Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。
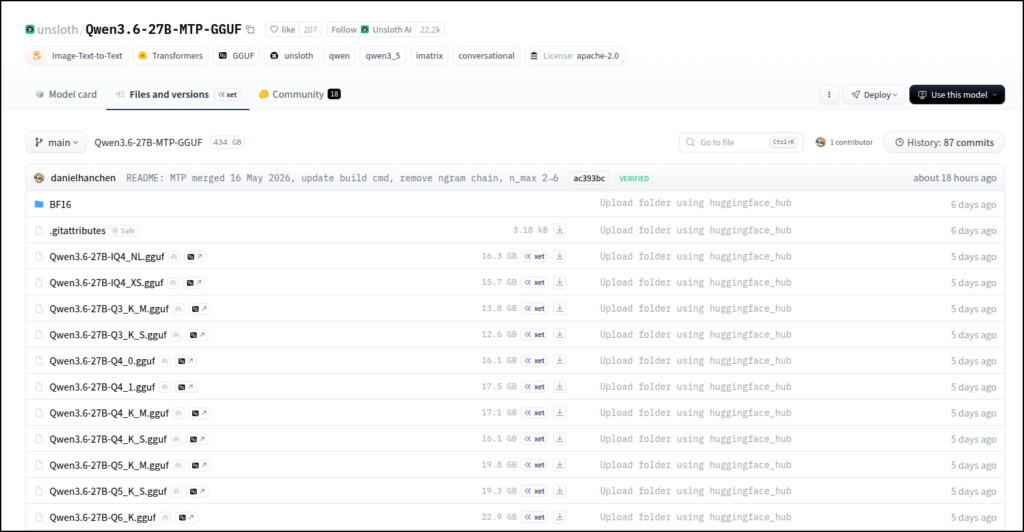
https://huggingface.co/unsloth/Qwen3.6-27B-MTP-GGUF
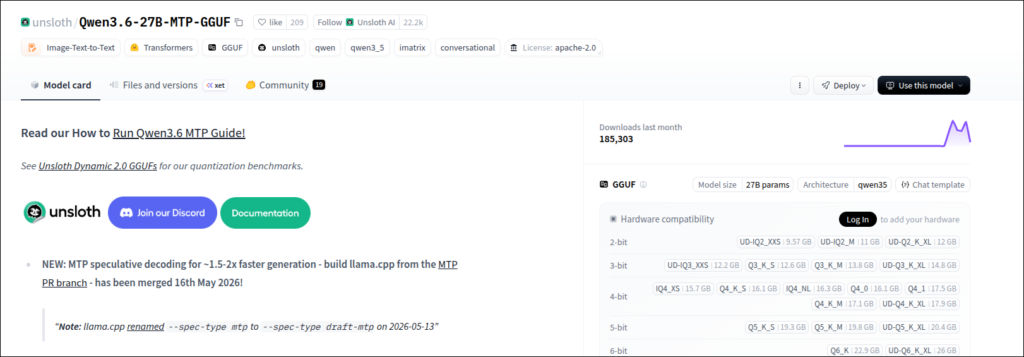
2026/5/16にllama.cppのフォーク版、「am17an/llama.cpp」の機能が、本家llama.cppにマージされたのだそうです。
最近話題のMTP(Multi-Token Prediction)です。
通常LLM推論は、1トークン生成するたびに、モデルデータとコンテキストをVRAMなどに全て転送してから行われるのだそうです。
生成にかかる時間はほんの僅かなのですが、このモデルとコンテキストを転送がボトルネックになるのだとか。
つまり、LLMはメモリ帯域幅が全て。
LLM推論速度シミュレータでなんとなくわかっていただけると思います。
MTPは生成されるトークンを予測して(デフォルトだと3トークン)生成し、的中していればその分だけ生成速度が稼げるというもの。
