Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。
以前の記事でIrodori-TTSをROCmで動かしてみましたが、今回はIntel Arcで動かしてみます。
手順はおおむねROCm版と同じですが、「inference_runtime.py」だけソースを改変しなくてはなりません。
それではやっていきましょう。
環境を構築
今回も「uv」を使います。
「uv」についてはこちらで説明しています。
次にIrodori-TTSのクローン等やっていきます。
sudo apt update
sudo apt install cmake build-essential
git clone https://github.com/Aratako/Irodori-TTS.git
cd Irodori-TTS
uv venv --python /usr/bin/python3
source .venv/bin/activate
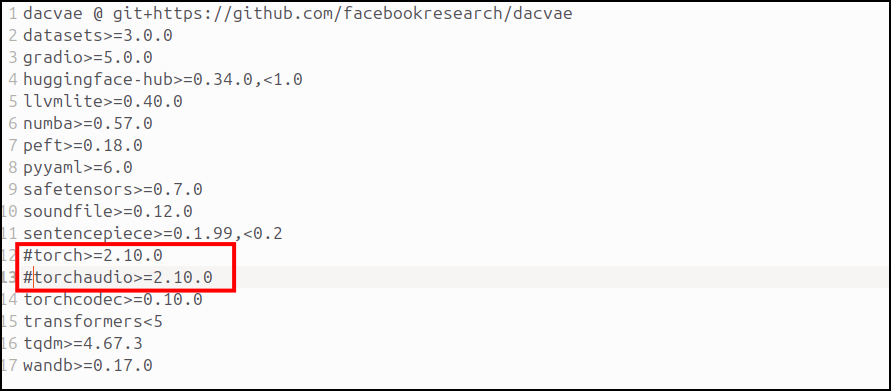
uv pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/xpuその次に「requirements.txt」をいじっていきます。
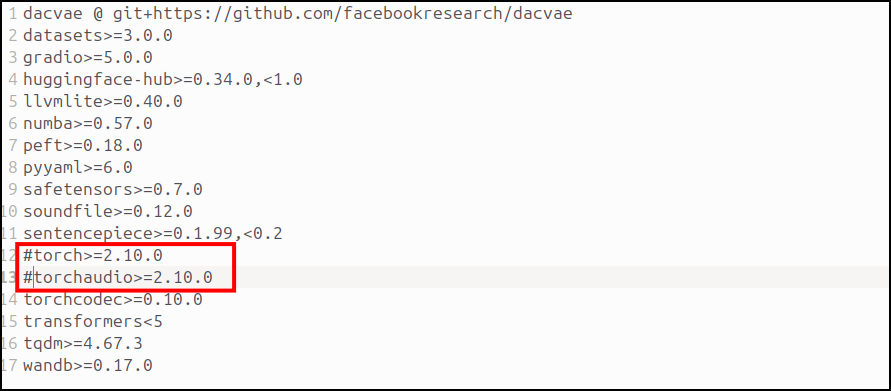
コメントアウトしたら以下のコマンドで「requirements.txt」をインストール。
uv pip install -r requirements.txtこれでIntel Arc用の環境は出来上がりです。
inference_runtime.pyを書き換え
Irodori-TTSフォルダ内の「irodori_tts/inference_runtime.py」をtorch.xpuで動くように書き換えます。ポイントだけ書いてもいいんですが、面倒なんで全てコピペしておいておきます。
もし詳細を知りたい方は、元の「inference_runtime.py」と下に書いてあるスクリプトをチャットAIに投げて相違点を聞いてみて下さい。
「if hasattr(torch, “xpu”) and torch.xpu.is_available(): devices.append(“xpu”)」のようにxpu用の分岐点をちょっと加えているだけで大したことはしていません(とはいえ、自力では作れませんが・・・)。
全文はメチャ長いので注意してください。
from __future__ import annotations
import gc
import json
import math
import secrets
import threading
import time
from collections.abc import Callable
from dataclasses import dataclass
from pathlib import Path
import torch
import torchaudio
from safetensors import safe_open
from safetensors.torch import load_file as load_safetensors_file
from .codec import DACVAECodec, patchify_latent, unpatchify_latent
from .config import ModelConfig
from .lora import checkpoint_state_uses_lora
from .model import TextToLatentRFDiT
from .rf import sample_euler_rf_cfg
from .text_normalization import normalize_text
from .tokenizer import PretrainedTextTokenizer
def _is_mps_available() -> bool:
backends = getattr(torch, "backends", None)
if backends is None or not hasattr(backends, "mps"):
return False
return bool(torch.backends.mps.is_available())
def resolve_runtime_device(device: str | torch.device) -> torch.device:
resolved = torch.device(device)
if resolved.type == "cpu":
return resolved
if resolved.type == "cuda":
if not torch.cuda.is_available():
raise ValueError("CUDA device requested but torch.cuda.is_available() is False.")
return resolved
if resolved.type == "xpu":
if not (hasattr(torch, "xpu") and torch.xpu.is_available()):
raise ValueError("XPU device requested but torch.xpu.is_available() is False.")
