Amazonのアソシエイトとして、当ブログは適格販売により収入を得ています。
以前の記事で、外国語の動画の翻訳字幕を作る自作ソフトを紹介しました。
この時は「gpt-oss」で翻訳していました。
今回はQwen3.5シリーズを利用していきたいと思います。

こちらの「あわしろいくや氏」の記事を見て、llama.cppのsyclビルドで結構パフォーマンスがでることを知り、早速利用しようと思ったわけです。
自分が使っているArc Pro B60は、「VRAMが多いArc B580」なので、記事内容のB580と同じような速度が出せるはずです。
とりあえずllama.cppで動作テスト
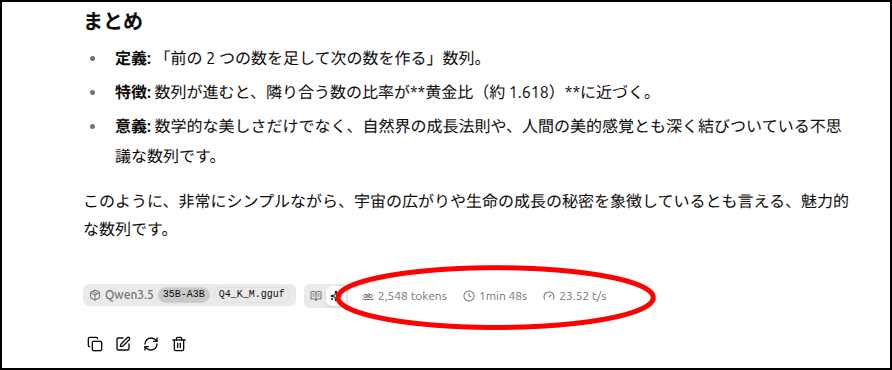
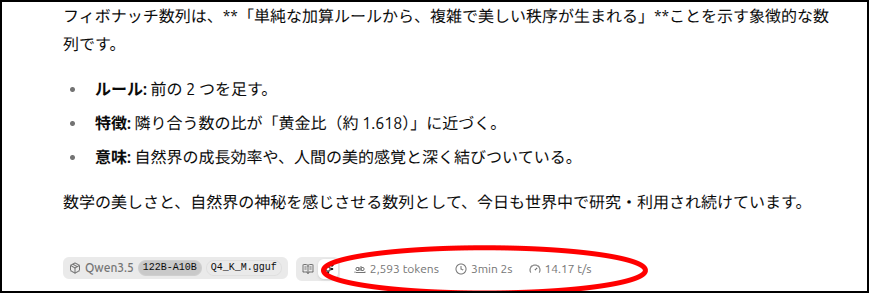
共に「Q4_K_M」に量子化しているモデルですが、ちゃんと答えてくれてます。
速度はまあまあといったところ。
ということで、このモデルを翻訳ソフトに導入してみました。
Qwen3.5をlangtrans_llamaに導入
基本的には以前の記事と同じです。
細かい導入手順は以前の記事を参考にしてください。
変更点だけこの記事で書いています。
- Intel Arcの場合
- Radeonの場合(Radeonの情報は古いので、各自で最新に置き換えて下さい)
- ROCmのインストール(この記事の「ROCmのインストール」を参照。ただし、ROCmが動作するRadeonは現在RDNA2以上(VEGAは?)だと思います)。
- ffmpegのインストール
GeForceの場合はわかりません。持ってないもので・・・。
インストールスクリプト
以下は、「Intel Arc用」です。Radeonの場合はpytorchの部分が違います。
Qwen3.5に対応するためには、最新のllama.cppが必要になります。
もし以前の環境を使っている場合は、すべて削除した後以下のスクリプトで再インストールして下さい。
#!/bin/bash
#インストールに必要なライブラリ等をインストール
sudo apt update
sudo apt install git
sudo apt install curl
sudo apt install build-essential cmake
#sudo apt install ffmpeg #自前でビルドした場合はこの行はコメントアウトしてください。
# uvをcurlでインストール
curl -LsSf https://astral.sh/uv/install.sh | sh
source $HOME/.local/bin/env
mkdir -p $HOME/install/langtrans_llama/input
mkdir -p $HOME/install/langtrans_llama/models
cd ~/install/langtrans_llama
#uvでpython3.12環境を作る
uv venv --python 3.12
source .venv/bin/activate
uv pip install openai requests huggingface_hub
#whisperをクローン
git clone https://github.com/openai/whisper.git
cd whisper
#Radeonの場合のpytorchのインストール
#uv pip install --pre torch torchvision --index-url https://download.pytorch.org/whl/nightly/rocm7.1
#torch.xpuのstable
uv pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/xpu
#whisperのセットアップ
uv pip install -U pip setuptools
uv pip install .
