Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。
今はQwen3.6が話題ですが、自分はまだ試していないので。
今回はgemma-4についてです。
とはいえ、こちらの記事でも触れたとおり、現在は「Intel Arc A750」なので大きなモデルは試せません。
いえ、試せるんですができればモデルファイルをVRAMに全部おさめて高速で動く様をみたいです。メインメモリに退避させると動画生成などと比べて、すごく遅くなっちゃうので。
今回使うのはこのモデル。

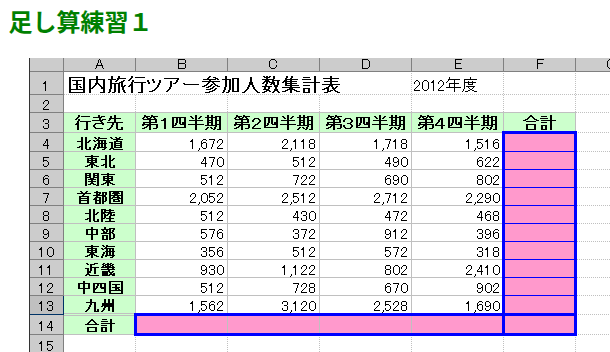
マルチモーダルに対応しているということで、「llama.cpp」に画像認識機能を持たせexcelの問題を解いてもらいます。
それでは、いってみましょう。
モデルのダウンロード
huggingface_hubを使っていきます。
個人的な話で申し訳ありませんが、最近引っ越しました。
ところが、ネット環境があまりよろしくなく、LLMのような巨大なファイルをダウンロードしていると、途中で回線が途切れたりとどうにも不安定な時間帯がありまして。
「huggingface_hub」なら途中で回線を遮断しても、再開が容易です。
というわけで「huggingface」のアクセストークンをメモっておきます。

では、ここからモデルのダウンロードです。
適当にターミナルを開いて、
sudo apt install curl
curl -LsSf https://astral.sh/uv/install.sh | sh
source $HOME/.local/bin/env
uv venv --python /usr/bin/python3
source .venv/bin/activate
uv pip install huggingface_hub
hf auth login
#さっきのアクセストークンを入力
#haggingface-hubが新しくなってから、haggingface-cliは動かなくなったみたいなので「hf download」を使う
hf download google/gemma-4-E4B-it --local-dir ./gemma-4-E4B-it以下を実行。
LLMとしては割と小さめですが、それでも16GBです。
A750(VRAM8GB)では収まりません。
なので次はこれを量子化していきます。
safetensorをggufに「フォーマット変換」
では、safetensorをggufに「フォーマット変換」していきますが、その前に「llama.cpp」をインストールしましょう。
#!/bin/bash
mkdir -p $HOME/install/llama.cpp_build