return resolved
if resolved.type == "mps":
if resolved.index is not None:
raise ValueError("MPS device index is not supported. Use 'mps'.")
if not _is_mps_available():
raise ValueError("MPS device requested but torch.backends.mps.is_available() is False.")
return torch.device("mps")
raise ValueError(f"Unsupported inference device={resolved!s}. Expected one of: cpu, cuda, mps.")
def list_available_runtime_devices() -> list[str]:
devices: list[str] = []
if torch.cuda.is_available():
devices.append("cuda")
if hasattr(torch, "xpu") and torch.xpu.is_available():
devices.append("xpu")
if _is_mps_available():
devices.append("mps")
devices.append("cpu")
return devices
def default_runtime_device() -> str:
return list_available_runtime_devices()[0]
def list_available_runtime_precisions(device: str | torch.device) -> list[str]:
resolved = resolve_runtime_device(device)
#if resolved.type == "cuda":
if resolved.type in ("cuda", "xpu"):
return ["fp32", "bf16"]
return ["fp32"]
def _sync_device(device: torch.device) -> None:
if device.type == "cuda":
torch.cuda.synchronize(device)
elif device.type == "xpu":
if hasattr(torch, "xpu") and hasattr(torch.xpu, "synchronize"):
torch.xpu.synchronize(device)
elif device.type == "mps":
mps = getattr(torch, "mps", None)
if mps is not None and hasattr(mps, "synchronize"):
mps.synchronize()
def _sync_devices(*devices: torch.device) -> None:
seen: set[tuple[str, int | None]] = set()
for device in devices:
key = (device.type, device.index)
if key in seen:
continue
_sync_device(device)
seen.add(key)
def _measure_start(device: torch.device, *extra_devices: torch.device) -> float:
_sync_devices(device, *extra_devices)
return time.perf_counter()
def _measure_end(device: torch.device, t0: float, *extra_devices: torch.device) -> float:
_sync_devices(device, *extra_devices)
return time.perf_counter() - t0
def _coerce_latent_shape(latent: torch.Tensor, latent_dim: int) -> torch.Tensor:
if latent.ndim == 3 and latent.shape[0] == 1:
latent = latent[0]
if latent.ndim != 2:
raise ValueError(f"Unsupported latent shape: {tuple(latent.shape)}")
if latent.shape[1] == latent_dim:
return latent
if latent.shape[0] == latent_dim:
return latent.transpose(0, 1).contiguous()
raise ValueError(
f"Could not infer latent layout for shape={tuple(latent.shape)} and latent_dim={latent_dim}"
)
def find_flattening_point(
latent: torch.Tensor,
target_value: float = 0.0,
window_size: int = 20,
std_threshold: float = 0.05,
mean_threshold: float = 0.1,
) -> int:
"""
Echo-style heuristic: find first index where a trailing window becomes near-flat and near-zero.
Args:
latent: (T, D) latent sequence.
Returns:
Flattening index in [0, T].
"""
if latent.ndim != 2:
raise ValueError(f"Expected latent shape (T, D), got {tuple(latent.shape)}")
total_steps = int(latent.shape[0])
if total_steps <= 0 or window_size <= 0:
return total_steps
pad = torch.zeros(
(window_size, latent.shape[1]),
device=latent.device,
dtype=latent.dtype,
)
padded = torch.cat([latent, pad], dim=0)
for i in range(padded.shape[0] - window_size):
window = padded[i : i + window_size]
window_std = window.std(unbiased=False)
window_mean = window.mean()
if window_std < std_threshold and torch.abs(window_mean - target_value) < mean_threshold:
return int(i)
return total_steps
@dataclass(frozen=True)
class RuntimeKey:
checkpoint: str
model_device: str
codec_repo: str = "Aratako/Semantic-DACVAE-Japanese-32dim"
model_precision: str = "fp32"
codec_device: str = "cpu"
codec_precision: str = "fp32"
codec_deterministic_encode: bool = True
codec_deterministic_decode: bool = True
enable_watermark: bool = False
compile_model: bool = False
compile_dynamic: bool = False
@dataclass
class SamplingRequest:
text: str
caption: str | None = None
ref_wav: str | None = None
ref_latent: str | None = None
no_ref: bool = False
ref_normalize_db: float | None = -16.0
ref_ensure_max: bool = True
num_candidates: int = 1
decode_mode: str = "sequential"
seconds: float = 30.0
max_ref_seconds: float | None = 30.0
max_text_len: int | None = None
max_caption_len: int | None = None
num_steps: int = 40
cfg_scale_text: float = 3.0
cfg_scale_caption: float = 3.0
cfg_scale_speaker: float = 5.0
cfg_guidance_mode: str = "independent"
cfg_scale: float | None = None
cfg_min_t: float = 0.5
cfg_max_t: float = 1.0
truncation_factor: float | None = None
rescale_k: float | None = None
rescale_sigma: float | None = None
context_kv_cache: bool = True
speaker_kv_scale: float | None = None
speaker_kv_min_t: float | None = None
speaker_kv_max_layers: int | None = None
seed: int | None = None
trim_tail: bool = True
tail_window_size: int = 20
tail_std_threshold: float = 0.05
tail_mean_threshold: float = 0.1
@dataclass
class SamplingResult:
audio: torch.Tensor
audios: list[torch.Tensor]
sample_rate: int
stage_timings: list[tuple[str, float]]
total_to_decode: float
used_seed: int
messages: list[str]
def _maybe_compile_inference_model(
model: TextToLatentRFDiT,
*,
enabled: bool,
dynamic: bool,
) -> TextToLatentRFDiT:
if not enabled:
return model
if not hasattr(torch, "compile"):
raise RuntimeError("compile_model=True requires torch.compile (PyTorch 2+).")
