Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。
最近、AIをエージェントとして使役することに試行錯誤しています。
そんな中、出来上がったのがこのツール。
言ってみればただの副産物です。
llama.cppといえば、黒い画面に白い文字でコマンドを打ち込んでいくものです。
コマンドをいつもコピペしている自分にとっては、やっぱり煩わしい。
自動処理させるにはとても便利なんですがね・・・。
ということで、gradioを使ってGUI化してみました。
それでは、いってみましょう。
ダウンロード
例によってリポジトリを作りました。
uv環境を使っています。
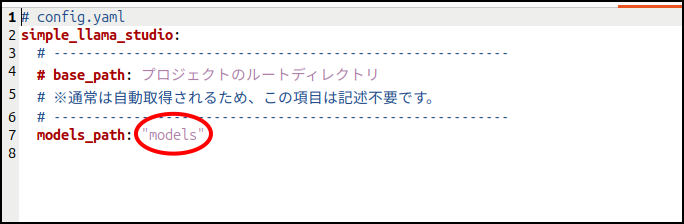
インストールの手順はこちらをどうぞ。
それでは、simple-llama-studioをインストールしていきましょう。
#!/bin/bash
sudo apt install git
cd ~
mkdir -p install
cd install
# simple-llama-studioをダウンロード
git clone https://github.com/toaru-ubuntu/simple-llama-studio.git
cd simple-llama-studio