cd ../
#準備とllama.cppのクローン
sudo apt install -y cmake g++ libcurlpp-dev
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
#CPU用ビルド(ggufの変換で使う)
mkdir build-cpu
cmake -B build-cpu
cmake --build build-cpu --config Release -j$(nproc)
#sycl用ビルド
source /opt/intel/oneapi/setvars.sh
cmake -B build-sycl -DGGML_SYCL=ON -DCMAKE_C_COMPILER=icx -DCMAKE_CXX_COMPILER=icpx
cmake --build build-sycl --config Release -j$(nproc)
#vulkanビルド
sudo apt install -y libvulkan-dev glslc
cmake -B build-vulkan -DGGML_VULKAN=ON
cmake --build build-vulkan --config Release -j$(nproc)
以前の記事とは、ちょっと変更してます。
メインスクリプトの用意
以下のスクリプトを「qwen_langtrans_llama.py」という名前で保存して下さい。
import os
import sys
import subprocess
import time
import requests
import re
import torch
from openai import OpenAI
from pathlib import Path
from huggingface_hub import hf_hub_download
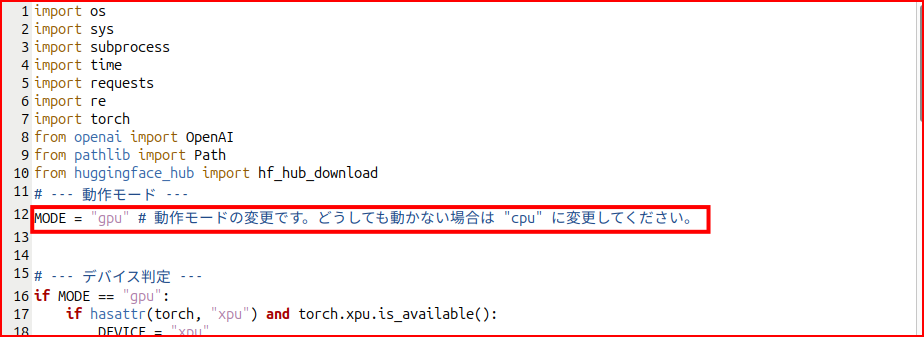
# --- 動作モード ---
MODE = "gpu" # 動作モードの変更です。どうしても動かない場合は "cpu" に変更してください。
# --- デバイス判定 ---
if MODE == "gpu":
if hasattr(torch, "xpu") and torch.xpu.is_available():
DEVICE = "xpu"
W_DEVICE = "xpu"
BACKEND = "sycl" # Arc GPU用
elif torch.cuda.is_available():
DEVICE = "cuda"
W_DEVICE = "cuda"
BACKEND = "vulkan"
else:
DEVICE = "cpu"
BACKEND = "cpu"
elif MODE == "cpu":
W_DEVICE = "cpu"
DEVICE = "cpu"
BACKEND = "cpu"
# ==========================================
# 設定変数(環境に合わせて調整してください)
# ==========================================
# --- 翻訳設定 ---
LANGUAGE = "日本語" #デフォルトは「日本語」です
BATCH_SIZE = 10 # 一回にまとめてLLMに渡す字幕の数。あまり多くすると翻訳ミスが多発します。
LIMIT = None # None に設定すると全件処理(デバッグ用)
MODEL = "local-model"
TEMPERATURE = 0.3
# --- whisperモデル ---
WHISPER_MODEL = "medium" #"tiny","base","small","medium","large","turbo"などから選んで下さい
#W_DEVICE = "cpu" # デバイス判定された値を上書きします
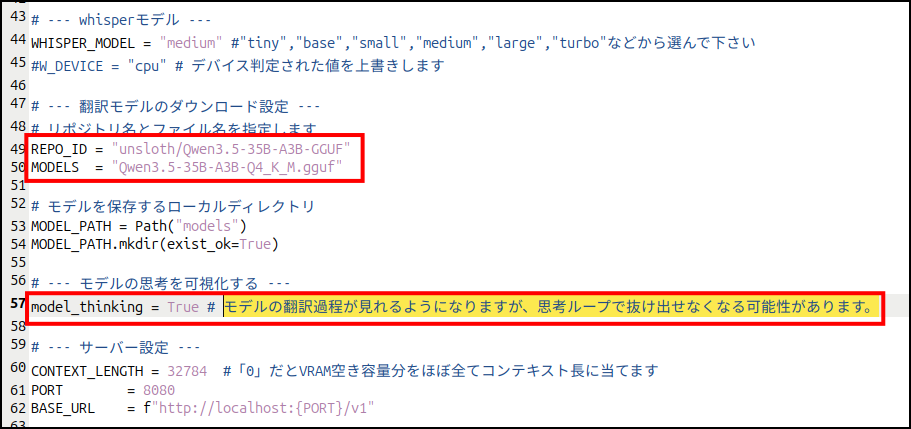