compile_kwargs = {"dynamic": bool(dynamic)}
model.encode_conditions = torch.compile(model.encode_conditions, **compile_kwargs)
model.build_context_kv_cache = torch.compile(model.build_context_kv_cache, **compile_kwargs)
model.forward_with_encoded_conditions = torch.compile(
model.forward_with_encoded_conditions,
**compile_kwargs,
)
return model
def resolve_runtime_dtype(*, precision: str, device: torch.device) -> torch.dtype:
mode = str(precision).strip().lower()
if mode == "fp32":
return torch.float32
if mode == "bf16":
# cuda だけでなく xpu も許可
if device.type not in ("cuda", "xpu"):
raise ValueError("precision='bf16' currently requires CUDA or XPU device.")
return torch.bfloat16
raise ValueError(f"Unsupported precision={precision!r}. Expected one of: fp32, bf16.")
def resolve_cfg_scales(
*,
cfg_guidance_mode: str,
cfg_scale_text: float,
cfg_scale_caption: float,
cfg_scale_speaker: float,
cfg_scale: float | None,
use_caption_condition: bool = True,
use_speaker_condition: bool = True,
) -> tuple[float, float, float, list[str]]:
"""Normalize/validate CFG scales for guidance mode."""
messages: list[str] = []
text_val = float(cfg_scale_text)
caption_val = float(cfg_scale_caption)
speaker_val = float(cfg_scale_speaker)
if cfg_scale is not None:
text_val = float(cfg_scale)
caption_val = float(cfg_scale)
speaker_val = float(cfg_scale)
if not use_speaker_condition:
if speaker_val > 0.0:
messages.append(
"info: speaker conditioning is disabled for this checkpoint; ignoring cfg_scale_speaker."
)
speaker_val = 0.0
mode = str(cfg_guidance_mode).strip().lower()
enabled_vals = [value for value in (text_val, speaker_val) if value > 0.0]
if use_caption_condition and caption_val > 0.0:
enabled_vals.append(caption_val)
if mode == "joint" and enabled_vals and (max(enabled_vals) - min(enabled_vals) > 1e-6):
raise ValueError(
"cfg_guidance_mode='joint' requires equal enabled cfg_scale_text/cfg_scale_caption/cfg_scale_speaker, "
"or set cfg_scale."
)
return text_val, caption_val, speaker_val, messages
def _load_torch_checkpoint_payload(path: Path) -> dict:
payload = torch.load(path, map_location="cpu", weights_only=True)
if not isinstance(payload, dict):
raise ValueError(f"Unsupported checkpoint payload type: {type(payload)!r}")
return payload
_CONFIG_META_KEY = "config_json"
_INFERENCE_CONFIG_KEYS = {"max_text_len", "max_caption_len", "fixed_target_latent_steps"}
def _load_checkpoint_from_pt(path: Path) -> tuple[dict[str, torch.Tensor], dict, dict | None]:
ckpt = _load_torch_checkpoint_payload(path)
model_state = ckpt.get("model")
model_cfg = ckpt.get("model_config")
train_cfg = ckpt.get("train_config")
if not isinstance(model_state, dict):
raise ValueError(f"Checkpoint missing model weights dictionary: {path}")
if not isinstance(model_cfg, dict):
raise ValueError(f"Checkpoint missing model_config dictionary: {path}")
if train_cfg is not None and not isinstance(train_cfg, dict):
raise ValueError(f"Checkpoint train_config must be a dictionary when present: {path}")
if checkpoint_state_uses_lora(model_state):
raise ValueError(
f"LoRA checkpoints must be loaded from adapter directories or merged safetensors: {path}"
)
return model_state, model_cfg, _extract_inference_train_config(train_cfg)
def _parse_json_mapping(
raw: str | None,
*,
field: str,
path: Path,
required: bool = False,
) -> dict | None:
if raw is None:
if required:
raise ValueError(f"Missing required metadata field '{field}' in checkpoint: {path}")
return None
try:
payload = json.loads(raw)
except json.JSONDecodeError as exc:
raise ValueError(f"Invalid JSON in '{field}' metadata for checkpoint: {path}") from exc
if not isinstance(payload, dict):
raise ValueError(f"Metadata field '{field}' must decode to an object: {path}")
return payload
def _extract_inference_train_config(raw: dict | None) -> dict | None:
if raw is None:
return None
inference_cfg: dict[str, int] = {}
for key in _INFERENCE_CONFIG_KEYS:
value = raw.get(key)
if value is None:
continue
if not isinstance(value, int):
raise ValueError(f"Inference config key '{key}' must be int, got {type(value)!r}.")
