Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。
前回の記事「話題のgemma-4を試してみた」で、llama.cppをvulkanで動かしたら「Radeon RX 470」に「Intel Arc A750」が負けたという内容を書きました(主旨は違いますが)。
今回はOpenVINO GenAIでリベンジしたいと思います。
https://openvinotoolkit.github.io/openvino.genai
https://github.com/openvinotoolkit/openvino.genai
「Arc A750」でも十分動作しましたので、大抵のArcなら大丈夫でしょう。
ちなみに今回の記事内容はIntel Arcでしか動かないと思います。
それでは、やっていきます。
モデルファイル
OpenVINO GenAIはsafetensorsやggufは使えません。
独自の形式に変換する必要があります。

OpenVINO (OpenVINO Toolkit)
Deep Learning Inference, Deep Learning Model Optimization
上のリンクからダウンロードできるようです。
safetensorsを変換する場合は以下のリンクが使えるらしいです(自分は使ってません)。

OpenVINO Export – a Hugging Face Space by OpenVINO
Provide the model ID from the Hugging Face Hub and select if the new repository should be private or overwrite existing …

NNCF quantization – a Hugging Face Space by OpenVINO
This application allows you to convert and quantize machine learning models to the OpenVINO format, making them more eff…
自力で変換する場合は、
#!/bin/bash
uv venv .venv_trans --python /usr/bin/python3
source .venv_trans/bin/activate
uv pip install openvino-genai optimum[openvino] datasets
MODEL="Qwen/Qwen3-8B"
QUANTUM="int4"
DIR_NAME=$(basename "$MODEL")
optimum-cli export openvino --model "$MODEL" --weight-format "$QUANTUM" ./models/"$DIR_NAME"-"$QUANTUM"
こんな感じで変換できます(結構時間がかかる)。
今回は、以下のリンクのすでに変換されたモデルを使います。

OpenVINO/Qwen3-8B-int4-cw-ov · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
ダウンロード方法は前回の記事を参考にしてください。
OpenVINO GenAI導入
OpenVINO GenAIを使ったローカルLLMのチャットは、自力で環境構築しなくてはなりません。
興味があったのでチャレンジしてみました。(まぁほとんどGeminiがやってくれましたが)。
GitHub – toaru-ubuntu/OpenVINO_GenAI_test
Contribute to toaru-ubuntu/OpenVINO_GenAI_test development by creating an account on GitHub.
githubに上げてます。
テストするためだけのものなので、非常に簡易的です。
#!/bin/bash
mkdir -p ~/install
cd ~/install
git clone https://github.com/toaru-ubuntu/OpenVINO_GenAI_test.git
cd OpenVINO_GenAI_test
python3 -m venv venv
source ./venv/bin/activate
pip install openvino-genai optimum[openvino]
#OpenVINO_GenAIをサーバーとして起動するのに必要なライブラリ等
pip install fastapi uvicorn pydantic openai gradio
 実行するとこんな感じでインストールが終了します。
実行するとこんな感じでインストールが終了します。
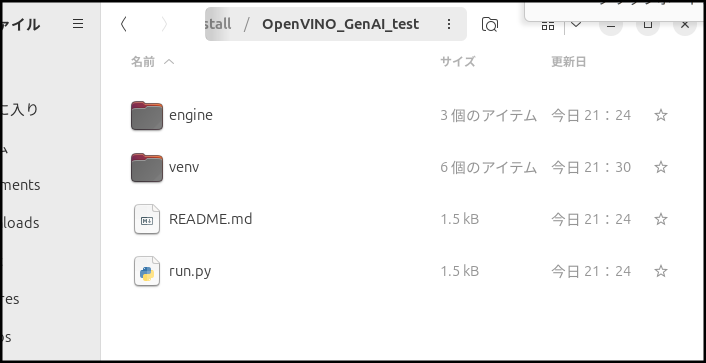 出来上がったフォルダの中身。ここにモデルファイルを配置します。
出来上がったフォルダの中身。ここにモデルファイルを配置します。
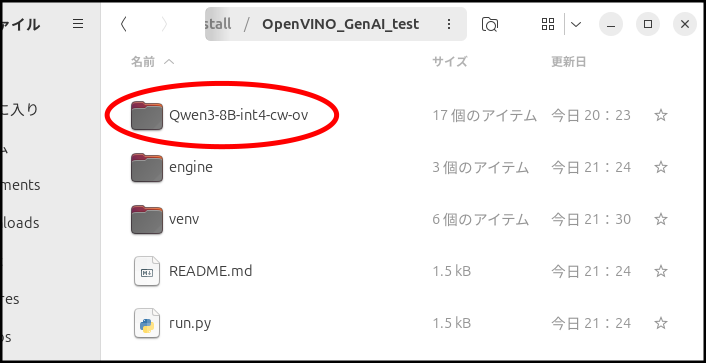 こんな感じで配置。
こんな感じで配置。
これで準備は完了です。
いざ、実行
 先程終了した状態で「python run.py」を実行。
先程終了した状態で「python run.py」を実行。
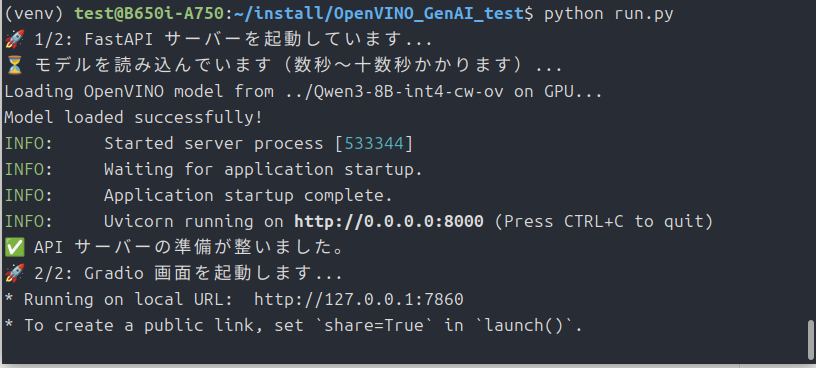
 ごめんなさい、以前の記事のpythonファイルを流用しているので「vLLM」って表示されちゃいます。
動作テストの動画です。前回の記事とは比較にならない速度。
ごめんなさい、以前の記事のpythonファイルを流用しているので「vLLM」って表示されちゃいます。
動作テストの動画です。前回の記事とは比較にならない速度。
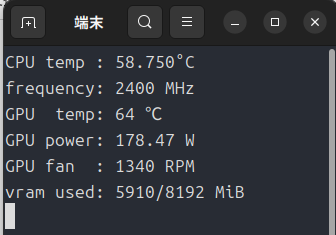 負荷状況。VRAMにはずいぶん余裕があります。
負荷状況。VRAMにはずいぶん余裕があります。
A380でもギリ動くかもしれませんが、コンテキスト長を増やすとエラーになるかもしれません。
最後に
よく見たらモデルファイルが「gemma-4」じゃないじゃん!と思ったそこのあなた。
そのとおりです、ごめんなさい。
gemma-4はまだOpenVINO GenAIには対応しておりません。
変換されたモデルもあるし、強引に動かすこともできるのですが全然パフォーマンス出ません。
対応しているなるべく新しいモデルないかなぁって探したのが今回のQwen3-8B-int4-cw-ovです。
OpenVINOに対応するにはもう少し時間がかかるみたいで。
このへんllama.cppは有利です。
Radeonを使っている方、素直にllama.cpp + vulkan で動かしましょう。
まぁ普通はollamaかLMStudioだと思いますけど。
今回は以上です。
追記
モデルファイルを変更したい場合、「engine/main.py」の
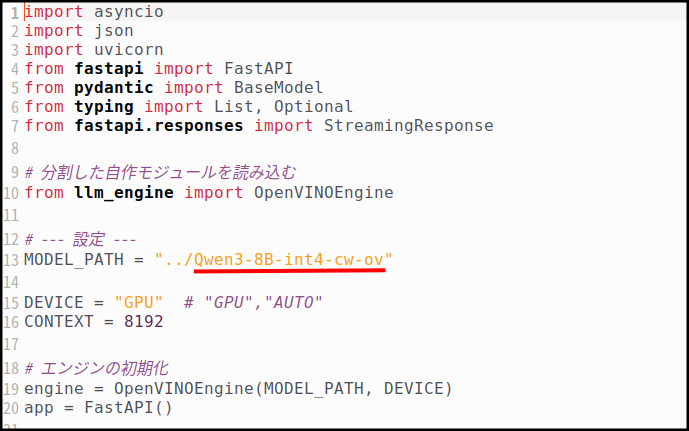 アンダーラインの部分を該当のファイル名に書き直してください。もちろんモデルはダウンロードし直しです。
アンダーラインの部分を該当のファイル名に書き直してください。もちろんモデルはダウンロードし直しです。