理屈は自分ではあまりよくわかっていないのでこのへんにしときますが、この機能がこの度「llama.cpp」に統合されました。
今までは「vLLM」みたいにsafetensorsのままでないと使えなかったのですが、ggufに変換できるようになったみたいですね。

自分もこの記事で書いているように、llma.cppをGUI化しているので、今回のMTPを組み込んでみました。
試してみましょうか。
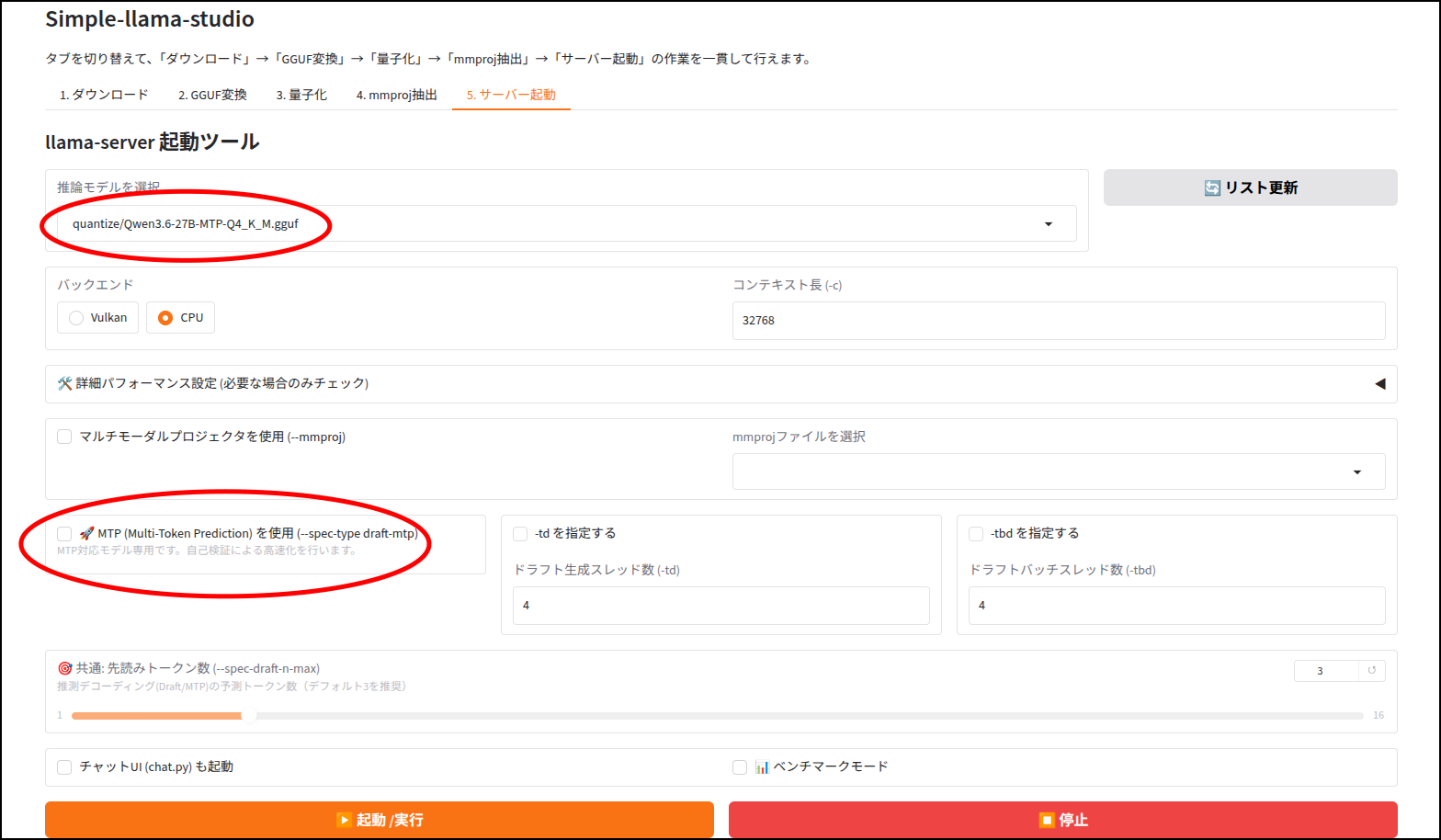
simple-llama-studio

今回の動作検証
「Qwen3.6-27B-UD-Q4_K_XL.gguf」で動作検証しています。
(ほかのモデルと区別がつかなくなるので、Qwen3.6-27B-MTP-Q4_K_XL.ggufにリネームしています)
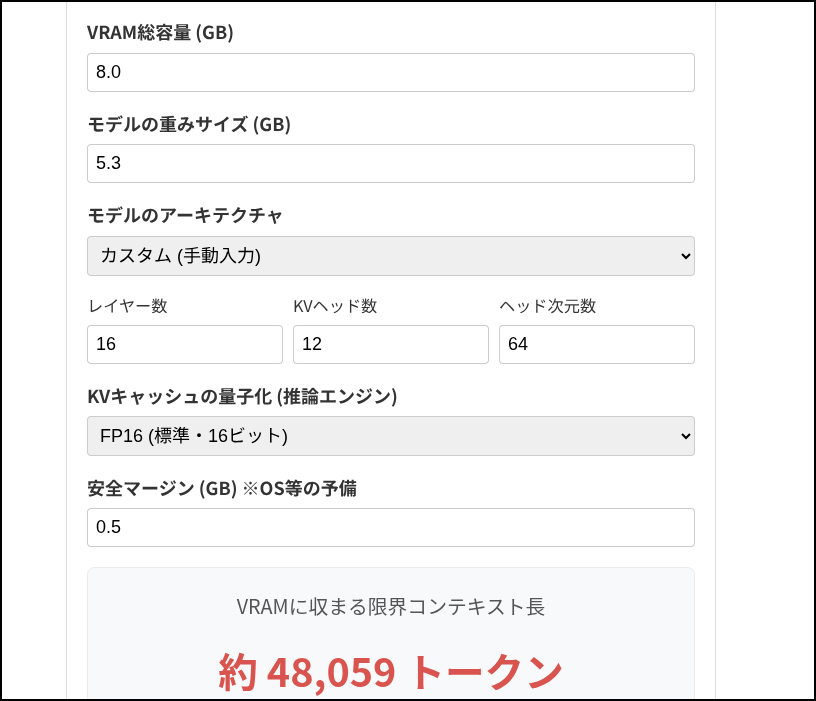
ただ、このMTPはVRAMにすべて収めなければ速度が激減します。
詳しくはこちらのPDFをどうぞ。