# --- 翻訳モデルのダウンロード設定 ---
# リポジトリ名とファイル名を指定します
REPO_ID = "unsloth/Qwen3.5-35B-A3B-GGUF"
MODELS = "Qwen3.5-35B-A3B-Q4_K_M.gguf"
# モデルを保存するローカルディレクトリ
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(exist_ok=True)
# --- モデルの思考を可視化する ---
model_thinking = False # モデルの翻訳過程が見れるようになりますが、思考ループで抜け出せなくなる可能性があります。
# --- サーバー設定 ---
CONTEXT_LENGTH = 32784 #「0」だとVRAM空き容量分をほぼ全てコンテキスト長に当てます
PORT = 8080
BASE_URL = f"http://localhost:{PORT}/v1"
#--- CPU,GPUの割当変数を初期化 ---
CPU_MOE = None
N_GPU_LAYERS = None
#--- もし必要なら適当な数値を入れて下さい ---
# VRAMとメインメモリの割当が自動になったみたいなので変数自体オミットしています。
# どうしても割り当てたい時にコメントアウトを削除して下さい。
#CPU_MOE = 33 # 「0」に設定すると、全てのレイヤーをGPUに乗せます
#N_GPU_LAYERS = 99 # 学習モデルをいくつGPUレイヤーに乗せるかの設定値
#===========================================
# 以下はスクリプト本体です
#===========================================
# モデルの自動ダウンロード関数
def prepare_model(repo_id, filename, local_dir):
print(f"--- モデルを確認中: {filename} ---")
try:
# local_dirを指定すると、そこにダウンロード・保存されます
# 既に存在する場合はダウンロードをスキップし、パスだけ返します
path = hf_hub_download(
repo_id=repo_id,
filename=filename,
local_dir=local_dir,
local_dir_use_symlinks=False # Windows/Linux両方で扱いやすくするため
)
print(f"モデルの準備完了: {path}")
return Path(path)
except Exception as e:
print(f"モデルのダウンロードに失敗しました: {e}")
sys.exit(1)
# モデルのフルパスを自動取得(ここでダウンロードが走ります)
full_path = prepare_model(REPO_ID, MODELS, MODEL_PATH)
# ファイルを取得
extensions = {".mp4", ".mkv", ".avi"}
FILE = next((p for p in Path("./input").iterdir() if p.suffix.lower() in extensions), None)
if FILE:
print(f"「{FILE.name}」が見つかりました。")
else:
print("inputフォルダの中に動画ファイルが見つかりません。")
sys.exit(1)
# パスの取得
temp_dir = Path(FILE.stem + "_temp")
temp_dir.mkdir(exist_ok=True)
audio_path = temp_dir / Path(FILE.stem + ".wav")
input_srt = temp_dir / Path(FILE.stem + ".srt")
translated_srt = temp_dir / Path(FILE.stem + "_translated.srt")