# uv環境を作ります
uv venv .venv --python 3.12
source .venv/bin/activate
# simple-llama-studioを動かすのに必要なライブラリ等
uv pip install huggingface_hub gradio pyyaml
# llama.cppのダウンロード
sudo apt install -y git cmake g++ libcurlpp-dev
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
# CPU用ビルド(ggufの変換で使う)
mkdir build-cpu
cmake -B build-cpu
cmake --build build-cpu --config Release -j$(nproc)
# vulkanビルド
sudo apt install -y libvulkan-dev glslc spirv-headers
cmake -B build-vulkan -DGGML_VULKAN=ON
cmake --build build-vulkan --config Release -j$(nproc)
# ggufの量子化に必要なライブラリ等
uv pip install -r ./requirements.txt --index-strategy unsafe-best-match以上でインストールは終了です。
ちなみにバックエンドはvulkanとCPU(CPUってバックエンドとは言わないかも・・・)です。
cudaは触ったこと無いですが相当速いらしいですね・・・。
でも、使える人が限定されてしまうので、自分としてはどのPCでも使える方が良いと思っています。
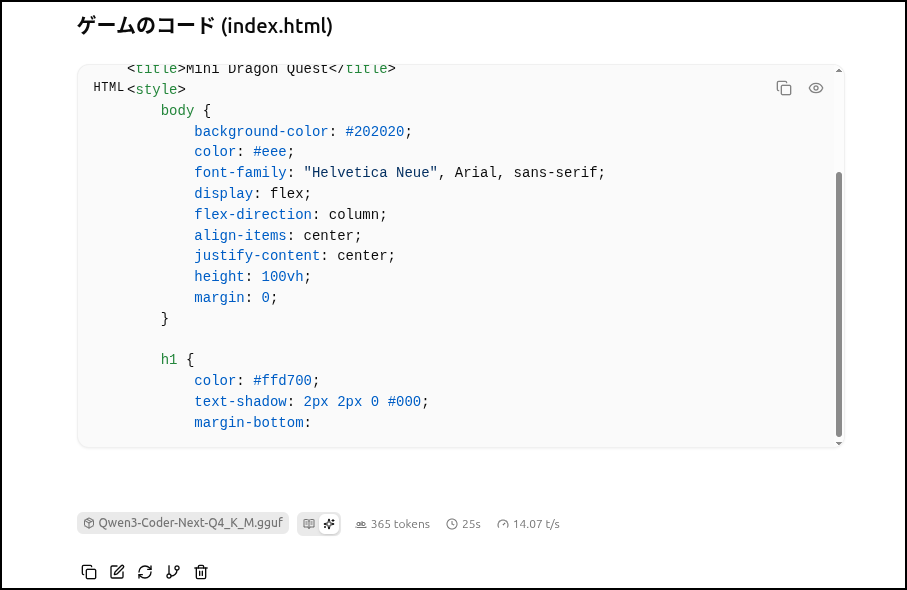
使い方
最近のLLMは高効率で容量も小さくなってきていますが、それでも50GBとかあります。
システムディスクに移動したりダウンロードしたりするとそれだけでかなり容量を圧迫します。
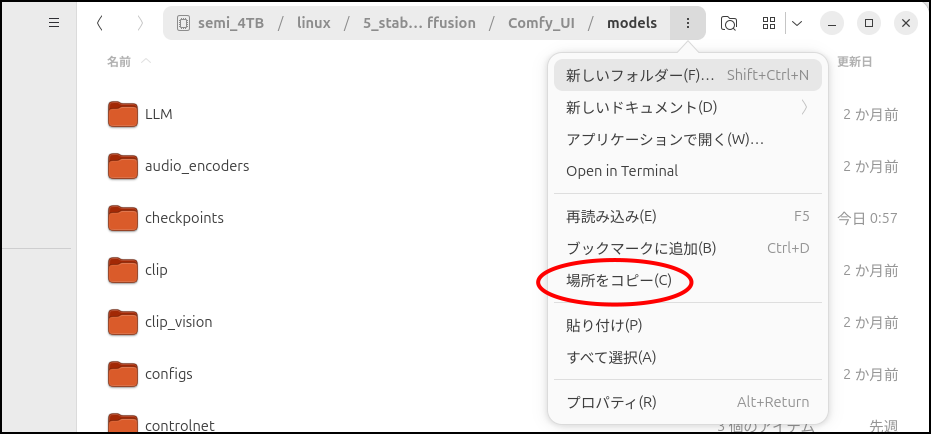
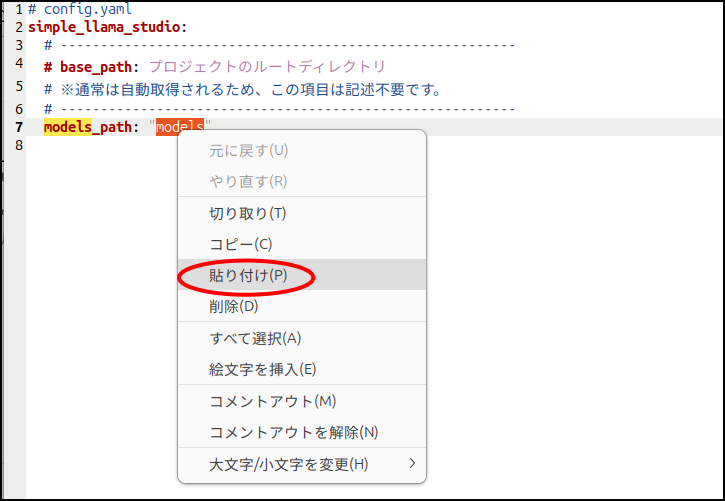
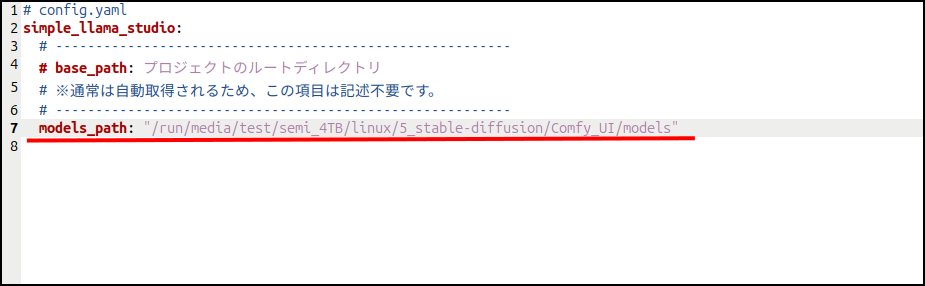
では、ここから使い方です。
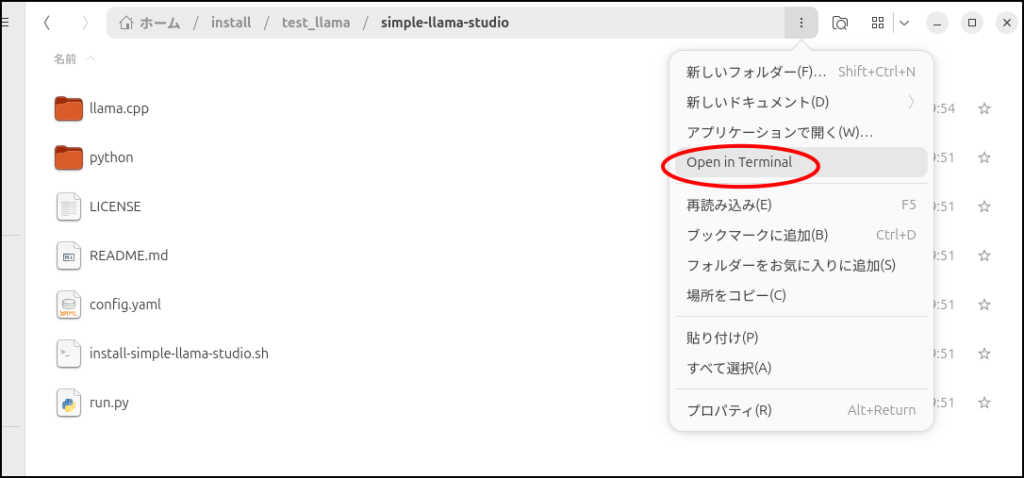
以下のコマンドでも大丈夫です。
source .venv/bin/activate
python ./run.py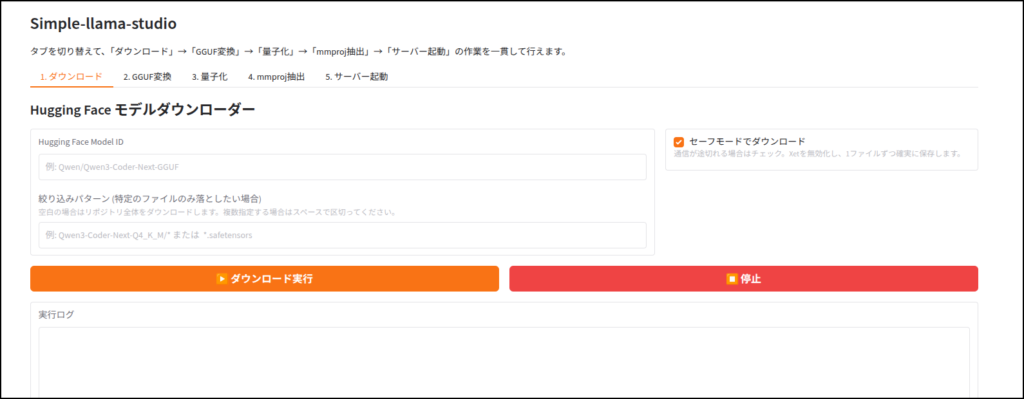
まずはLLMをダウンロードしなくてはなりません。
