The RockでROCmをビルド(Ubuntu編)の記事でThe Rockを使ってROCmをビルドしていきました。
今回はこのROCmを使ってpytorchのビルドをやっていきます。
ただ、Ryzen9 7900無印の内蔵GPU(Raphael)はFlashAttentionに対応していません(自分の調べた限りでは)。
なのでAOTritonは偽装してスルーしています。
Ryzen8000GシリーズやRX7600(XT)はAOTritonも実装できるかもしれません。
自分は持っていないので試せていません。
それではやっていきましょう。
まずはtorchのビルド
The Rockのディレクトリの中で実行していきます。
前回のスクリプトでビルドした方は、
cd $HOME/install/TheRock
source venv/bin/activateでカレントディレクトリを移動し、仮想環境をアクティベートしてください。
次に「Gitの初期設定」をしておきましょう。
今回のビルドスクリプトにはPyTorchの中にあるNVIDIA用(CUDA)のコードを、AMD用(ROCm/HIP)に自動翻訳が終わった後、自動的に「Git」が今回の変更を保存(コミット)しようとするらしいです。
git config --global user.email "you@example.com"
git config --global user.name "Your Name"上記のように適当に登録しておいてください。
次に、今回torchをビルドするにあたって、Geminiにパッチを作ってもらいました。
import os
files = [
"aten/src/ATen/native/transformers/hip/attention_backward.hip",
"aten/src/ATen/native/transformers/hip/attention.hip"
]
dummy_code = """
#include <tuple>
namespace sdp {
namespace aotriton_adapter {
template <typename T1, typename T2>
inline std::tuple<int, int> parse_window_size(T1 a, T2 b) {
return std::make_tuple(0, 0);
}
}
}
"""
for f in files:
if os.path.exists(f):
with open(f, 'r') as file:
data = file.read()
# すでにパッチが当たっていなければ注入する
if "std::make_tuple(0, 0);" not in data:
with open(f, 'w') as file:
file.write(dummy_code + data)
print(f"Elegantly Patched: {f}")これを「patch_attention_elegant.py」として保存し、The Rockのフォルダの中に入れておいてください(なぜエレガントなのかはわかりませんが、Geminiのセンスなんでしょうか)。
以下はGeminiの解説からの引用ですが、このスクリプトは、「Flash AttentionをOFFにした場合」の分岐処理のミスをうまくごまかすためのものとのことです。
FlashAttentionが使える場合、このパッチは使う必要はありません。
ここからビルドに入ります。
# PyTorchのソースコードを取得し、TheRock互換バージョンに切り替え
python external-builds/pytorch/pytorch_torch_repo.py checkout
cd external-builds/pytorch/pytorch
# サブモジュールの同期
git submodule update --init --recursive
# 必要なPythonパッケージのインストール
pip install -r requirements.txt
pip install cmake ninja typing_extensions mkl mkl-include
#特定のスクリプトにパッチを当てる(flashattentionがサポートされていない場合)
python patch_attention_elegant.py
# 変数セット
export ROCM_PATH=$HOME/install/TheRock/build/dist/rocm
export PATH=$ROCM_PATH/bin:$ROCM_PATH/llvm/bin:$PATH