inference_cfg[key] = int(value)
return inference_cfg or None
def _split_flat_checkpoint_config(path: Path, flat_config: dict) -> tuple[dict, dict | None]:
model_cfg: dict[str, object] = {}
inference_cfg: dict[str, int] = {}
for key, value in flat_config.items():
if key in _INFERENCE_CONFIG_KEYS:
if not isinstance(value, int):
raise ValueError(
f"Inference config key '{key}' must be int in checkpoint metadata: {path}"
)
inference_cfg[key] = int(value)
continue
model_cfg[key] = value
return model_cfg, (inference_cfg or None)
def _load_checkpoint_from_safetensors(
path: Path,
) -> tuple[dict[str, torch.Tensor], dict, dict | None]:
model_state = load_safetensors_file(str(path), device="cpu")
if not isinstance(model_state, dict) or not model_state:
raise ValueError(f"Safetensors checkpoint has no model weights: {path}")
with safe_open(str(path), framework="pt", device="cpu") as handle:
metadata = handle.metadata() or {}
flat_config = _parse_json_mapping(
metadata.get(_CONFIG_META_KEY),
field=_CONFIG_META_KEY,
path=path,
required=True,
)
model_cfg, inference_cfg = _split_flat_checkpoint_config(path=path, flat_config=flat_config)
return model_state, model_cfg, inference_cfg
def _load_checkpoint_for_inference(path: Path) -> tuple[dict[str, torch.Tensor], dict, dict | None]:
if path.suffix.lower() == ".safetensors":
return _load_checkpoint_from_safetensors(path)
return _load_checkpoint_from_pt(path)
class InferenceRuntime:
def __init__(
self,
*,
key: RuntimeKey,
model_cfg: ModelConfig,
train_cfg: dict | None,
model: TextToLatentRFDiT,
tokenizer: PretrainedTextTokenizer,
caption_tokenizer: PretrainedTextTokenizer | None,
codec: DACVAECodec,
default_text_max_len: int,
default_caption_max_len: int,
) -> None:
self.key = key
self.model_device = resolve_runtime_device(key.model_device)
self.codec_device = resolve_runtime_device(key.codec_device)
self.model_cfg = model_cfg
self.train_cfg = train_cfg
self.model = model
self.tokenizer = tokenizer
self.caption_tokenizer = caption_tokenizer
self.codec = codec
self.default_text_max_len = default_text_max_len
self.default_caption_max_len = default_caption_max_len
self._infer_lock = threading.Lock()
@classmethod
def from_key(cls, key: RuntimeKey) -> InferenceRuntime:
model_device = resolve_runtime_device(key.model_device)
codec_device = resolve_runtime_device(key.codec_device)
model_dtype = resolve_runtime_dtype(
precision=key.model_precision,
device=model_device,
)
codec_dtype = resolve_runtime_dtype(
precision=key.codec_precision,
device=codec_device,
)
model_state, model_cfg_dict, train_cfg = _load_checkpoint_for_inference(
Path(key.checkpoint)
)
model_cfg = ModelConfig(**model_cfg_dict)
model = TextToLatentRFDiT(model_cfg).to(model_device)
model.load_state_dict(model_state)
model = model.to(dtype=model_dtype)
model.eval()
model = _maybe_compile_inference_model(
model,
enabled=bool(key.compile_model),
dynamic=bool(key.compile_dynamic),
)
tokenizer = PretrainedTextTokenizer.from_pretrained(
repo_id=model_cfg.text_tokenizer_repo,
add_bos=bool(model_cfg.text_add_bos),
local_files_only=False,
)
if tokenizer.vocab_size != model_cfg.text_vocab_size:
raise ValueError(
f"text_vocab_size mismatch: checkpoint text_vocab_size={model_cfg.text_vocab_size} but tokenizer "
f"({model_cfg.text_tokenizer_repo}) vocab_size={tokenizer.vocab_size}."
)
caption_tokenizer = None
if model_cfg.use_caption_condition:
caption_tokenizer = PretrainedTextTokenizer.from_pretrained(
repo_id=model_cfg.caption_tokenizer_repo_resolved,
add_bos=model_cfg.caption_add_bos_resolved,
local_files_only=False,
)
if caption_tokenizer.vocab_size != model_cfg.caption_vocab_size_resolved:
raise ValueError(
f"caption_vocab_size mismatch: checkpoint caption_vocab_size={model_cfg.caption_vocab_size_resolved} but tokenizer ({model_cfg.caption_tokenizer_repo_resolved}) "
f"vocab_size={caption_tokenizer.vocab_size}."