次はそこからの手順を説明します。
LLMのダウンロード
このツールはhuggingface IDを使ってLLMをダウンロードします。
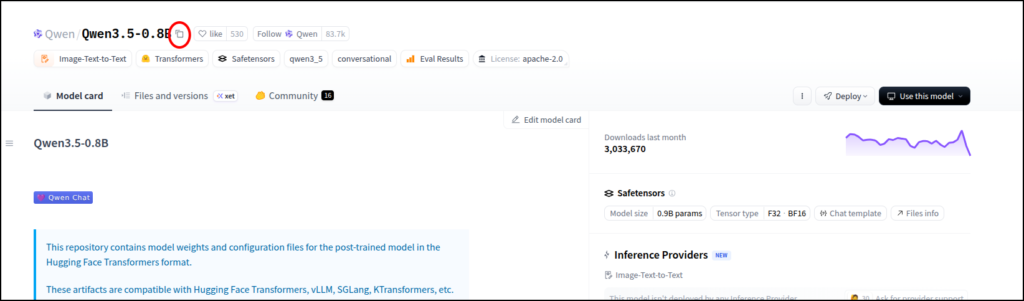
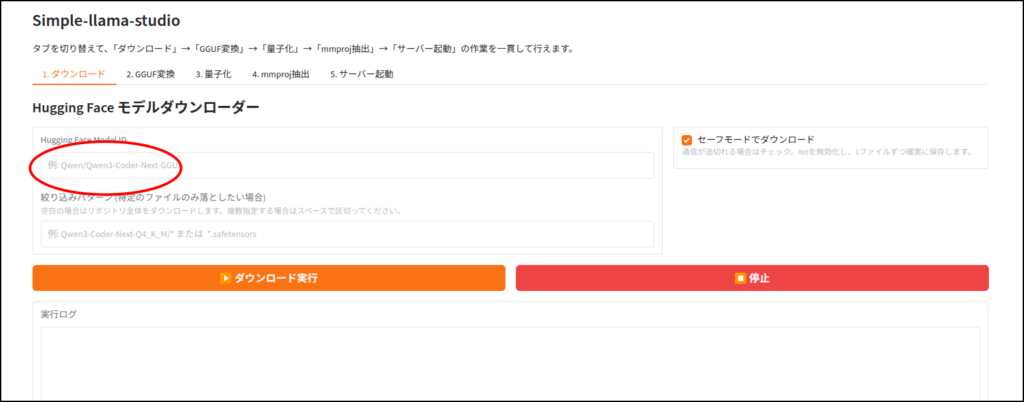
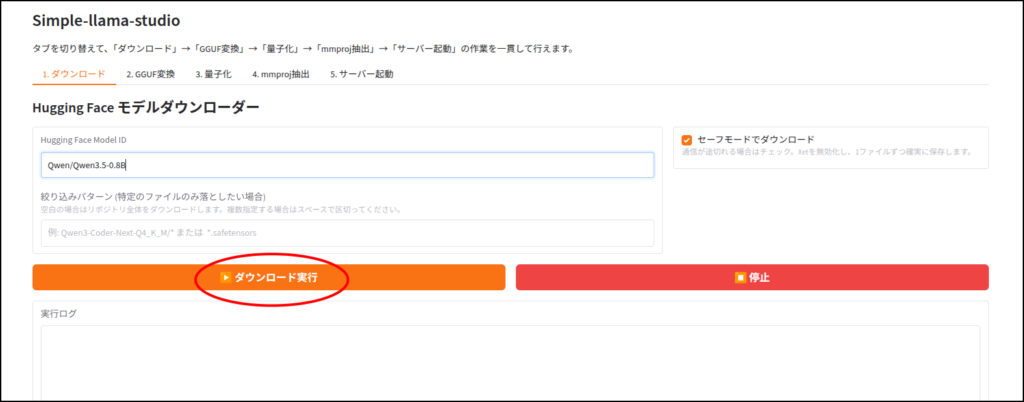
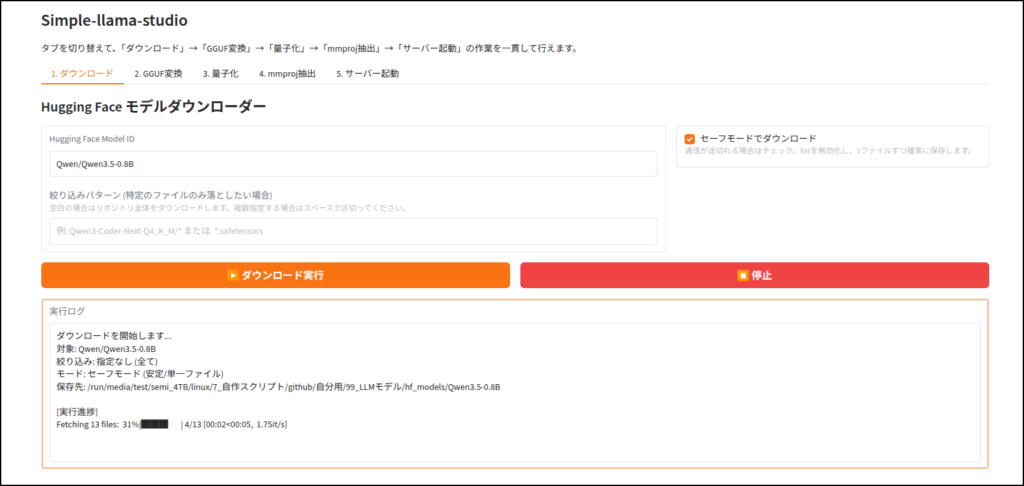
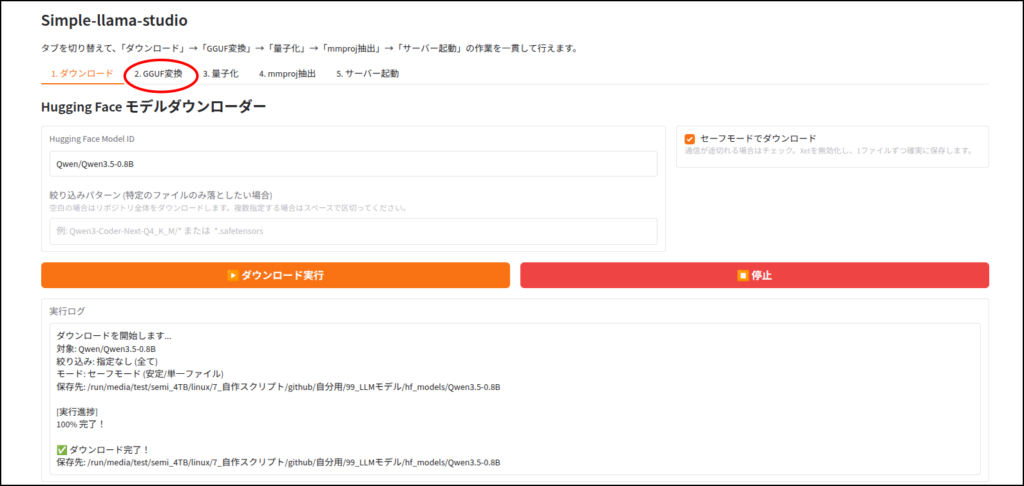
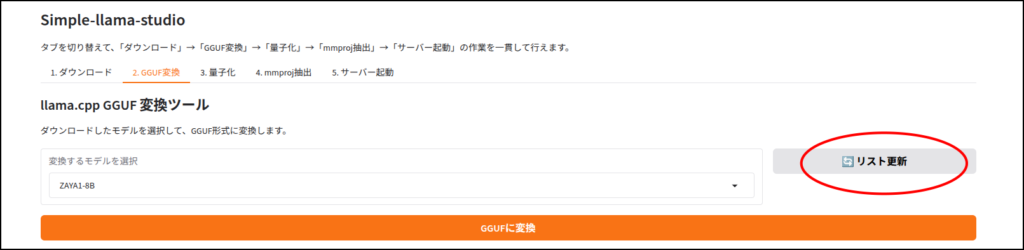
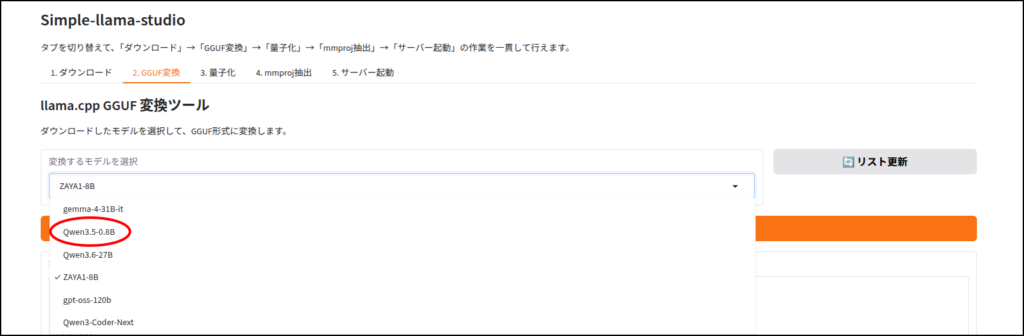
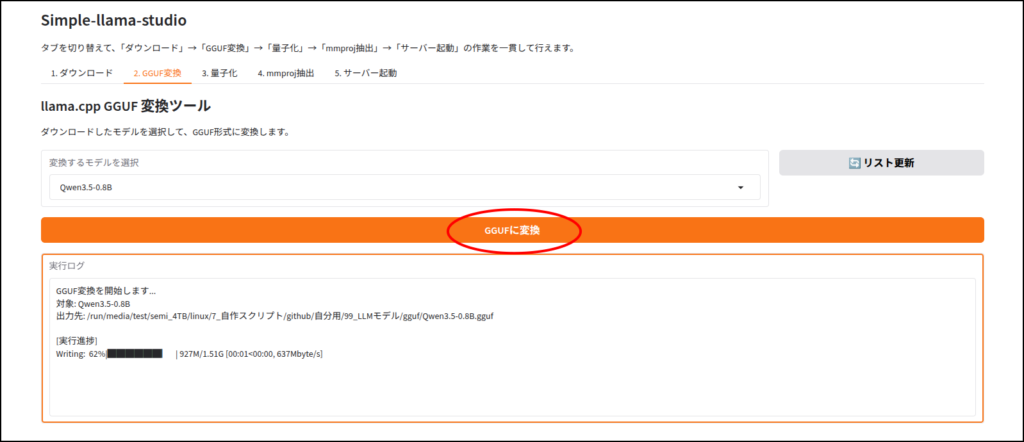
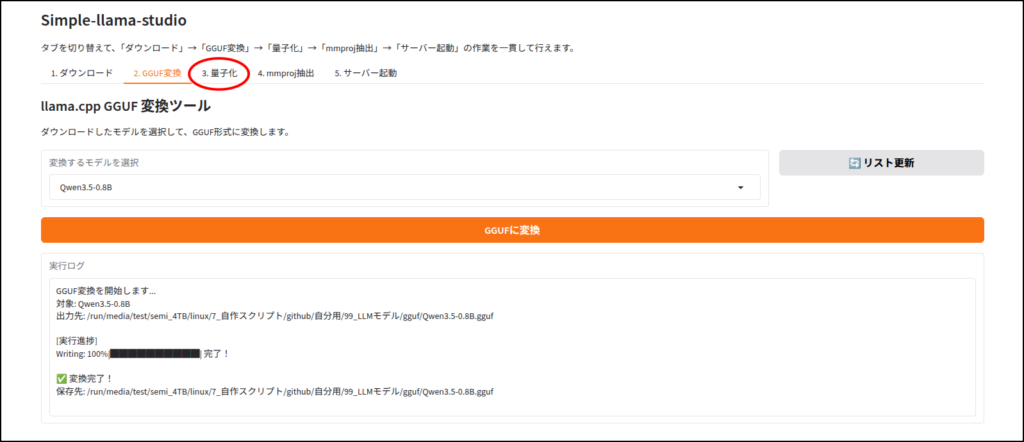
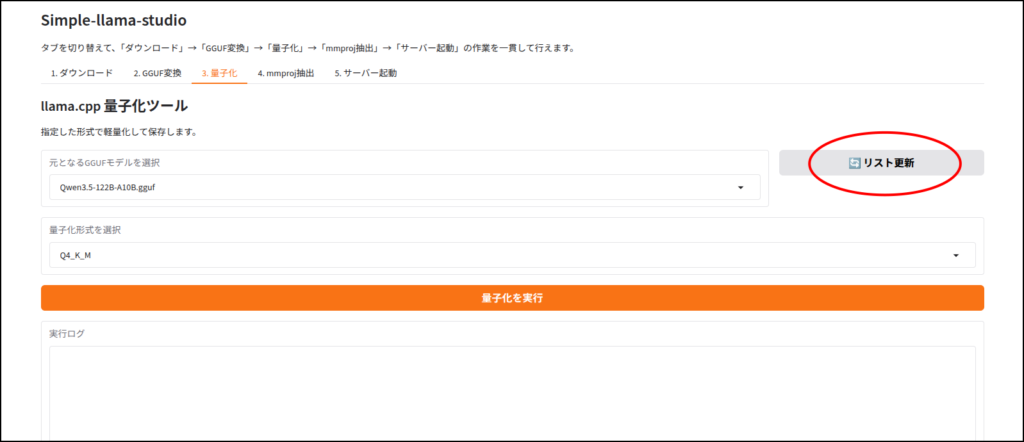
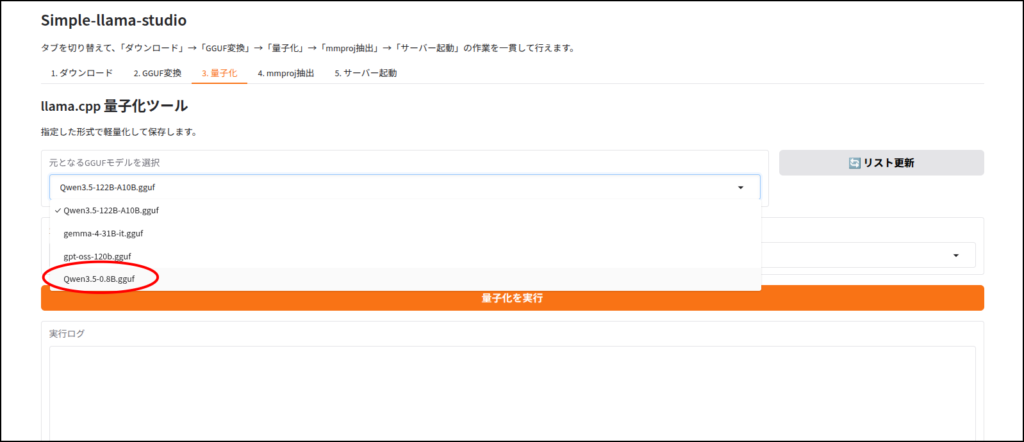
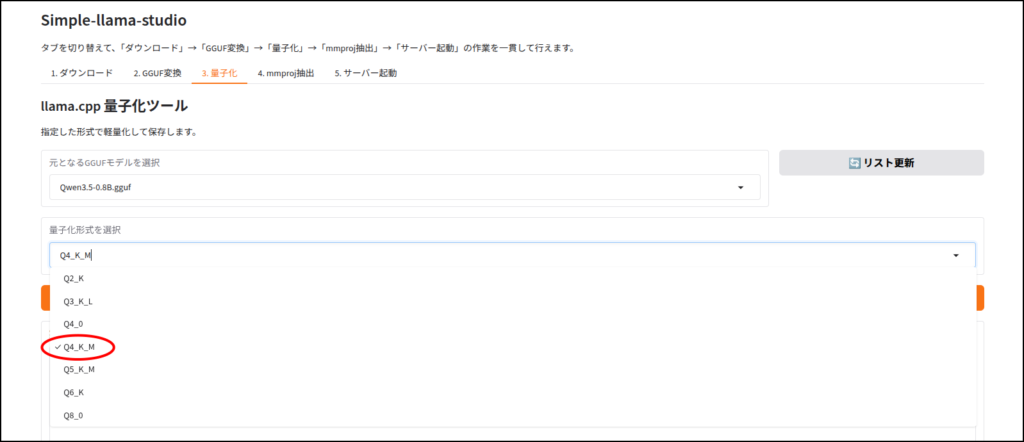
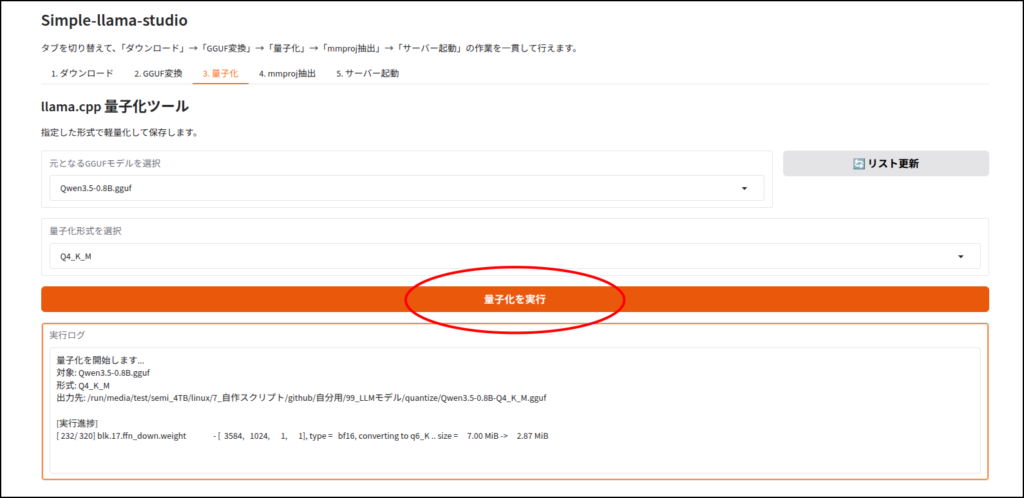