export PKG_CONFIG_PATH=$ROCM_PATH/lib/pkgconfig:$ROCM_PATH/share/pkgconfig:$ROCM_PATH/lib/rocm_sysdeps/lib/pkgconfig:$ROCM_PATH/lib/rocm_sysdeps/share/pkgconfig:$PKG_CONFIG_PATH
# C++とCのコンパイラをUbuntu標準の「gcc/g++」に設定
export CC=gcc
export CXX=g++
# CMakeには「GPU用(HIP)のコンパイラだけTheRockを使うように」と指示
export CMAKE_ARGS="-DROCM_PATH=$ROCM_PATH -DCMAKE_HIP_COMPILER=$ROCM_PATH/bin/hipcc -DUSE_FLASH_ATTENTION=OFF"
# その他の設定群
export PYTORCH_ROCM_ARCH="gfx1036;gfx1100" #どうしてもFlashAttentionを使おうとするので、ダミーで「gfx1100」を指定しています
export USE_ROCM=1
export USE_CUDA=0
export USE_XPU=0
export USE_KINETO=0
export USE_FLASH_ATTENTION=0 #gfx110xなら不要
export USE_MEM_EFF_ATTENTION=0 #gfx110xなら不要
export BUILD_TEST=0
export CMAKE_BUILD_PARALLEL_LEVEL=24 #この数値は使っているCPUのスレッド数に合わせてください
export MAX_JOBS=24 #この数値は使っているCPUのスレッド数に合わせてください
# .whlの作成
python setup.py bdist_wheel 2>&1 | tee build_pytorch.log
「$HOME/install/TheRock/external-builds/pytorch/pytorch/dist」に「whlファイル」が出来上がっているはずです。
torchvisionのビルド
torchの時と同様に、The Rockのディレクトリで仮想環境をアクティベート。
一つ前のディレクトリに戻ります。
先程ビルドしたtorchを仮想環境にインストールし、torchvisionのビルドに入ります。
cd ~/install/TheRock
source venv/bin/activate
cd ../
#torchvisionのソースをクローン
git clone https://github.com/pytorch/vision.git torchvision-source
cd torchvision-source
pip install setuptools wheel
#ビルドしたtorchをインストール(ディレクトリをいじっていなければこのパスでとおるはずです)
pip install $HOME/install/TheRock/external-builds/pytorch/pytorch/dist/torch*.whl
# ROCm等パスを通す
export LD_LIBRARY_PATH=$HOME/install/TheRock/build/dist/rocm/lib/rocm_sysdeps/lib:$HOME/install/TheRock/build/dist/rocm/lib:$LD_LIBRARY_PATH
export ROCM_PATH=$HOME/install/TheRock/build/dist/rocm
export PATH=$ROCM_PATH/bin:$ROCM_PATH/llvm/bin:$PATH
export CC=gcc
export CXX=g++
# ROCm用に指定
export USE_ROCM=1
# ビルド開始
python setup.py bdist_wheel
torchaudioのビルド
torchの時と同様に、The Rockのディレクトリで仮想環境をアクティベート。
一つ前のディレクトリに戻ります。
先程ビルドしたtorchを仮想環境にインストールし、torchaudioのビルドに入ります。
cd ~/install/TheRock
source venv/bin/activate
cd ../
#torchaudioのソースをクローン
git clone https://github.com/pytorch/audio.git torchaudio-source
cd torchaudio-source
pip install setuptools wheel
pip install soundfile
#ビルドしたtorchをインストール(すでにインストールしてある場合は不要)
