BF16」に完全対応していないようでしたので。
この変更に伴って、本文も少し書き換えています。
「CPU_MOE」と「N _GPU_LAYERS」の項目をオミットしました。
現状で自動でメモリを割り当ててくれるみたいです。
どうしても手動で割り当てたい方は、62行目あたりのコメントアウトを削除して下さい。
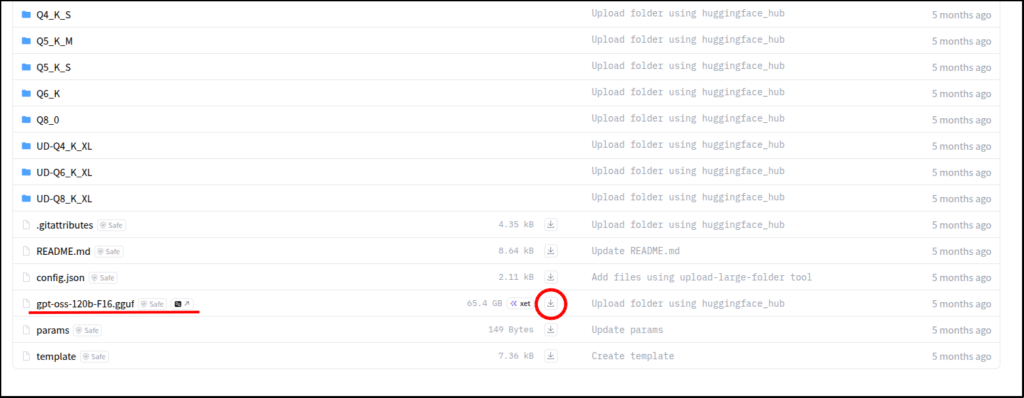
モデルファイル(gguf)準備
gpt-oss-20bです。
翻訳等速いんですが、たまにミスしたりします。
gpt-oss-120bは処理が遅く、PCに求められるスペックが高くなります。
代わりに翻訳も20bより自然で破綻が少ないです。

上のリンクから、ggufファイルをダウンロードしましょう。
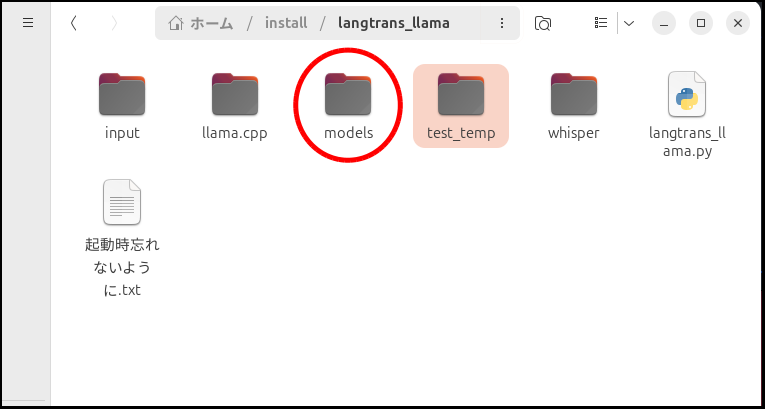
翻訳する動画を用意して実行
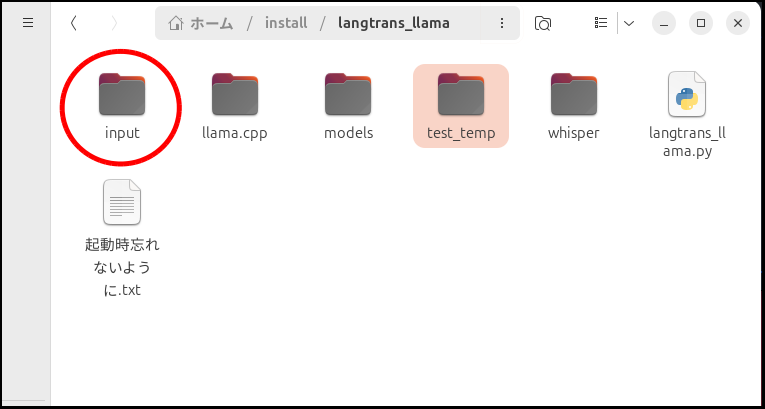
次に「langtrans_llama.py」を実行していくわけですが、まだgradio(GUI)に対応していません。
なので、細かい調整はソースコードをいじることになります。
設定が済んだらターミナルを起動して、
source .venv/bin/activate
python ./langtrans_llama.pyで起動すれば、あとは出来上がるまで待つだけです。
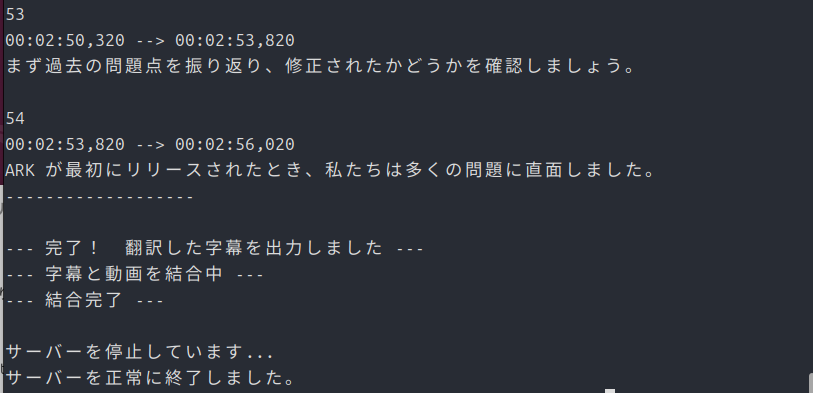
最後に
このスクリプトの実行内容は、今まで自分が手動でしていたことを全部自動で実行できるようにしたものです。
自分はわかって使っていますが、知らない人が使うとエラーが起こった時に対処できないかもしれません。
もし、llama-serverのあたりでうまく処理が繋がらないようなら、
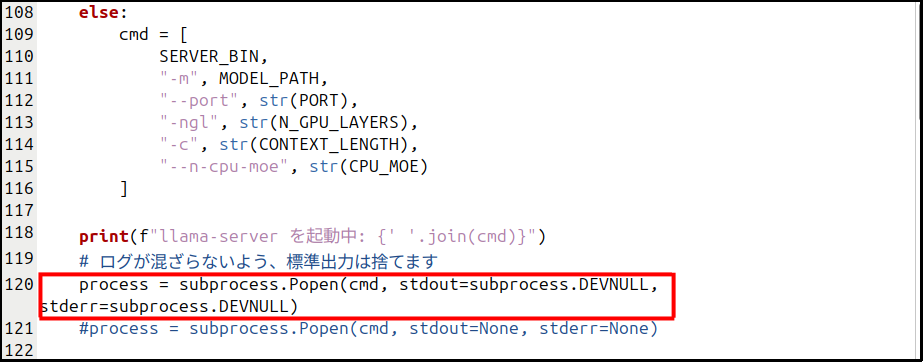
process = subprocess.Popen(cmd, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)この部分を
process = subprocess.Popen(cmd, stdout=None, stderr=None)に変更してください。
ターミナルにエラーなどのログが表示されるようになります。
もうひとつ
スクリプトを強制終了した時に、VRAMのモデル等開放できていない場合があります。
その場合は
pkill -f llama-serverを実行してください。VRAMが開放されると思います。
今回は以上です。
この記事を書いている現状では、Arc B580は以下のモデルくらいしか安いのは無さそうです。



コメント