cd ~/install/llama.cpp_build
#準備とllama.cppのソースのダウンロード
sudo apt install -y git cmake g++ libcurlpp-dev
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
#CPU用ビルド(ggufの変換で使う)
mkdir build-cpu
cmake -B build-cpu
cmake --build build-cpu --config Release -j$(nproc)
ここからフォーマット変換します。
#まずは環境構築
uv venv .venv_llama --python /usr/bin/python3
source .venv_llama/bin/activate
uv pip install -r ./llama.cpp/requirements.txt --index-strategy unsafe-best-match
#safetensorsからggufへ
python ./llama.cpp/convert_hf_to_gguf.py ./gemma4-E4B-it/ --outfile gemma4-E4B-it.gguf
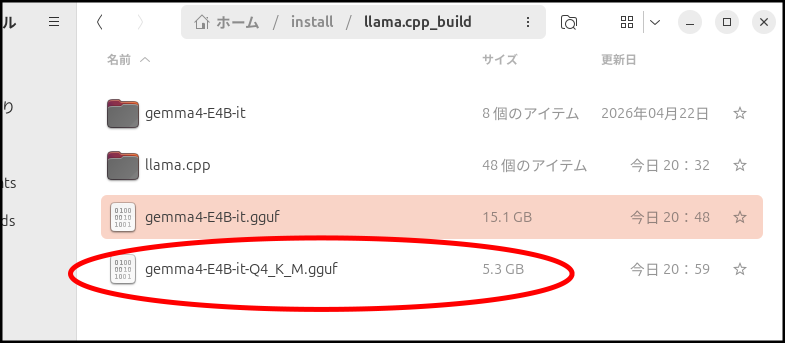
gemma4-E4B-it.ggufを量子化
なるべく推論精度を落とさずにファイルサイズを劇的に小さくしていきます。
といっても、VRAM8GBに収めようとしたら多少の精度低下は目を瞑りましょう。
今回は「Q4_K_M」にします。
./llama.cpp/build-cpu/bin/llama-quantize ./gemma4-E4B-it.gguf ./gemma4-E4B-it-Q4_K_M.gguf Q4_K_M
「マルチモーダル・プロジェクター」もつくろう
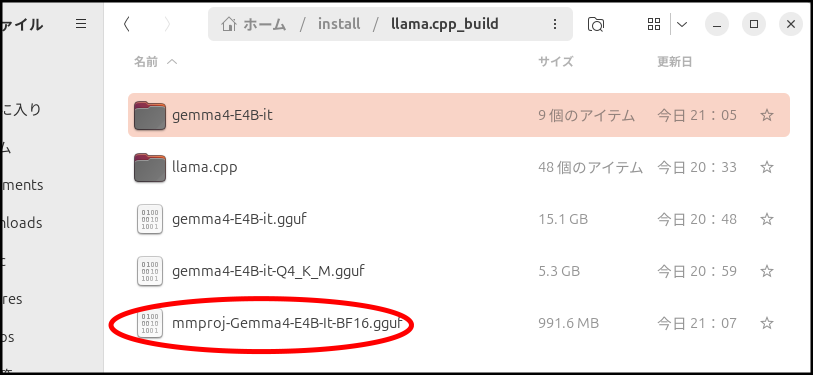
今回は画像認識もさせるため、「マルチモーダル・プロジェクター」も作ります。
llama.cpp/convert_hf_to_gguf.py ./gemma4-E4B-it/ --mmproj --outfile ./mmproj-Gemma4-E4B-It-BF16.gguf
llama.cppをvulkanでビルド
以前の記事でも書きましたが、改めて書いていきます。
今回はsyclではなくvulkanでビルドします。
#!/bin/bash
sudo apt update
sudo apt install -y spirv-headers
#vulkanビルド
cd $HOME/install/llama.cpp_build/llama.cpp