pip install $HOME/install/TheRock/external-builds/pytorch/pytorch/dist/torch*.whl
# パスを通す
export LD_LIBRARY_PATH=$HOME/install/TheRock/build/dist/rocm/lib/rocm_sysdeps/lib:$HOME/install/TheRock/build/dist/rocm/lib:$LD_LIBRARY_PATH
export ROCM_PATH=$HOME/install/TheRock/build/dist/rocm
export PATH=$ROCM_PATH/bin:$ROCM_PATH/llvm/bin:$PATH
export CC=gcc
export CXX=g++
# ROCm用に指定
export USE_ROCM=1
# ビルド開始
python setup.py bdist_wheel
ビルドしたファイルの利用方法
今回は「ComfyUI」を例にインストールしてみます。
cd ~/install
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
#仮想環境の構築
python3 -m venv venv
source venv/bin/activateここから先程ビルドしたpytorchをインストールしていきます。
特にファイルをいじっていなければ、パスは以下でとおるはずです。
pip install $HOME/install/TheRock/external-builds/pytorch/pytorch/dist/torch*.whl
pip install $HOME/install/torchvision-source/dist/torchvision*.whl
pip install $HOME/install/torchaudio-source/dist/torchaudio*.whl
pip install mkl numpy
sudo usermod -aG video $USER
sudo usermod -aG render $USERここまでインストールしたら、システムを一度再起動しましょう。
ROCmのパスを指定してComfyUIを起動
再起動したと思うので、ComfyUIに移動して仮想環境をアクティベート。
cd ~/install/ComfyUI
source venv/bin/activate次に最初にThe RockでビルドしたROCmのパスの指定
# ROCmのパス
export ROCM_PATH=/home/test/install/TheRock/build/dist/rocm
# ライブラリ(.soファイル)を探すパスを追加
export LD_LIBRARY_PATH=$ROCM_PATH/lib/rocm_sysdeps/lib:$LD_LIBRARY_PATHあとはいつもどおりrequirements.txtをインストールして「ComfyUI」を起動するんですが、そのままだとcuda用のpytorchを再インストールされるので、ちょっといじってから実行します。
# --- requirements.txt の不要行を削除 ----------------------
# 念の為バックアップ作成
cp requirements.txt requirements_backup.txt
# 特定行削除(torch, torchvision, torchaudio)
sed -i -e '/^torch$/d' \
-e '/^torchvision$/d' \
-e '/^torchaudio$/d' requirements.txt
#改めてrequirements.txtをインストール
pip install -r requirements.txt
#ComfyUIを起動
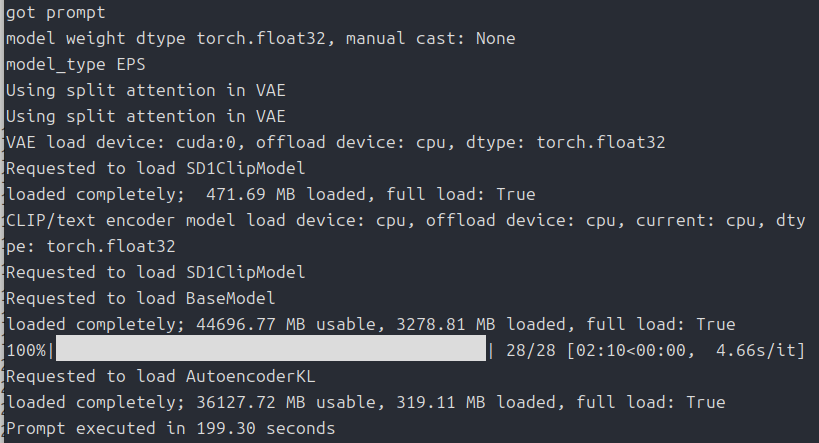
python main.py --auto-launch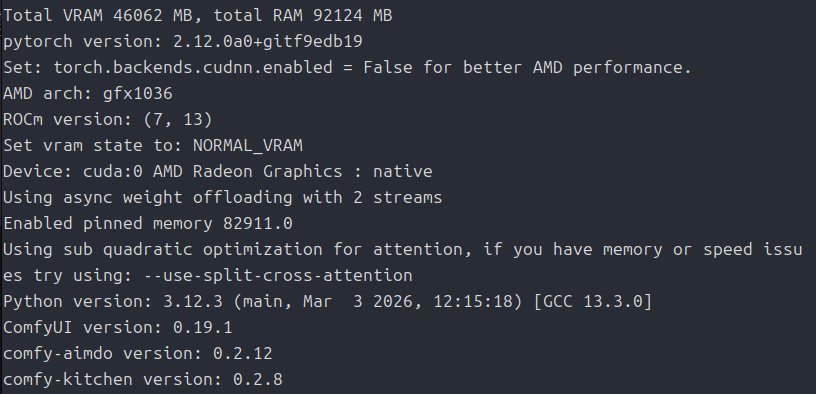
さらに、生成される画像は真っ黒ばかり。
たまにアスカらしきものが生成されますが、なんかちょっと変です。
そこで、
python main.py --auto-launch --force-fp32 --fp32-text-enc起動オプションを上のように変更することで状況が一変。
真っ黒画像になることなく、うまく画像生成できるようになりました。
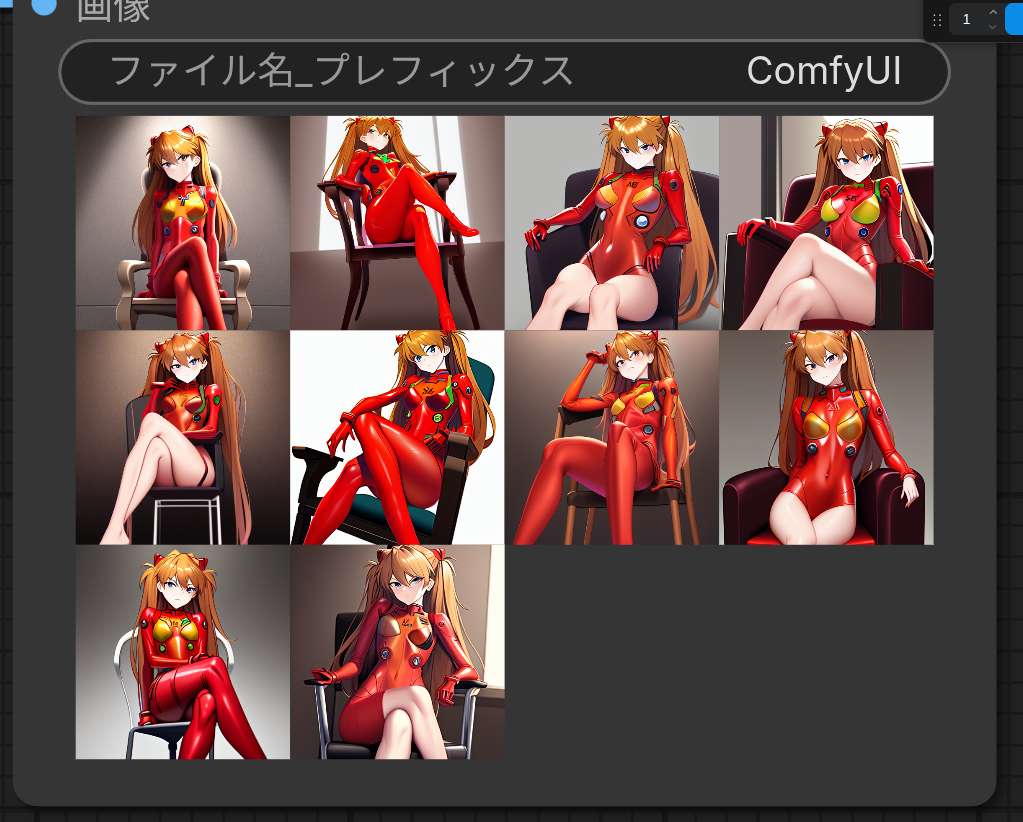

最後に
fp32への変更は、以前は「–nohalf」みたいなオプションで実現できていたので、別に特別なことではないです。
とりあえず、自力でビルドした環境で、推論できたよって話でした。
今回は、以上です。
コメント