#===========================================
SERVER_BIN = f"./llama.cpp/build-{BACKEND}/bin/llama-server"
print(f"使用するバックエンド: {BACKEND}")
#===========================================
# 1. 動画から音声を抜き出す処理
def process_video(video_path):
print("--- 音声を抽出中 ---")
subprocess.run(["ffmpeg", "-y", "-i", str(video_path), "-vn", "-ac", "1", "-ar", "16000", str(audio_path), "-loglevel", "error"], check=True)
# 2. 音声からwhisperで文字起こしする処理(元のロジックに復元)
def run_whisper(audio_path, temp_dir):
print(f"--- Whisperで文字起こし中({W_DEVICE}) ---")
if W_DEVICE == "xpu":
subprocess.run([
"whisper", str(audio_path),
"--model", WHISPER_MODEL,
"--output_dir", str(temp_dir),
"--output_format", "srt",
"--device", "xpu"
], check=True)
else:
subprocess.run([
"whisper", str(audio_path),
"--model", WHISPER_MODEL,
"--output_dir", str(temp_dir),
"--output_format", "srt"
], check=True)
# 3. llama-serverの起動
def start_llama_server():
"""llama-serverを起動し、準備ができるまで待機する"""
if DEVICE == "cpu":
cmd = [
SERVER_BIN,
"-m", str(full_path),
"--port", str(PORT),
]
else:
cmd = [
SERVER_BIN,
"-m", str(full_path),
"--port", str(PORT),
"-c", str(CONTEXT_LENGTH),
]
if not CPU_MOE is None:
cmd.extend([
"--n-cpu-moe", str(CPU_MOE)
])
if not N_GPU_LAYERS is None:
cmd.extend([
"-ngl", str(N_GPU_LAYERS)
])
if model_thinking:
cmd.extend([
"--reasoning", "on"
])
else:
cmd.extend([
"--reasoning", "off"
])
print(f"llama-server を起動中: {' '.join(cmd)}")
process = subprocess.Popen(cmd, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
#process = subprocess.Popen(cmd, stdout=None, stderr=None)
print("サーバーの準備完了を待っています...", end="", flush=True)
max_retries = 90
for i in range(max_retries):
try:
response = requests.get(f"http://localhost:{PORT}/health", timeout=5)
if response.status_code == 200:
print("\nサーバー準備完了!")