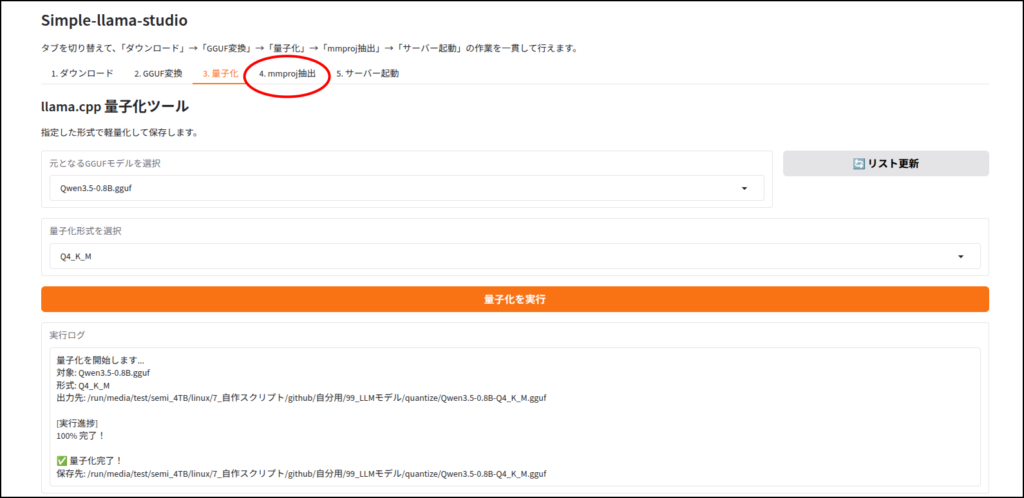
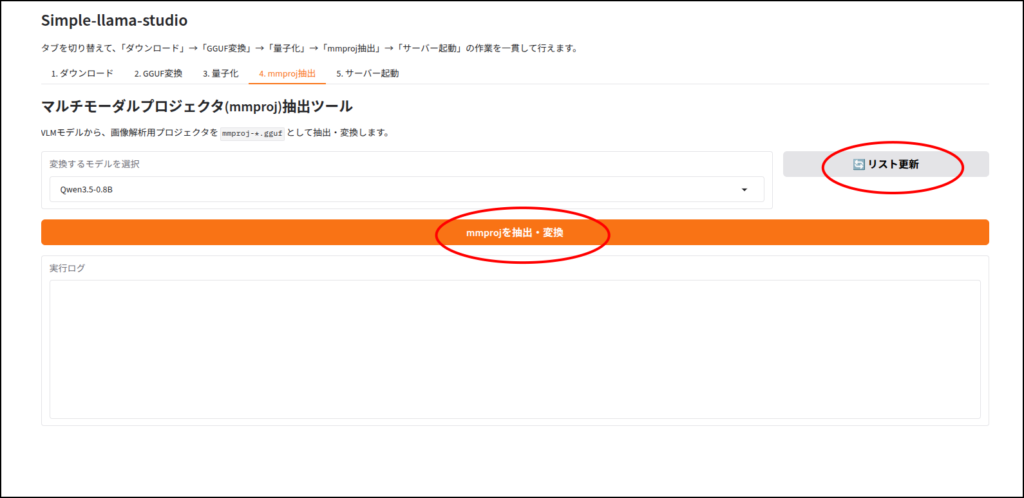
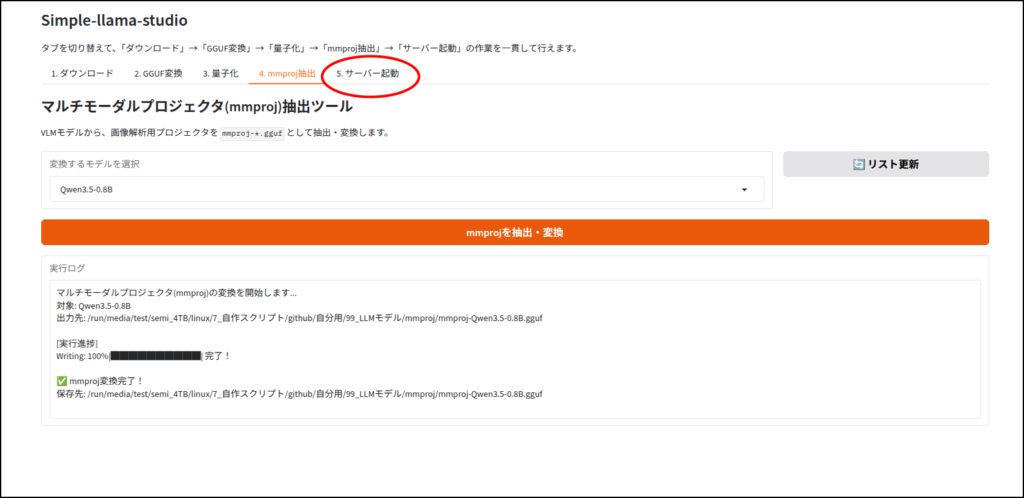
ちなみに画像認識など、マルチモーダルに対応していないLLMだと、この工程はエラーが出ると思います。
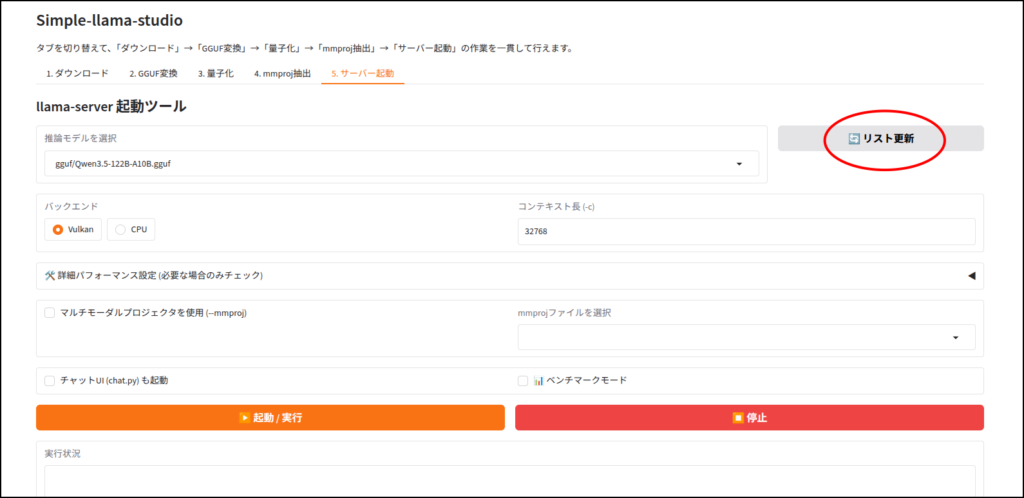
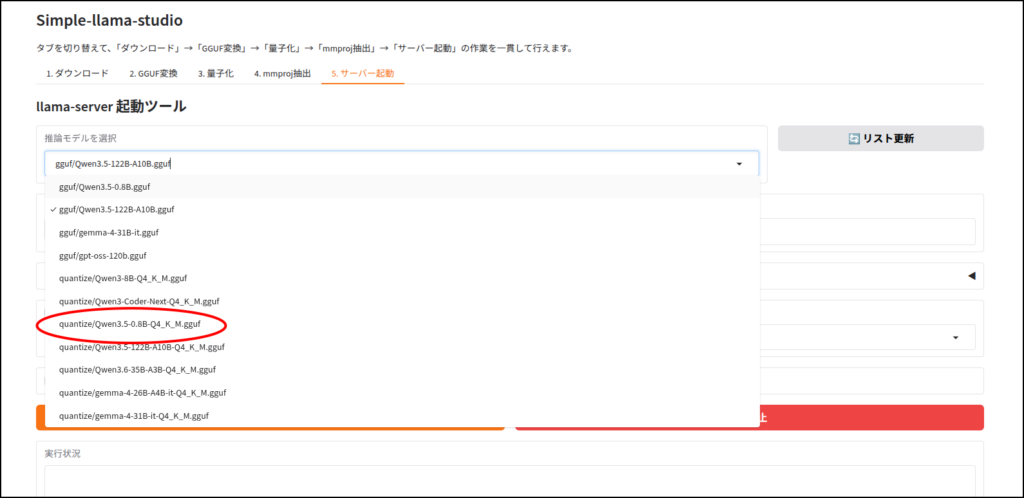

Vulkanは、ここ10年くらいのGPUならだいたい対応していると思います。
ちなみに自分はCPUで推論することがほとんどです。
Intel Arc A750はVRAMが8GBしかないもので・・・。
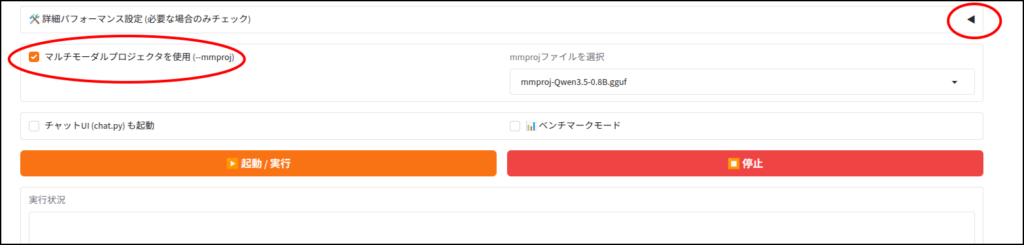
ちょっと見えにくいですが、右上の赤丸からパフォーマンス設定を開いていきます。
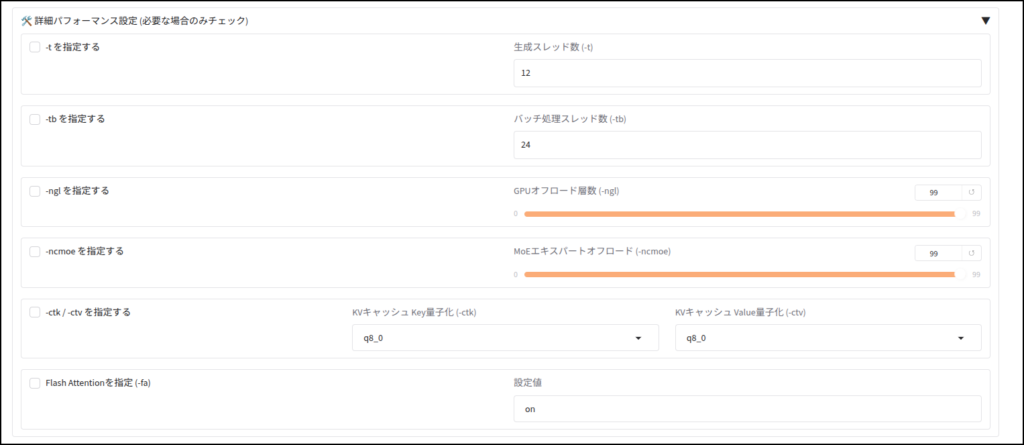
- 「-t」を指定する
- CPUで推論するスレッド(プロセス?)数を指定します。物理コア数を指定すると良いようです。私事で申し訳ないですが、Ryzen9 7900無印に合わせてます。
- 「-tb」を指定する