)
default_text_max_len = 256
default_caption_max_len = default_text_max_len
if isinstance(train_cfg, dict):
ckpt_text_max_len = train_cfg.get("max_text_len")
if isinstance(ckpt_text_max_len, int) and ckpt_text_max_len > 0:
default_text_max_len = int(ckpt_text_max_len)
ckpt_caption_max_len = train_cfg.get("max_caption_len")
if isinstance(ckpt_caption_max_len, int) and ckpt_caption_max_len > 0:
default_caption_max_len = int(ckpt_caption_max_len)
else:
default_caption_max_len = default_text_max_len
codec = DACVAECodec.load(
repo_id=key.codec_repo,
device=str(codec_device),
dtype=codec_dtype,
deterministic_encode=bool(key.codec_deterministic_encode),
deterministic_decode=bool(key.codec_deterministic_decode),
enable_watermark=bool(key.enable_watermark),
)
if model_cfg.latent_dim != codec.latent_dim:
raise ValueError(
f"Latent dimension mismatch: checkpoint latent_dim={model_cfg.latent_dim} but codec latent_dim={codec.latent_dim}. "
"Use a compatible codec/checkpoint pair."
)
return cls(
key=key,
model_cfg=model_cfg,
train_cfg=train_cfg if isinstance(train_cfg, dict) else None,
model=model,
tokenizer=tokenizer,
caption_tokenizer=caption_tokenizer,
codec=codec,
default_text_max_len=default_text_max_len,
default_caption_max_len=default_caption_max_len,
)
def _load_reference_latent(
self,
*,
req: SamplingRequest,
batch_size: int,
messages: list[str],
) -> tuple[torch.Tensor | None, torch.Tensor | None]:
runtime_dtype = next(self.model.parameters()).dtype
if not self.model_cfg.use_speaker_condition:
if req.ref_wav is not None or req.ref_latent is not None:
messages.append(
"info: speaker conditioning is disabled for this checkpoint; ignoring reference input."
)
return None, None
if req.no_ref:
ref_len = max(1, int(self.model_cfg.speaker_patch_size))
ref_latent_patched = torch.zeros(
(
batch_size,
ref_len,
self.model_cfg.latent_dim * self.model_cfg.latent_patch_size,
),
device=self.model_device,
dtype=runtime_dtype,
)
ref_mask = torch.zeros(
(batch_size, ref_len), dtype=torch.bool, device=self.model_device
)
return ref_latent_patched, ref_mask
if req.ref_wav is None and req.ref_latent is None:
raise ValueError("Specify either ref_wav/ref_latent, or set no_ref=True.")
max_ref_latent_steps = None
if req.max_ref_seconds is not None and req.max_ref_seconds > 0:
max_ref_latent_steps = max(
1,
math.ceil(
float(req.max_ref_seconds)
* float(self.codec.sample_rate)
/ float(int(self.codec.model.hop_length))
),
)
if req.ref_latent is not None:
latent_raw = torch.load(req.ref_latent, map_location="cpu", weights_only=True)
ref_latent = _coerce_latent_shape(
latent_raw, latent_dim=self.model_cfg.latent_dim
).unsqueeze(0)
ref_latent = ref_latent.to(dtype=runtime_dtype)
else:
wav, sr = _load_audio(req.ref_wav)
if req.max_ref_seconds is not None and req.max_ref_seconds > 0:
max_ref_samples = max(1, int(float(req.max_ref_seconds) * float(sr)))
if wav.shape[1] > max_ref_samples:
messages.append(
f"warning: reference audio exceeds max_ref_seconds ({req.max_ref_seconds}s). "
f"Trimming from {float(wav.shape[1]) / float(sr):.2f}s to {float(max_ref_samples) / float(sr):.2f}s."
)
wav = wav[:, :max_ref_samples]
if req.ref_normalize_db is not None:
messages.append(
f"info: reference loudness normalize enabled (target_db={float(req.ref_normalize_db):.2f}, includes peak safety scaling)."
)
elif req.ref_ensure_max:
messages.append("info: reference peak safety scaling enabled (ensure_max=True).")
ref_latent = self.codec.encode_waveform(
wav.unsqueeze(0),
sample_rate=int(sr),
normalize_db=req.ref_normalize_db,
ensure_max=bool(req.ref_ensure_max),
).cpu()
if max_ref_latent_steps is not None and ref_latent.shape[1] > max_ref_latent_steps:
messages.append(
f"warning: reference latent steps ({ref_latent.shape[1]}) exceed max_ref_seconds bound ({max_ref_latent_steps} steps). "
"Trimming reference latent."
)
ref_latent = ref_latent[:, :max_ref_latent_steps]
ref_latent_patched = patchify_latent(ref_latent, self.model_cfg.latent_patch_size).to(
self.model_device
)
if ref_latent_patched.shape[1] == 0:
raise ValueError(
"Reference latent length became zero after patchify. Use longer reference audio."