return process
except requests.exceptions.ConnectionError:
pass
print(".", end="", flush=True)
time.sleep(1)
process.terminate()
raise TimeoutError("\nサーバーの起動がタイムアウトしました。")
# 4. LLMによる翻訳処理
def translate_batch(client, batch_data):
system_prompt = (
f"あなたはプロの映像翻訳家です。提供されたテキストを英語から{LANGUAGE}に翻訳してください。\n"
"【字幕データの作成ルール】\n"
f" 渡された{BATCH_SIZE}行の英文を、文脈を考慮して自然な{LANGUAGE}に翻訳し、同じく{BATCH_SIZE}行になるように分割してください。\n"
"1. 出力は『インデックス番号: 翻訳文』というシンプルな形式に統一してください。\n"
"2. インデックス番号を 絶対に変更せず、入力された数字(例: 41, 42...)をそのまま維持 してください。1から振り直すことは厳禁です。\n"
"3. 字幕ファイルに直接結合するため、挨拶、解説、タイムスタンプ等の情報は不要です。\n"
"4. 翻訳完了後、入力と出力の行数が一致しているか内部で確認してください。\n"
"5. 視聴者に語りかけるような親しみやすい丁寧語(です・ます調)を使って下さい。\n"
"6. 英文が途中で途切れている場合は、翻訳文の最初の句読点で分割してください。\n"
"\n"
"【出力フォーマット例】\n"
"1: 最近のITXケース事情について話しましょう。\n"
"2: この小さなポンプが秘密兵器です。"
)
prompt_content = "\n".join([f"{d['index']}: {d['text']}" for d in batch_data])
api_params = {
"model": MODEL,
"messages": [
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt_content}
],
"temperature": 0.3,
"top_p": 0.90,
"frequency_penalty": 0.2,
"presence_penalty": 0.1,
"stream": True
}
try:
response = client.chat.completions.create(**api_params)
# 思考内容と翻訳結果を別々に管理する
reasoning_log = ""
translation_result = ""
print("\n--- 思考・翻訳中 ---")
for chunk in response:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="", flush=True)
reasoning_log += reasoning # ログとして貯める(字幕には使わない)
content = delta.content
if content:
print(content, end="", flush=True)
translation_result += content # これだけを字幕用にする
print("\n-------------------\n")
# --- 思考ログをファイルに記録 ---
# 動画名とバッチ範囲を添えて保存します
log_file = temp_dir / "reasoning_history.log"
with open(log_file, "a", encoding="utf-8") as f:
start_idx = batch_data[0]['index']
end_idx = batch_data[-1]['index']
f.write(f"========== Batch {start_idx} - {end_idx} ==========\n")
f.write(f"Timestamp: {time.strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write(f"Reasoning:\n{reasoning_log}\n")
f.write(f"Final Translation:\n{translation_result.strip()}\n")
f.write("="*50 + "\n\n")
# 翻訳結果(translation_result)だけを返す
return translation_result.strip()
except Exception as e:
print(f" [!] エラー: {e}")
return None
def input_srt_translate(input_srt, translated_srt):
if not os.path.exists(input_srt):
print("エラー: 字幕ファイルが見つかりません。")
return
client = OpenAI(base_url=BASE_URL, api_key="sk-no-key-required")
with open(input_srt, 'r', encoding='utf-8') as f:
content = f.read()
raw_blocks = [b.strip() for b in re.split(r'\n\s*\n', content.strip()) if b.strip()]
parsed_data = []
for block in raw_blocks:
lines = block.split('\n')
if len(lines) >= 3:
idx = lines[0].strip()
timestamp = lines[1].strip()
text = " ".join([l.strip() for l in lines[2:]])
parsed_data.append({"index": idx, "timestamp": timestamp, "text": text})
if not parsed_data:
print("エラー: 有効な字幕データがありません。")
return
detected_limit = int(parsed_data[-1]["index"])
final_limit = LIMIT if LIMIT is not None else detected_limit
print(f"--- 翻訳開始 ({LANGUAGE}) ---")
target_data = [d for d in parsed_data if int(d["index"]) <= final_limit]
translated_srt_blocks = []
for i in range(0, len(target_data), BATCH_SIZE):
batch = target_data[i : i + BATCH_SIZE]
current_range = f"{i+1}~{min(i + BATCH_SIZE, len(target_data))}"
print(f"[{current_range} / {len(target_data)}] 処理中...")