- ユーザーのコンテキストを読み込むスレッド(プロセス?)数を指定します。論理コア数でブン回す。設定数は同上。
- -ngl を指定する
- LLMはいくつものレイヤーに分かれているらしいのですが、その内GPUに何層乗せるかの設定数。VRAMの使用量とコンテキスト長で決めましょう。ちなみに自分は設定しません。
- -ncmoe を指定する
- MoEモデルの時に使うらしいのですが、VRAMに載せきれない分をCPU(メインメモリ)に肩代わりさせる層数らしいですが、よくわかりません。自分は使わないので。
- -ctk / -ctv を指定する
- トークンとか呼ばれるコンテキストの量子化らしい。
- 「k」がキー、「v」がバリュー。それぞれ量子化してメモリを圧迫するのを緩和できるみたいです。自分はここだけ「q8」とかに設定します。
- Flash Attentionを指定 (-fa)
- メモリ効率化のオプション。自分は指定しないです。しなければ「auto」が選ばれるとのこと。
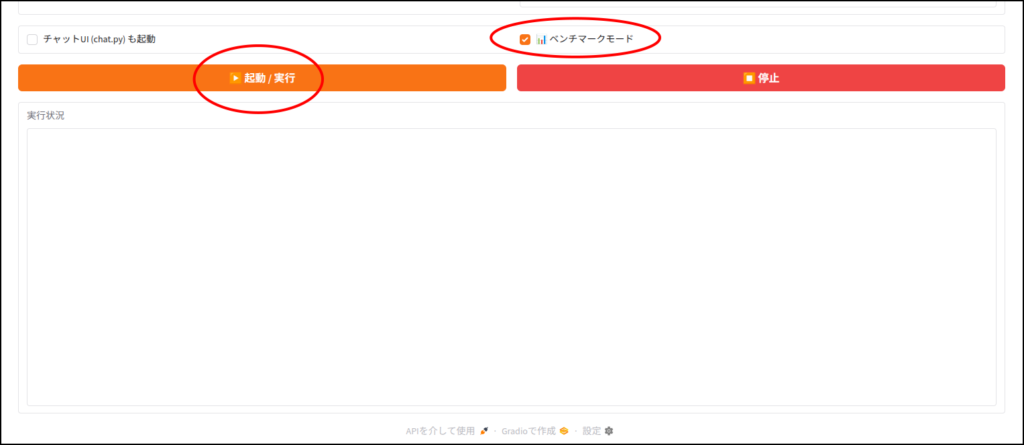
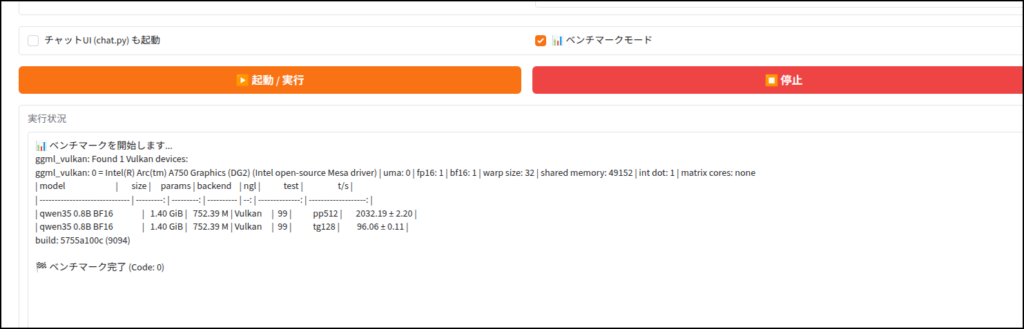
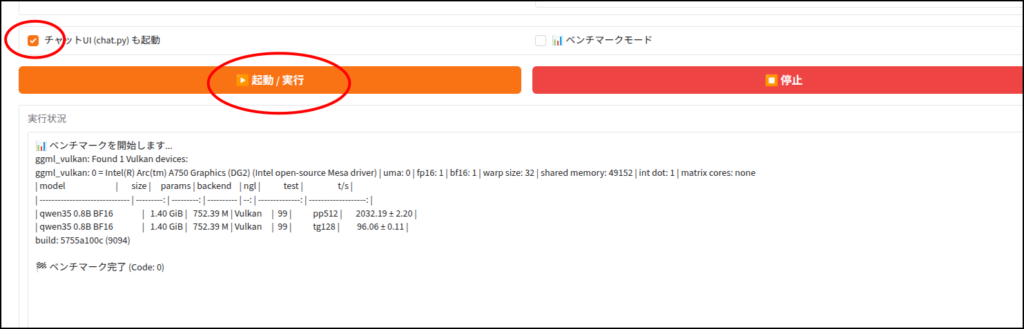
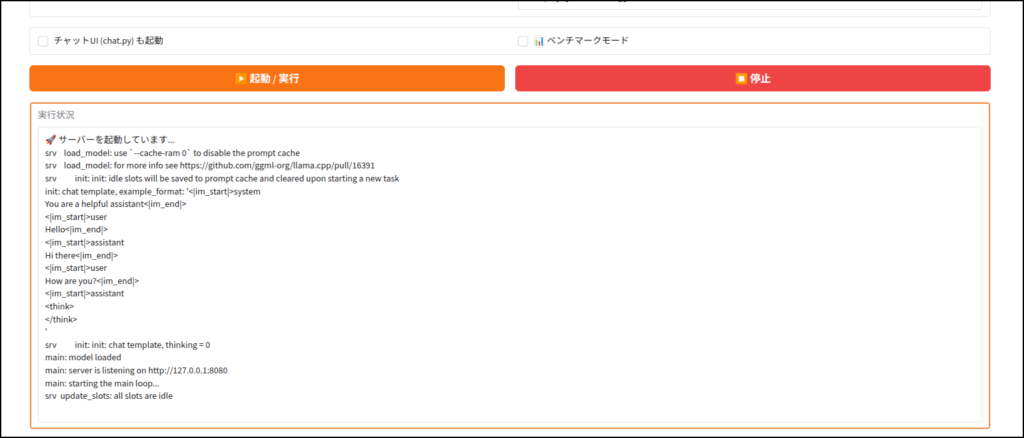