)
if batch_size > 1:
ref_latent_patched = ref_latent_patched.repeat(batch_size, 1, 1)
ref_mask = torch.ones(
(batch_size, ref_latent_patched.shape[1]), dtype=torch.bool, device=self.model_device
)
return ref_latent_patched, ref_mask
def synthesize(
self,
req: SamplingRequest,
*,
log_fn: Callable[[str], None] | None = None,
) -> SamplingResult:
def _log(msg: str) -> None:
if log_fn is not None:
log_fn(msg)
messages: list[str] = []
_log(
(
"[runtime] start synthesize "
"model_device={} model_precision={} codec_device={} codec_precision={} "
"watermark={} mode={} seconds={} steps={} seed={} candidates={} decode_mode={}"
).format(
self.key.model_device,
self.key.model_precision,
self.key.codec_device,
self.key.codec_precision,
self.codec.enable_watermark,
req.cfg_guidance_mode,
req.seconds,
req.num_steps,
"random" if req.seed is None else int(req.seed),
req.num_candidates,
req.decode_mode,
)
)
if req.seconds <= 0:
raise ValueError(f"seconds must be > 0, got {req.seconds}")
num_candidates = int(req.num_candidates)
if num_candidates <= 0:
raise ValueError(f"num_candidates must be > 0, got {num_candidates}")
decode_mode = str(req.decode_mode).strip().lower()
if decode_mode not in {"sequential", "batch"}:
raise ValueError(
f"Unsupported decode_mode={req.decode_mode!r}. Expected one of: sequential, batch."
)
raw_text = str(req.text)
normalized_text = normalize_text(raw_text).strip()
if normalized_text == "":
raise ValueError("text became empty after normalization.")
text_max_len = (
self.default_text_max_len if req.max_text_len is None else int(req.max_text_len)
)
if text_max_len <= 0:
raise ValueError(f"max_text_len must be > 0, got {text_max_len}")
caption_max_len = (
self.default_caption_max_len
if req.max_caption_len is None
else int(req.max_caption_len)
)
if self.model_cfg.use_caption_condition and caption_max_len <= 0:
raise ValueError(f"max_caption_len must be > 0, got {caption_max_len}")
has_caption_text = bool(
self.model_cfg.use_caption_condition
and req.caption is not None
and str(req.caption).strip() != ""
)
truncation_factor = None if req.truncation_factor is None else float(req.truncation_factor)
rescale_k = None if req.rescale_k is None else float(req.rescale_k)
rescale_sigma = None if req.rescale_sigma is None else float(req.rescale_sigma)
if truncation_factor is not None and truncation_factor <= 0:
raise ValueError(f"truncation_factor must be > 0, got {truncation_factor}")
if (rescale_k is None) != (rescale_sigma is None):
raise ValueError("rescale_k and rescale_sigma must be set together.")
if rescale_k is not None and rescale_k <= 0:
raise ValueError(f"rescale_k must be > 0, got {rescale_k}")
if rescale_sigma is not None and rescale_sigma <= 0:
raise ValueError(f"rescale_sigma must be > 0, got {rescale_sigma}")
speaker_kv_scale = None if req.speaker_kv_scale is None else float(req.speaker_kv_scale)
speaker_kv_min_t = None
speaker_kv_max_layers = (
None if req.speaker_kv_max_layers is None else int(req.speaker_kv_max_layers)
)
if speaker_kv_scale is not None:
if not self.model_cfg.use_speaker_condition:
messages.append(
"info: speaker conditioning is disabled for this checkpoint; ignoring speaker_kv_scale."
)
speaker_kv_scale = None
else:
if speaker_kv_scale <= 0:
raise ValueError(f"speaker_kv_scale must be > 0, got {speaker_kv_scale}")
speaker_kv_min_t = (
0.9 if req.speaker_kv_min_t is None else float(req.speaker_kv_min_t)
)
if not (0.0 <= speaker_kv_min_t <= 1.0):
raise ValueError(f"speaker_kv_min_t must be in [0, 1], got {speaker_kv_min_t}")
if speaker_kv_max_layers is not None and speaker_kv_max_layers < 0:
raise ValueError(
f"speaker_kv_max_layers must be >= 0 when specified, got {speaker_kv_max_layers}"
)
cfg_mode = str(req.cfg_guidance_mode).strip().lower()
if cfg_mode not in {"independent", "joint", "alternating"}:
raise ValueError(
f"Unsupported cfg_guidance_mode={req.cfg_guidance_mode!r}. "
"Expected one of: independent, joint, alternating."
)
cfg_scale_text, cfg_scale_caption, cfg_scale_speaker, scale_messages = resolve_cfg_scales(
cfg_guidance_mode=cfg_mode,
cfg_scale_text=req.cfg_scale_text,
cfg_scale_caption=req.cfg_scale_caption,
cfg_scale_speaker=req.cfg_scale_speaker,
cfg_scale=req.cfg_scale,
use_caption_condition=has_caption_text,
use_speaker_condition=self.model_cfg.use_speaker_condition,
)
messages.extend(scale_messages)
for msg in scale_messages:
_log(msg)
stage_timings: list[tuple[str, float]] = []
if req.seed is None:
used_seed = int(secrets.randbits(63))
msg = f"info: seed not specified; using random seed {used_seed}."
messages.append(msg)
_log(msg)
else:
used_seed = int(req.seed)
_log(f"[runtime] using seed: {used_seed}")
post_load_t0 = _measure_start(self.model_device, self.codec_device)
with self._infer_lock, torch.inference_mode():
t0 = _measure_start(self.model_device)
text_ids, text_mask = self.tokenizer.batch_encode(
[normalized_text] * num_candidates,
max_length=text_max_len,
)
stage_sec = _measure_end(self.model_device, t0)
stage_timings.append(("tokenize_text", stage_sec))
_log(f"[runtime] tokenize_text: {stage_sec * 1000.0:.1f} ms")
text_ids = text_ids.to(self.model_device)
text_mask = text_mask.to(self.model_device)
caption_ids = None
caption_mask = None
if self.model_cfg.use_caption_condition:
if self.caption_tokenizer is None:
raise RuntimeError(
"Caption conditioning is enabled but caption tokenizer is not loaded."