mkdir -p build-vulkan
sudo apt install -y libvulkan-dev glslc spirv-headers
cmake -B build-vulkan -DGGML_VULKAN=ON
cmake --build build-vulkan --config Release -j$(nproc)2026/4から「spirv-headers」をインストールしないとビルドエラーが出るようになったらしいです。
llama.cppで画像認識
普通にチャットするだけなら、今までいくつか記事を書いてきました。
今回は画像認識させて、更にその問題も解いてもらいます。
まずは画像認識できるようにllama.cppを立ち上げます。
cd $HOME/install/llama.cpp_build
./llama.cpp/build-vulkan/bin/llama-server -m gemma4-E4B-it-Q4_K_M.gguf --mmproj mmproj-Gemma4-E4B-It-BF16.gguf --port 8080 --host 127.0.0.1 --jinja --reasoning off以下のUIを起動するには、こちらの記事を参考にしてください。
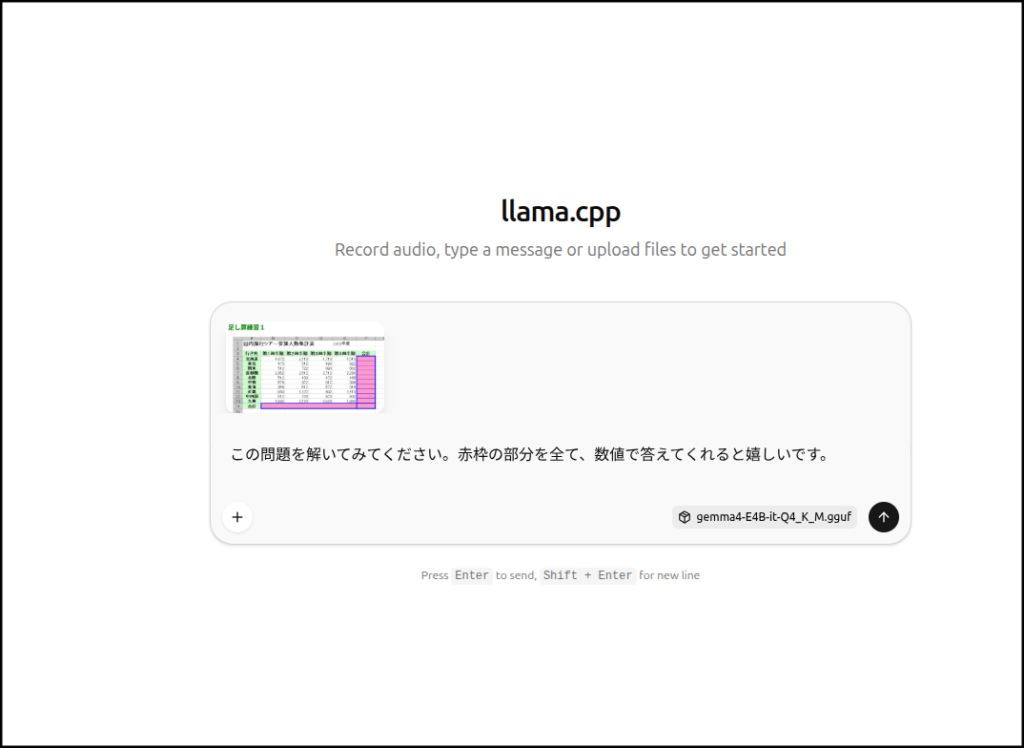
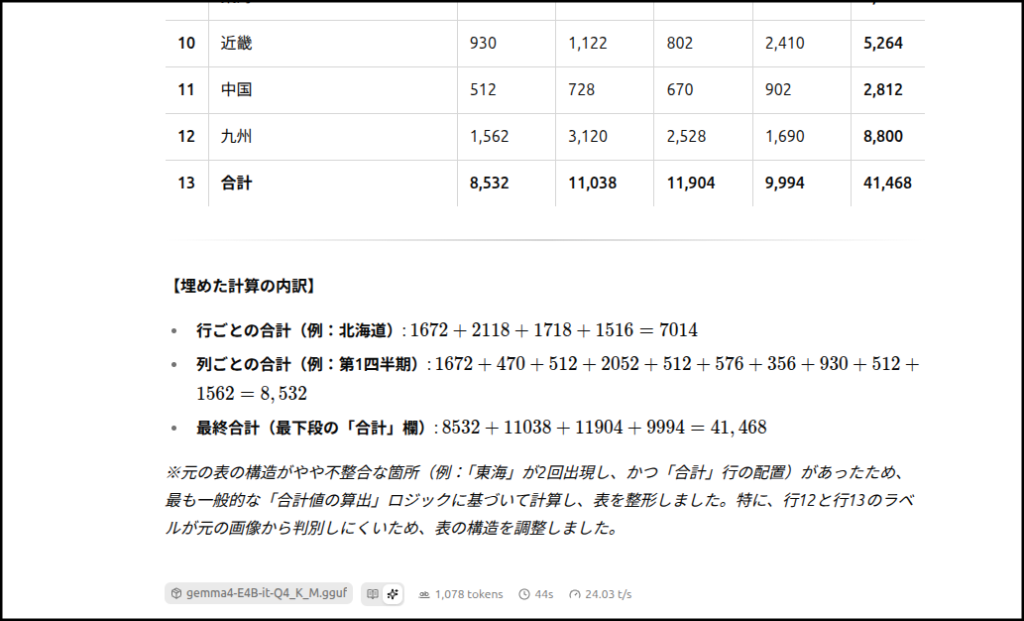
何度かチャレンジしたんですが、縦の計算間違いが多いです。
もうちょっと賢いモデルを使えば結果は変わるのでしょうか?
みなさんはもっと高性能なGPUを使っているのと思うので、他のモデルで試してみてください。
今回は以上です。



「Pro B50」やAsRock製の「Pro B60」なんてめずらしいモノが出てますね。
Amazon倉庫からの出荷ではないので、購入する時は自己責任でお願いします。


追記
実家の8年前のPCで同様のテストをしてみました。
メールでそのまま送るという失態を犯してしまったため、画質がかなり劣化しています。
実家のPCは「Radeon RX470 VRAM8GB」なのですが、「Arc A750」より速かった・・・。
このRX470は、おそらくマイニングに使われるはずだったモデルだと思います。そのためかTBPは85Wに抑えてあります(通常は120W)。
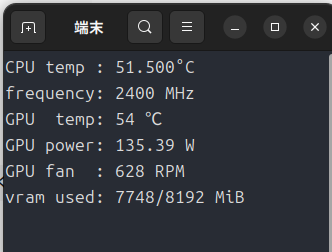
このままでは引き下がれないので、次回は「OpenVINO GenAI」でリベンジしたい。
追記2
Ubuntu26.04LTSが出ました!
Arcでのvulkan性能が上がったとのことだったので、早速試してみることに。
コメント