ちなみに「chat.py」と書かれていますが、Geminiの勘違いです。
llama.cpp専用の簡易UIが立ち上がります。
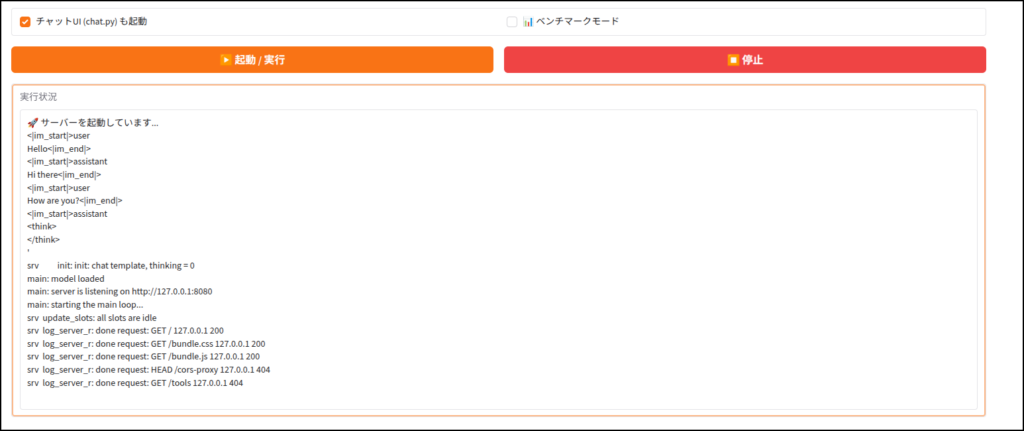
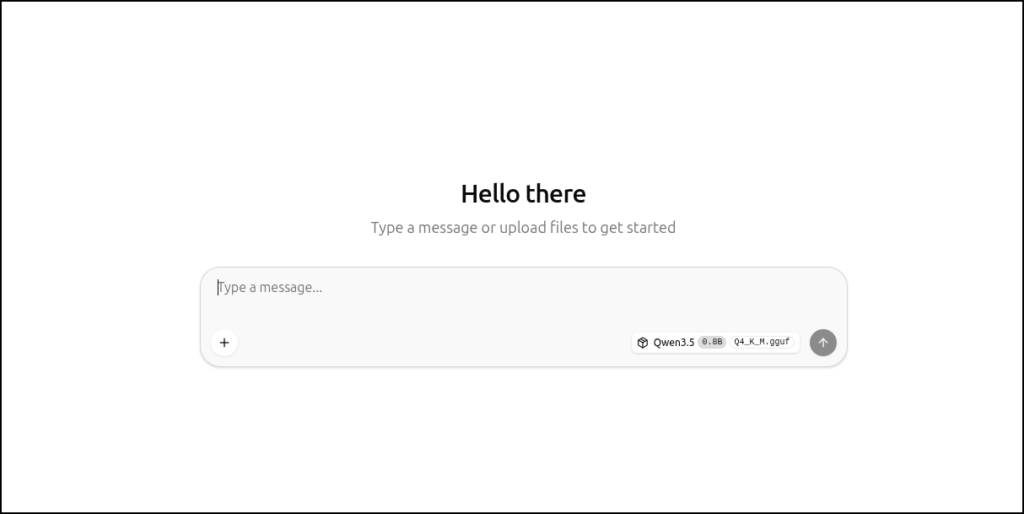
サーバーモード
自分はこのためにこのツールを作ったようなものです。
OpenAI APIとやらを使ってOpenManusやOpenClaw、Roo Codeなどと通信できます。
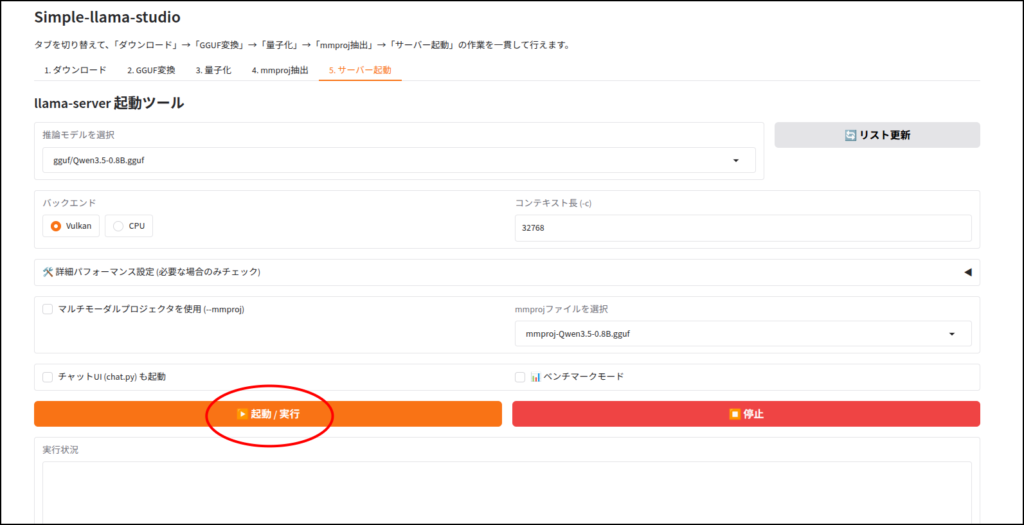
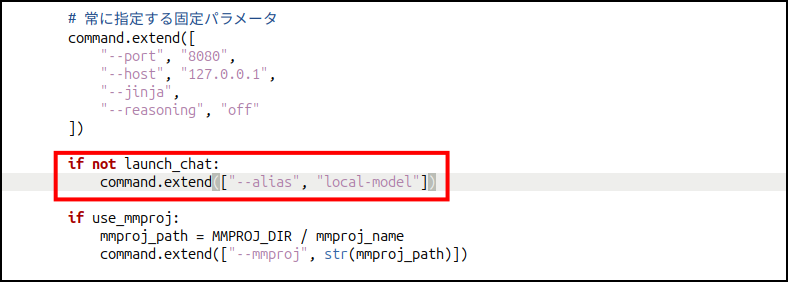
自分はAIエージェントを使う時、「llama.cpp」だけでなく「OpenVINO GenAI」も使うことがあるので、設定で迷わないように固定にしています。
このあたりの設定は似たようなものがたくさんあるので。
Geminiは「別になんでもいいですよ」って言うんですが・・・。
「Chatbox」や「SillyTavern」、「Dify」のような有名なチャットアプリなどでは設定画面で以下のように入力するとつながるようなるらしいです。
- APIのベースURL:
http://127.0.0.1:8080/v1 - APIキー: (何でもOK)