GeminiのDeepResarchという機能で調査してもらいました。
正しいかはわかりませんが、今回の検証にはおおいに役に立ちました。
というわけで今回はCPUにて動作検証しています。
Intel Arc A750のVRAMではとても収まりません。
もし、強力なGPUをお持ちの方は是非テストしてみてください。
変化したところ
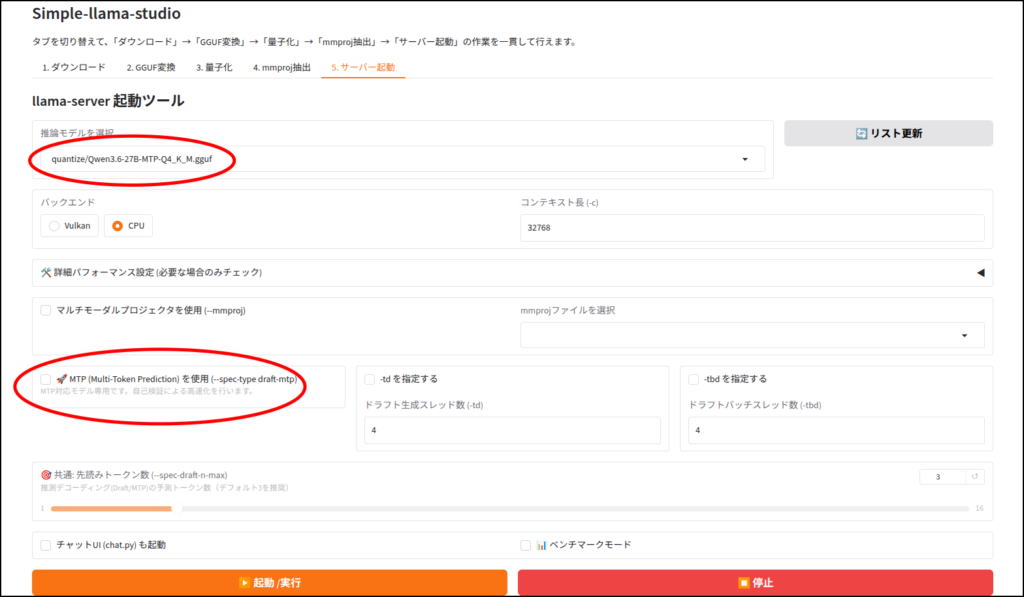
いろいろ調整できるようにしましたが、たぶんそのままチェックを入れるだけで効果はあると思います。と、いうか自分の環境では効果はありました。
ブラウザで動くテトリスを作ってもらう
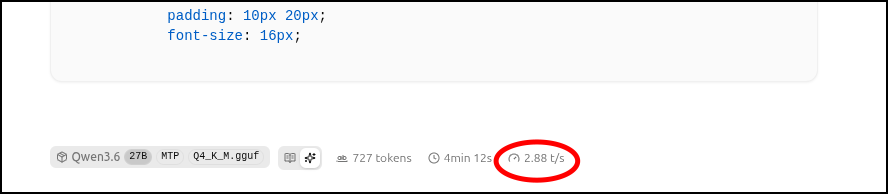
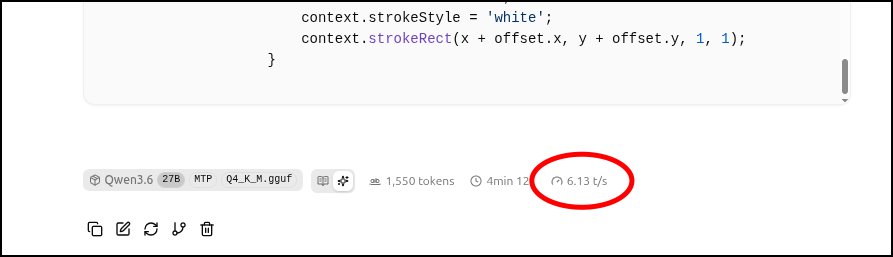
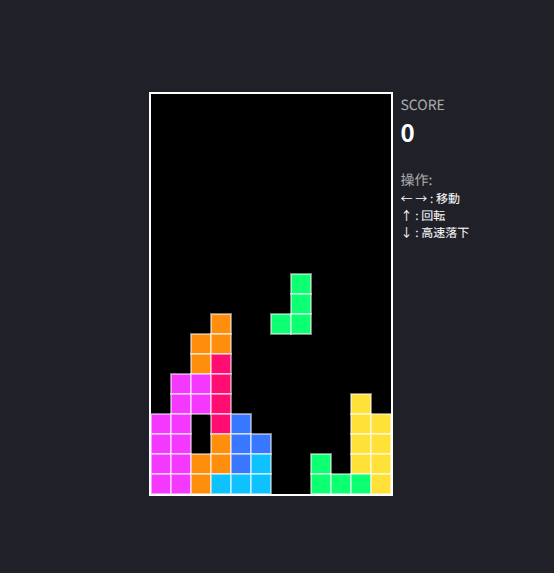
CPU環境なので、速くなったといっても焼け石に水といったところ。
VRAMがたくさんある人は、ぜひvulkanで動作させてみてください。
CPUで動作させるなら
CPUで動かす人はあまりいないと思いますが、もし動かすならコツとしてスレッド数をたくさん割り当てないこと。
物理コアの「半分〜3/4」くらいにしといた方がいいです。
このあたりの説明も、上のPDFに書かれています。
今回は以上です。
追記
ちなみに生成速度が速くなるのは、コード生成みたいな予測のしやすい場合に限ります。
自然言語での会話はむしろ遅くなることも・・・。
あと、自分の環境では「Qwen3.6-35B-A3B-MTP-GGUF」のようなMoEの場合は14[tokens/sec]が17[tokens/sec]くらいにしかなりませんでした。
27BのようなDenseモデルの場合、メインメモリ転送に時間がかかりすぎてCPUの処理に余裕がある分、予測に使う計算リソースがあるからかなぁと勝手に解釈しています。



もし、メインメモリが大量にあるって人は8700Gもおもしろいかも。
PDFを見て欲しいんですが、MTPを内蔵GPUで扱う場合は注意点があるみたいです。

以下は自分が使っているCPUですが・・・。
今はコスパが悪いのでオススメはできないです。
LLM推論なら、モデル次第ではまぁ我慢できる?

コメント