result_text = translate_batch(client, batch)
translated_dict = {}
if result_text:
#matches = re.findall(r'^(\d+)[::]\s*(.*)', result_text, flags=re.MULTILINE)
matches = re.findall(r'^(\d+)[::]\s*([\s\S]*?)(?=^\d+[::]|\Z)', result_text, flags=re.MULTILINE)
for match_idx, match_text in matches:
translated_dict[match_idx] = match_text.strip()
for item in batch:
idx = item["index"]
timestamp = item["timestamp"]
trans_text = translated_dict.get(idx, item["text"])
srt_block = f"{idx}\n{timestamp}\n{trans_text}"
translated_srt_blocks.append(srt_block)
with open(translated_srt, 'w', encoding='utf-8') as f:
f.write("\n\n".join(translated_srt_blocks) + "\n")
print("--- 完了! 翻訳した字幕を出力しました ---")
# 5. 動画と字幕の結合
def Combining_srt_an_video(video_path, srt_path, server_process, temp_dir):
try:
output_path = Path(f"{temp_dir}") / f"{Path(video_path).stem}_subtitled.mp4"
print(f"--- 字幕と動画を結合中 ---")
if LANGUAGE == "日本語":
lang_code, title = "jpn", "Japanese"
else:
lang_code, title = "xxx", "Translated"
cmd = [
"ffmpeg", "-y", "-fflags", "+genpts",
"-i", str(FILE),
"-i", str(srt_path),
"-c", "copy",
"-c:s", "mov_text",
"-map", "0:v",
"-map", "0:a",
"-map", "1:0",
"-metadata:s:s:0", f"language={lang_code}",
"-metadata:s:s:0", f"title={title}",
str(output_path),
"-loglevel", "error"
]
try:
subprocess.run(cmd, check=True)
print("--- 結合完了 ---")
except subprocess.CalledProcessError as e:
print(f"結合エラー: {e}")
finally:
if server_process:
print("\nサーバーを停止しています...")
server_process.terminate()
try:
server_process.wait(timeout=10)
except subprocess.TimeoutExpired:
print("応答がないため強制終了します...")
server_process.kill()
server_process.wait()
print("サーバーを正常に終了しました。")
if __name__ == "__main__":
if FILE:
# --- 追加:字幕ファイルが既に存在するかチェック ---
if input_srt.exists():
print(f"「{input_srt.name}」が既に存在するため、音声抽出とWhisperの処理をスキップします。")
else:
process_video(FILE)
run_whisper(audio_path, temp_dir)
# ------------------------------------------------
server_process = None
try:
server_process = start_llama_server()
input_srt_translate(input_srt, translated_srt)
Combining_srt_an_video(FILE, translated_srt, server_process, temp_dir)
except Exception as e:
print(f"予期せぬエラーが発生しました: {e}")
if server_process:
server_process.terminate()起動コマンド
以下を「run.sh」で保存。
#!/bin/bash
source /opt/intel/oneapi/setvars.sh
source .venv/bin/activate
# メインのPythonスクリプトを起動
python qwen_langtrans_llama.py上記は以前の記事にはなかったものですが、個人的に「source /opt/intel/oneapi/setvars.sh」の付け忘れが多かったため、最近はこんな感じで起動スクリプトを作っています。
モデルのダウンロード
モデルのダウンロードは自動になりました。
起動方法
ターミナルを起動して
bash ./run.shです。
最後に
ダウンロードするモデルを選ぶには、「qwen_langtrans_llama.py」の中身を書き換える必要があります。
ちょっと、とっつきにくいですよね。
次の記事でgradio版を出すつもりです。
Qwen3.5には「thinkingモード」があります。
こちらの方が翻訳の質はあがるのですが、思考ループに陥る可能性が非常に大きいため「–reasoning off」で思考しないようにしています。
あと、グラフィックスカードを持っていない人のために「CPUモード」を追加しました。
どうしても動かしたい人は使って下さい。
今回は以上です。




コメント