Pythonなどで自作のプログラムを組んだりする場合は
http://127.0.0.1:8080/v1/chat/completions でつながるようです。
といってもループしませんでした。
本当なら、足りないライブラリを自動でインストールしたり、エラーを自己修復したりします。
LLM次第といったところです。
最後に
Arc Pro B60を手放したのはかなりの痛手です(まぁ仕方がなかったのですが・・・)。
ついでにRadeon Pro W6800も・・・。
人間、失って初めてその価値に気づくものです。
逆に言えば、失うまでその価値には気づいていなかった、ということですね。
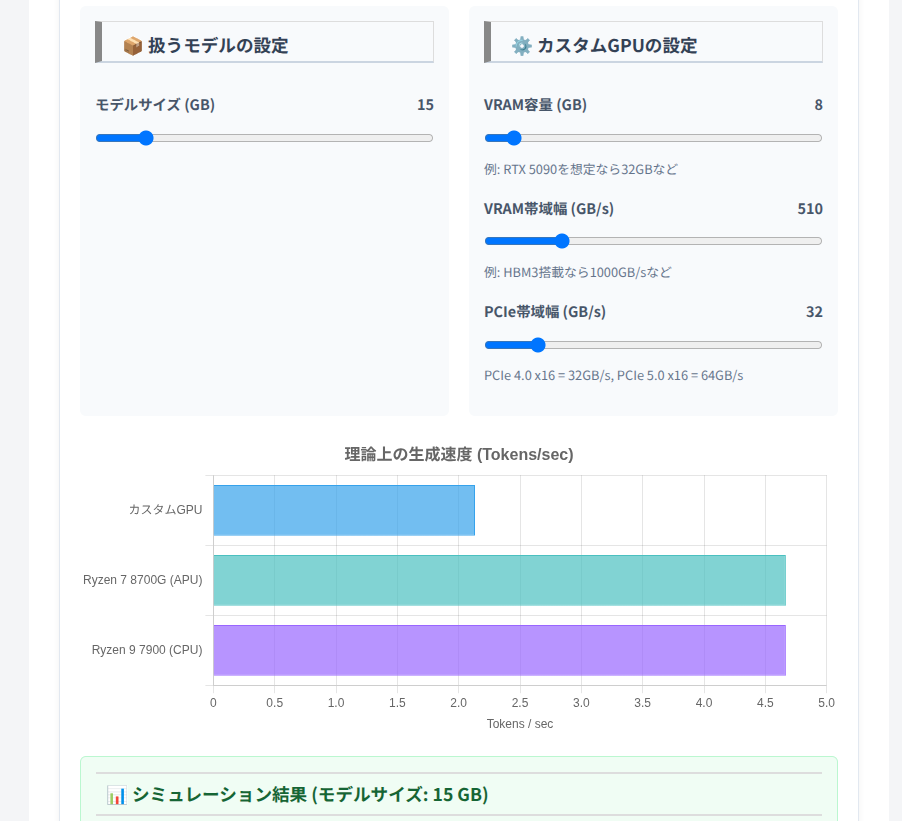
おかげでCPUが以外にも推論で役に立つということに気が付きました。
APUなんか結構良い選択肢かもしれません(メモリ次第ですが)。
「重み」と「活性化」の分かれているモデルに注目すれば、そこそこはいけます。
Denseモデルの方が推論性能が強いことは確かですが。
今回は以上です。



もし、メインメモリが大量にあるって人は8700Gもおもしろいかも。

以下は自分が使っているCPUですが・・・。
今はコスパが悪いのでオススメはできないです。
LLM推論なら、モデル次第ではまぁ我慢できる?

コメント