)
caption_text = "" if req.caption is None else str(req.caption).strip()
caption_ids, caption_mask = self.caption_tokenizer.batch_encode(
[caption_text] * num_candidates,
max_length=caption_max_len,
)
if caption_text == "":
caption_mask.zero_()
caption_ids = caption_ids.to(self.model_device)
caption_mask = caption_mask.to(self.model_device)
target_samples = int(float(req.seconds) * self.codec.sample_rate)
latent_steps = math.ceil(target_samples / int(self.codec.model.hop_length))
patched_steps = math.ceil(latent_steps / self.model_cfg.latent_patch_size)
if isinstance(self.train_cfg, dict):
fixed_steps = self.train_cfg.get("fixed_target_latent_steps")
if isinstance(fixed_steps, int) and fixed_steps > 0 and latent_steps > fixed_steps:
msg = (
f"warning: requested latent length ({latent_steps}) exceeds fixed_target_latent_steps ({fixed_steps}) "
"used in training. Long-tail stability may degrade."
)
messages.append(msg)
_log(msg)
t0 = _measure_start(self.model_device, self.codec_device)
msg_count_before_ref = len(messages)
ref_latent, ref_mask = self._load_reference_latent(
req=req,
batch_size=num_candidates,
messages=messages,
)
stage_sec = _measure_end(self.model_device, t0, self.codec_device)
stage_timings.append(("prepare_reference", stage_sec))
for msg in messages[msg_count_before_ref:]:
_log(msg)
_log(f"[runtime] prepare_reference: {stage_sec * 1000.0:.1f} ms")
t0 = _measure_start(self.model_device)
z_patched = sample_euler_rf_cfg(
model=self.model,
text_input_ids=text_ids,
text_mask=text_mask,
ref_latent=ref_latent,
ref_mask=ref_mask,
sequence_length=patched_steps,
caption_input_ids=caption_ids,
caption_mask=caption_mask,
num_steps=int(req.num_steps),
cfg_scale_text=cfg_scale_text,
cfg_scale_caption=cfg_scale_caption,
cfg_scale_speaker=cfg_scale_speaker,
cfg_guidance_mode=cfg_mode,
cfg_min_t=float(req.cfg_min_t),
cfg_max_t=float(req.cfg_max_t),
seed=used_seed,
truncation_factor=truncation_factor,
rescale_k=rescale_k,
rescale_sigma=rescale_sigma,
use_context_kv_cache=bool(req.context_kv_cache),
speaker_kv_scale=speaker_kv_scale,
speaker_kv_max_layers=speaker_kv_max_layers,
speaker_kv_min_t=speaker_kv_min_t,
)
stage_sec = _measure_end(self.model_device, t0)
stage_timings.append(("sample_rf", stage_sec))
_log(f"[runtime] sample_rf: {stage_sec * 1000.0:.1f} ms")
t0 = _measure_start(self.model_device)
z = unpatchify_latent(
z_patched,
patch_size=self.model_cfg.latent_patch_size,
latent_dim=self.model_cfg.latent_dim,
)
stage_sec = _measure_end(self.model_device, t0)
stage_timings.append(("unpatchify_latent", stage_sec))
_log(f"[runtime] unpatchify_latent: {stage_sec * 1000.0:.1f} ms")
z = z[:, :latent_steps]
t0 = _measure_start(self.model_device, self.codec_device)
trimmed_audios: list[torch.Tensor] = []
if decode_mode == "batch":
audio_batch = self.codec.decode_latent(z).cpu()
for i in range(num_candidates):
audio_i = audio_batch[i]
max_samples = target_samples
if bool(req.trim_tail):
flattening_point = find_flattening_point(
z[i],
window_size=max(1, int(req.tail_window_size)),
std_threshold=float(req.tail_std_threshold),
mean_threshold=float(req.tail_mean_threshold),
)
flattening_samples = int(
flattening_point * int(self.codec.model.hop_length)
)
if flattening_samples > 0:
max_samples = min(max_samples, flattening_samples)
trimmed_audios.append(audio_i[:, :max_samples])
else:
for i in range(num_candidates):
audio_i = self.codec.decode_latent(z[i : i + 1]).cpu()[0]
max_samples = target_samples
if bool(req.trim_tail):
flattening_point = find_flattening_point(
z[i],
window_size=max(1, int(req.tail_window_size)),