Amazon | 玄人志向 Intel Arc B580 搭載 グラフィックボード GDDR6 12GB 【国内正規代理店品】 AR-B580D6-E12GB/DF | 玄人志向 | グラフィックボード 通販
玄人志向 Intel Arc B580 搭載 グラフィックボード GDDR6 12GB 【国内正規代理店品】 AR-B580D6-E12GB/DFがグラフィックボードストアでいつでもお買い得。当日お急ぎ便対象商品は、当日お届け可能です。アマ...

Amazon | ASUS AMD Dual Radeon RX 9060 XT 16GB GDDR6ビデオカード DUAL-RX9060XT-16G 国内正規代理店品 | ASUS | グラフィックボード 通販
ASUS AMD Dual Radeon RX 9060 XT 16GB GDDR6ビデオカード DUAL-RX9060XT-16G 国内正規代理店品がグラフィックボードストアでいつでもお買い得。当日お急ぎ便対象商品は、当日お届け可能です。...

Palit RTX 5060 Ti 16GB GDDR7 PCIe 5.0 グラフィックボード
Palit(パリット) GeForce RTX 5060 Ti Infinity 3 16GB / NE7506T019T1-GB2061S / グラフィックボードがグラフィックボードストアでいつでもお買い得。当日お急ぎ便対象商品は、当日お...

Amazon | ASRock Intel Arc Pro B60 Creator 24GB グラフィックスカード、Intel Xe2-HPGアーキテクチャ、24GB GDDR6、PCIe 5.0、4X DisplayPort 2.1、ブロワーデザイン、0dBサイレント冷却。 | ASRock | グラフィックボード 通販
ASRock Intel Arc Pro B60 Creator 24GB グラフィックスカード、Intel Xe2-HPGアーキテクチャ、24GB GDDR6、PCIe 5.0、4X DisplayPort 2.1、ブロワーデザイン、0d...

Amazon | Intel 33P6PEB0BB Arc Pro B50 16GB ビデオカード。 | インテル | グラフィックボード 通販
Intel 33P6PEB0BB Arc Pro B50 16GB ビデオカード。がグラフィックボードストアでいつでもお買い得。当日お急ぎ便対象商品は、当日お届け可能です。アマゾン配送商品は、通常配送無料(一部除く)。
コメント