std_threshold=float(req.tail_std_threshold),
mean_threshold=float(req.tail_mean_threshold),
)
flattening_samples = int(
flattening_point * int(self.codec.model.hop_length)
)
if flattening_samples > 0:
max_samples = min(max_samples, flattening_samples)
trimmed_audios.append(audio_i[:, :max_samples])
stage_sec = _measure_end(self.model_device, t0, self.codec_device)
stage_timings.append(("decode_latent", stage_sec))
_log(f"[runtime] decode_latent ({decode_mode}): {stage_sec * 1000.0:.1f} ms")
total_to_decode = _measure_end(self.model_device, post_load_t0, self.codec_device)
_log(f"[runtime] total_to_decode: {total_to_decode:.3f} s")
_log("[runtime] done synthesize")
return SamplingResult(
audio=trimmed_audios[0],
audios=trimmed_audios,
sample_rate=int(self.codec.sample_rate),
stage_timings=stage_timings,
total_to_decode=total_to_decode,
used_seed=used_seed,
messages=messages,
)
def unload(self) -> None:
del self.model
del self.tokenizer
del self.codec
gc.collect()
for device in (self.model_device, self.codec_device):
if device.type == "cuda":
torch.cuda.empty_cache()
elif device.type == "xpu":
if hasattr(torch, "xpu") and hasattr(torch.xpu, "empty_cache"):
torch.xpu.empty_cache()
elif device.type == "mps":
mps = getattr(torch, "mps", None)
if mps is not None and hasattr(mps, "empty_cache"):
mps.empty_cache()
_RUNTIME_CACHE_LOCK = threading.Lock()
_RUNTIME_CACHE_KEY: RuntimeKey | None = None
_RUNTIME_CACHE_VALUE: InferenceRuntime | None = None
def get_cached_runtime(key: RuntimeKey) -> tuple[InferenceRuntime, bool]:
global _RUNTIME_CACHE_KEY, _RUNTIME_CACHE_VALUE
with _RUNTIME_CACHE_LOCK:
if _RUNTIME_CACHE_VALUE is not None and _RUNTIME_CACHE_KEY == key:
return _RUNTIME_CACHE_VALUE, False
old_runtime = _RUNTIME_CACHE_VALUE
runtime = InferenceRuntime.from_key(key)
_RUNTIME_CACHE_KEY = key
_RUNTIME_CACHE_VALUE = runtime
if old_runtime is not None:
old_runtime.unload()
return runtime, True
def clear_cached_runtime() -> None:
global _RUNTIME_CACHE_KEY, _RUNTIME_CACHE_VALUE
with _RUNTIME_CACHE_LOCK:
runtime = _RUNTIME_CACHE_VALUE
_RUNTIME_CACHE_KEY = None
_RUNTIME_CACHE_VALUE = None
if runtime is not None:
runtime.unload()
def _load_audio(path: str | Path) -> tuple[torch.Tensor, int]:
try:
return torchaudio.load(str(path))
except RuntimeError:
import soundfile as sf
data, sr = sf.read(str(path), dtype="float32")
wav = torch.from_numpy(data)
if wav.ndim == 1:
wav = wav.unsqueeze(0)
else:
wav = wav.T
return wav, sr
def save_wav(path: str | Path, audio: torch.Tensor, sample_rate: int) -> Path:
out_path = Path(path)
out_path.parent.mkdir(parents=True, exist_ok=True)
# ↓ここを追加:WAV保存前に確実にCPU上のfloat32に変換する
audio_fp32 = audio.detach().cpu().to(torch.float32)
try:
torchaudio.save(str(out_path), audio_fp32, sample_rate)
except RuntimeError:
import soundfile as sf
# audio.squeeze(0) ではなく audio_fp32.squeeze(0) を使う
sf.write(str(out_path), audio_fp32.squeeze(0).numpy(), sample_rate)
return out_pathそれでは動かしてみましょう
とりあえず、テストで動かすコマンドです。
.venv/bin/python infer.py \
--hf-checkpoint Aratako/Irodori-TTS-500M-v2 \
--text "今日はいい天気ですね。" \
--no-ref \
--output-wav outputs/sample.wav \
--model-precision bf16 \
--codec-precision bf16どうでしょうか?生成されましたか?
最初はモデルのロードとかあるから時間がかかりますが、Intel Arc A750では生成自体は8秒ほどでした。
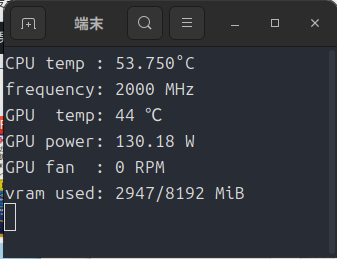
VRAM使用量も一瞬4GBまで膨らむこともありますが、この程度ならIntel Arc A380でも大丈夫そう。
最後に
現状「torchcodec」はNvidia用になっているので、「inference_runtime.py」の最後のあたりで上手く動くよう、いつものGeminiに書き直してもらいました。
あとは「bf16」でも動くよう変更してもらってます。
もし、動かないよって人がいたらエラーコードを教えて下さい。
まぁ自分に聞くより、チャットAIに聞いたほうが速いと思いますが・・・。
今回は以上です。



「Pro B50」やAsRock製の「Pro B60」なんてめずらしいモノが出てますね。
Amazon倉庫からの出荷ではないので、購入する時は自己責任でお願いします。



コメント